 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-regulated convolutional neural network for classifying variable stars
May 20, 2025Over the last two decades, machine learning models have been widely applied and have proven effective in classifying variable stars, particularly with the adoption of deep learning architectures such as convolutional neural networks, recurrent neural networks, and transformer models. While these models have achieved high accuracy, they require high-quality, representative data and a large number of labelled samples for each star type to generalise well, which can be challenging in time-domain surveys. This challenge often leads to models learning and reinforcing biases inherent in the training data, an issue that is not easily detectable when validation is performed on subsamples from the same catalogue. The problem of biases in variable star data has been largely overlooked, and a definitive solution has yet to be established. In this paper, we propose a new approach to improve the reliability of classifiers in variable star classification by introducing a self-regulated training process. This process utilises synthetic samples generated by a physics-enhanced latent space variational autoencoder, incorporating six physical parameters from Gaia Data Release 3. Our method features a dynamic interaction between a classifier and a generative model, where the generative model produces ad-hoc synthetic light curves to reduce confusion during classifier training and populate underrepresented regions in the physical parameter space. Experiments conducted under various scenarios demonstrate that our self-regulated training approach outperforms traditional training methods for classifying variable stars on biased datasets, showing statistically significant improvements.
Informative regularization for a multi-layer perceptron RR Lyrae classifier under data shift
Mar 12, 2023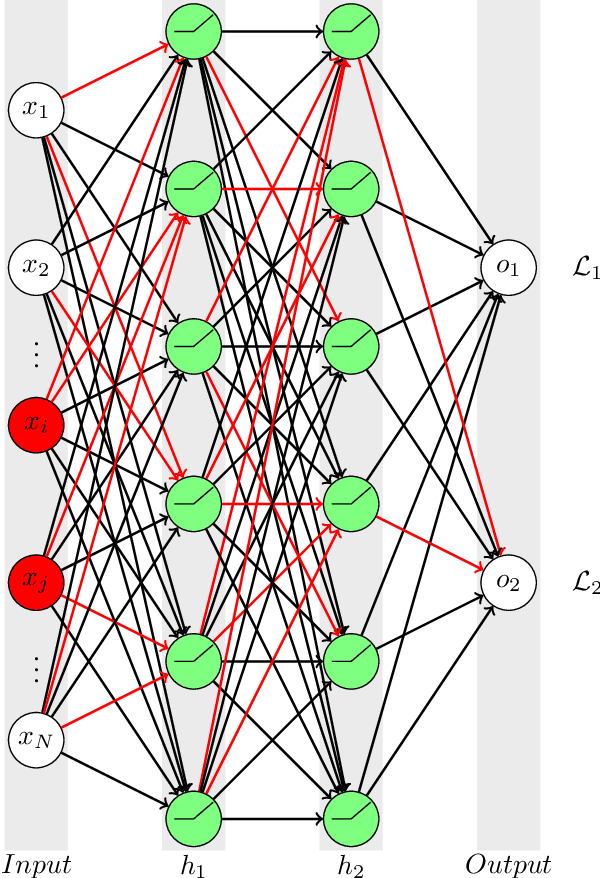
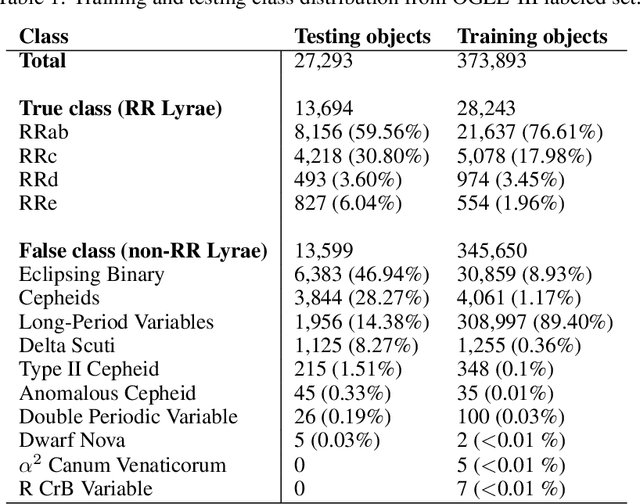
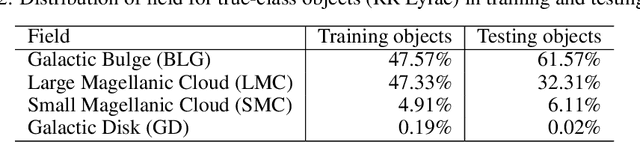
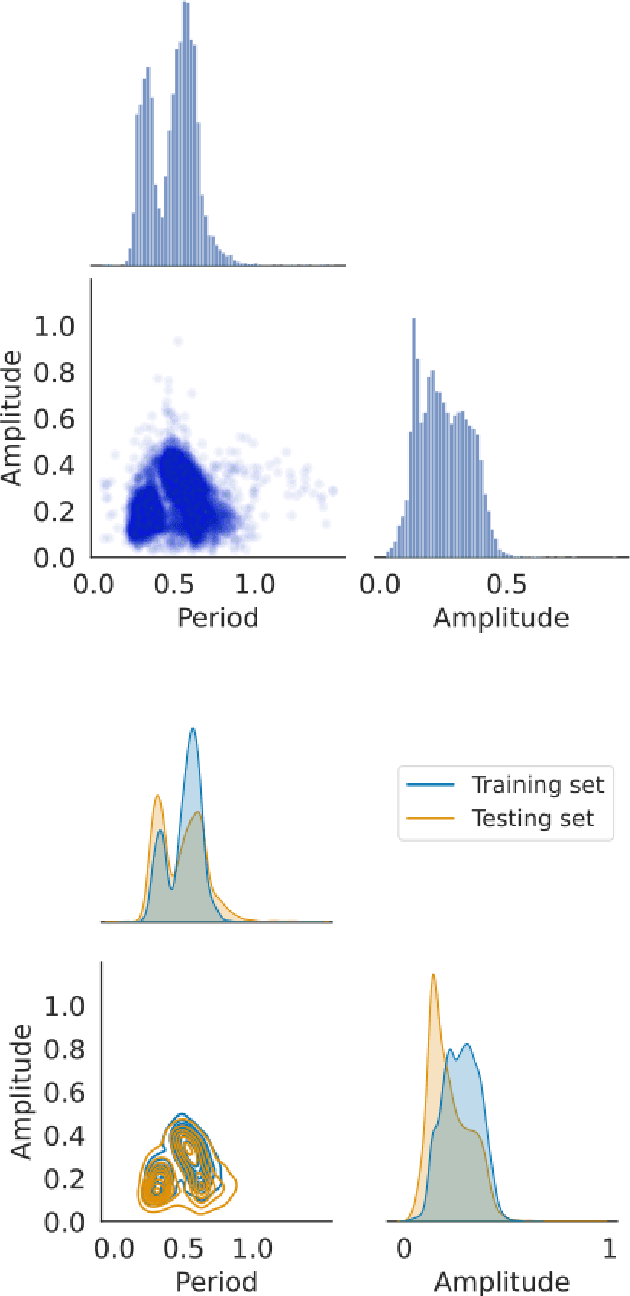
In recent decades, machine learning has provided valuable models and algorithms for processing and extracting knowledge from time-series surveys. Different classifiers have been proposed and performed to an excellent standard. Nevertheless, few papers have tackled the data shift problem in labeled training sets, which occurs when there is a mismatch between the data distribution in the training set and the testing set. This drawback can damage the prediction performance in unseen data. Consequently, we propose a scalable and easily adaptable approach based on an informative regularization and an ad-hoc training procedure to mitigate the shift problem during the training of a multi-layer perceptron for RR Lyrae classification. We collect ranges for characteristic features to construct a symbolic representation of prior knowledge, which was used to model the informative regularizer component. Simultaneously, we design a two-step back-propagation algorithm to integrate this knowledge into the neural network, whereby one step is applied in each epoch to minimize classification error, while another is applied to ensure regularization. Our algorithm defines a subset of parameters (a mask) for each loss function. This approach handles the forgetting effect, which stems from a trade-off between these loss functions (learning from data versus learning expert knowledge) during training. Experiments were conducted using recently proposed shifted benchmark sets for RR Lyrae stars, outperforming baseline models by up to 3\% through a more reliable classifier. Our method provides a new path to incorporate knowledge from characteristic features into artificial neural networks to manage the underlying data shift problem.
Bayesian Reconstruction of Fourier Pairs
Nov 09, 2020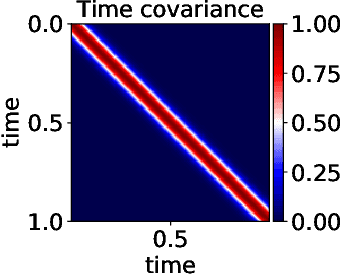



In a number of data-driven applications such as detection of arrhythmia, interferometry or audio compression, observations are acquired indistinctly in the time or frequency domains: temporal observations allow us to study the spectral content of signals (e.g., audio), while frequency-domain observations are used to reconstruct temporal/spatial data (e.g., MRI). Classical approaches for spectral analysis rely either on i) a discretisation of the time and frequency domains, where the fast Fourier transform stands out as the \textit{de facto} off-the-shelf resource, or ii) stringent parametric models with closed-form spectra. However, the general literature fails to cater for missing observations and noise-corrupted data. Our aim is to address the lack of a principled treatment of data acquired indistinctly in the temporal and frequency domains in a way that is robust to missing or noisy observations, and that at the same time models uncertainty effectively. To achieve this aim, we first define a joint probabilistic model for the temporal and spectral representations of signals, to then perform a Bayesian model update in the light of observations, thus jointly reconstructing the complete (latent) time and frequency representations. The proposed model is analysed from a classical spectral analysis perspective, and its implementation is illustrated through intuitive examples. Lastly, we show that the proposed model is able to perform joint time and frequency reconstruction of real-world audio, healthcare and astronomy signals, while successfully dealing with missing data and handling uncertainty (noise) naturally against both classical and modern approaches for spectral estimation.
MPCC: Matching Priors and Conditionals for Clustering
Aug 21, 2020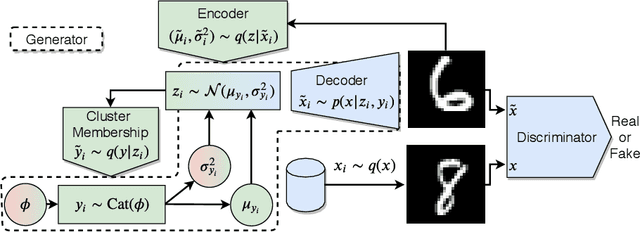


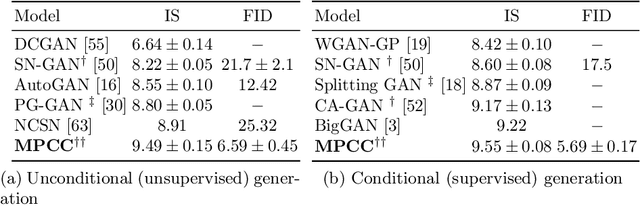
Clustering is a fundamental task in unsupervised learning that depends heavily on the data representation that is used. Deep generative models have appeared as a promising tool to learn informative low-dimensional data representations. We propose Matching Priors and Conditionals for Clustering (MPCC), a GAN-based model with an encoder to infer latent variables and cluster categories from data, and a flexible decoder to generate samples from a conditional latent space. With MPCC we demonstrate that a deep generative model can be competitive/superior against discriminative methods in clustering tasks surpassing the state of the art over a diverse set of benchmark datasets. Our experiments show that adding a learnable prior and augmenting the number of encoder updates improve the quality of the generated samples, obtaining an inception score of 9.49 $\pm$ 0.15 and improving the Fr\'echet inception distance over the state of the art by a 46.9% in CIFAR10.
An Information Theory Approach on Deciding Spectroscopic Follow Ups
Nov 06, 2019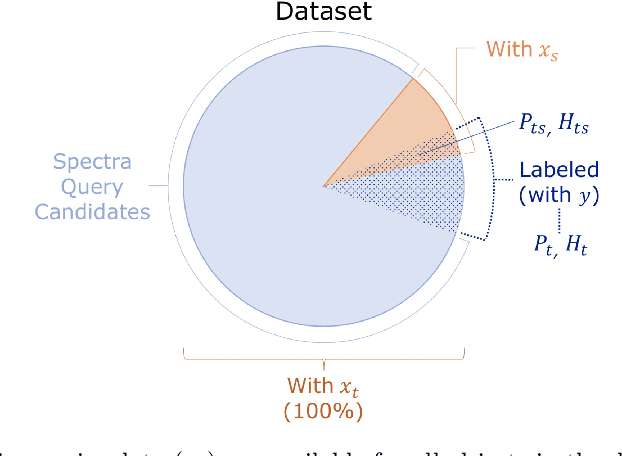
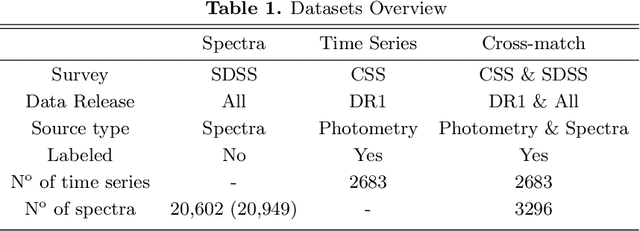
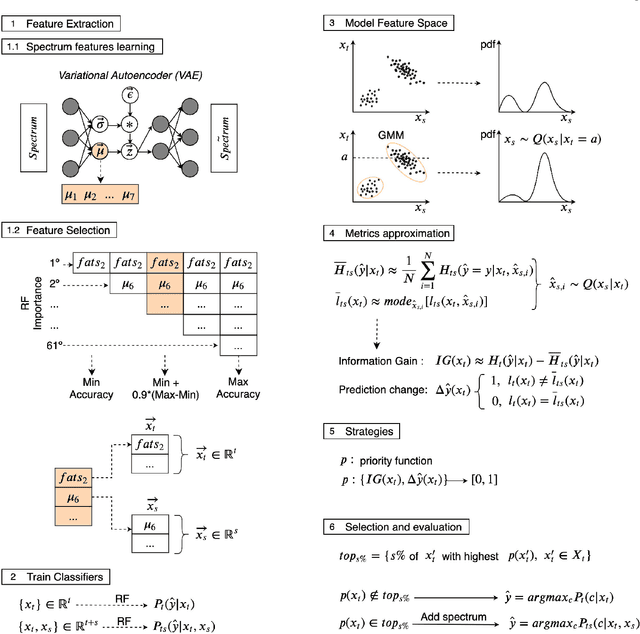
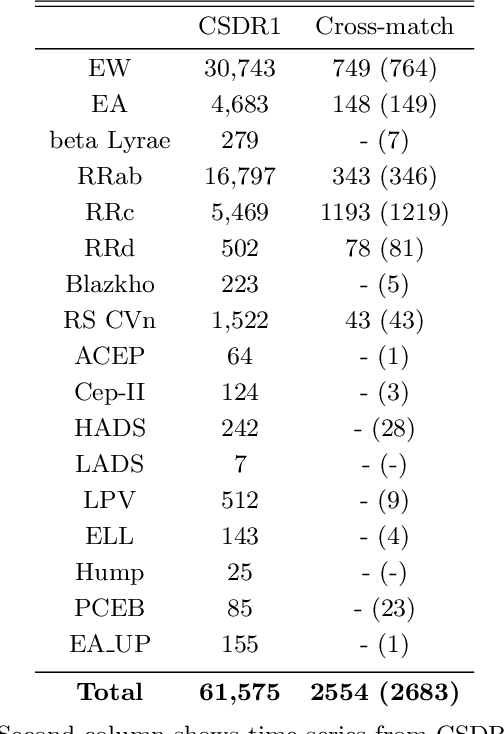
Classification and characterization of variable phenomena and transient phenomena are critical for astrophysics and cosmology. These objects are commonly studied using photometric time series or spectroscopic data. Given that many ongoing and future surveys are in time-domain and given that adding spectra provide further insights but requires more observational resources, it would be valuable to know which objects should we prioritize to have spectrum in addition to time series. We propose a methodology in a probabilistic setting that determines a-priory which objects are worth taking spectrum to obtain better insights, where we focus 'insight' as the type of the object (classification). Objects for which we query its spectrum are reclassified using their full spectrum information. We first train two classifiers, one that uses photometric data and another that uses photometric and spectroscopic data together. Then for each photometric object we estimate the probability of each possible spectrum outcome. We combine these models in various probabilistic frameworks (strategies) which are used to guide the selection of follow up observations. The best strategy depends on the intended use, whether it is getting more confidence or accuracy. For a given number of candidate objects (127, equal to 5% of the dataset) for taking spectra, we improve 37% class prediction accuracy as opposed to 20% of a non-naive (non-random) best base-line strategy. Our approach provides a general framework for follow-up strategies and can be extended beyond classification and to include other forms of follow-ups beyond spectroscopy.
Computational Intelligence Challenges and Applications on Large-Scale Astronomical Time Series Databases
Sep 25, 2015
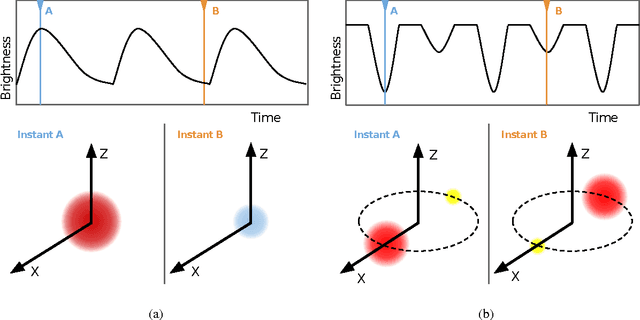
Time-domain astronomy (TDA) is facing a paradigm shift caused by the exponential growth of the sample size, data complexity and data generation rates of new astronomical sky surveys. For example, the Large Synoptic Survey Telescope (LSST), which will begin operations in northern Chile in 2022, will generate a nearly 150 Petabyte imaging dataset of the southern hemisphere sky. The LSST will stream data at rates of 2 Terabytes per hour, effectively capturing an unprecedented movie of the sky. The LSST is expected not only to improve our understanding of time-varying astrophysical objects, but also to reveal a plethora of yet unknown faint and fast-varying phenomena. To cope with a change of paradigm to data-driven astronomy, the fields of astroinformatics and astrostatistics have been created recently. The new data-oriented paradigms for astronomy combine statistics, data mining, knowledge discovery, machine learning and computational intelligence, in order to provide the automated and robust methods needed for the rapid detection and classification of known astrophysical objects as well as the unsupervised characterization of novel phenomena. In this article we present an overview of machine learning and computational intelligence applications to TDA. Future big data challenges and new lines of research in TDA, focusing on the LSST, are identified and discussed from the viewpoint of computational intelligence/machine learning. Interdisciplinary collaboration will be required to cope with the challenges posed by the deluge of astronomical data coming from the LSST.
Period Estimation in Astronomical Time Series Using Slotted Correntropy
Dec 13, 2011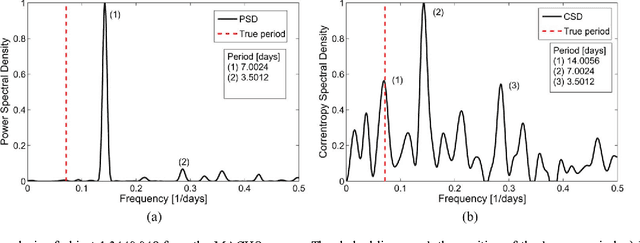
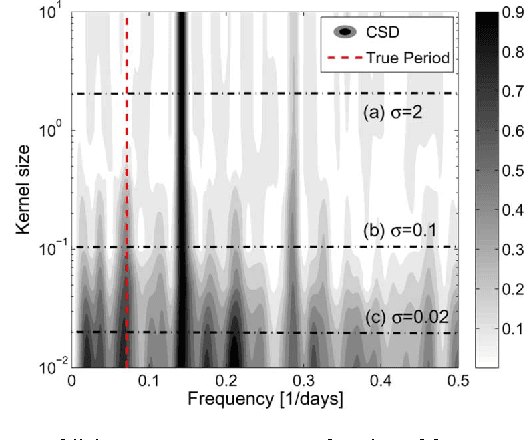
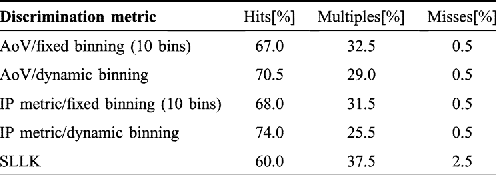
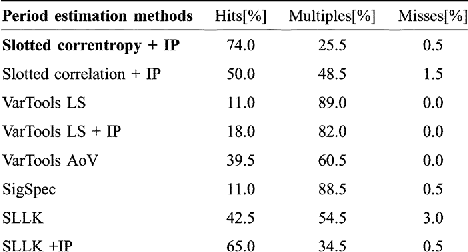
In this letter, we propose a method for period estimation in light curves from periodic variable stars using correntropy. Light curves are astronomical time series of stellar brightness over time, and are characterized as being noisy and unevenly sampled. We propose to use slotted time lags in order to estimate correntropy directly from irregularly sampled time series. A new information theoretic metric is proposed for discriminating among the peaks of the correntropy spectral density. The slotted correntropy method outperformed slotted correlation, string length, VarTools (Lomb-Scargle periodogram and Analysis of Variance), and SigSpec applications on a set of light curves drawn from the MACHO survey.