 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-regulated convolutional neural network for classifying variable stars
May 20, 2025Over the last two decades, machine learning models have been widely applied and have proven effective in classifying variable stars, particularly with the adoption of deep learning architectures such as convolutional neural networks, recurrent neural networks, and transformer models. While these models have achieved high accuracy, they require high-quality, representative data and a large number of labelled samples for each star type to generalise well, which can be challenging in time-domain surveys. This challenge often leads to models learning and reinforcing biases inherent in the training data, an issue that is not easily detectable when validation is performed on subsamples from the same catalogue. The problem of biases in variable star data has been largely overlooked, and a definitive solution has yet to be established. In this paper, we propose a new approach to improve the reliability of classifiers in variable star classification by introducing a self-regulated training process. This process utilises synthetic samples generated by a physics-enhanced latent space variational autoencoder, incorporating six physical parameters from Gaia Data Release 3. Our method features a dynamic interaction between a classifier and a generative model, where the generative model produces ad-hoc synthetic light curves to reduce confusion during classifier training and populate underrepresented regions in the physical parameter space. Experiments conducted under various scenarios demonstrate that our self-regulated training approach outperforms traditional training methods for classifying variable stars on biased datasets, showing statistically significant improvements.
Distinguishing a planetary transit from false positives: a Transformer-based classification for planetary transit signals
Apr 27, 2023Current space-based missions, such as the Transiting Exoplanet Survey Satellite (TESS), provide a large database of light curves that must be analysed efficiently and systematically. In recent years, deep learning (DL) methods, particularly convolutional neural networks (CNN), have been used to classify transit signals of candidate exoplanets automatically. However, CNNs have some drawbacks; for example, they require many layers to capture dependencies on sequential data, such as light curves, making the network so large that it eventually becomes impractical. The self-attention mechanism is a DL technique that attempts to mimic the action of selectively focusing on some relevant things while ignoring others. Models, such as the Transformer architecture, were recently proposed for sequential data with successful results. Based on these successful models, we present a new architecture for the automatic classification of transit signals. Our proposed architecture is designed to capture the most significant features of a transit signal and stellar parameters through the self-attention mechanism. In addition to model prediction, we take advantage of attention map inspection, obtaining a more interpretable DL approach. Thus, we can identify the relevance of each element to differentiate a transit signal from false positives, simplifying the manual examination of candidates. We show that our architecture achieves competitive results concerning the CNNs applied for recognizing exoplanetary transit signals in data from the TESS telescope. Based on these results, we demonstrate that applying this state-of-the-art DL model to light curves can be a powerful technique for transit signal detection while offering a level of interpretability.
Informative regularization for a multi-layer perceptron RR Lyrae classifier under data shift
Mar 12, 2023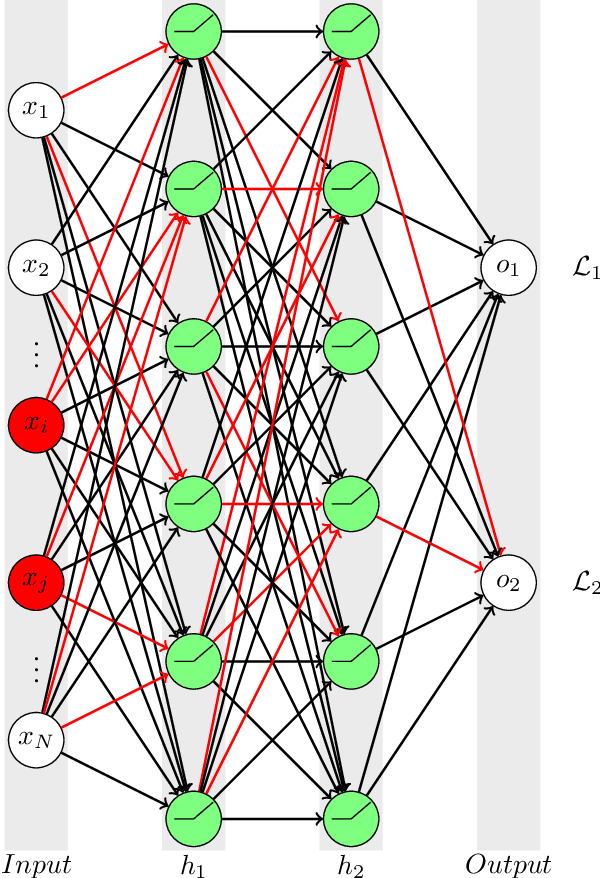
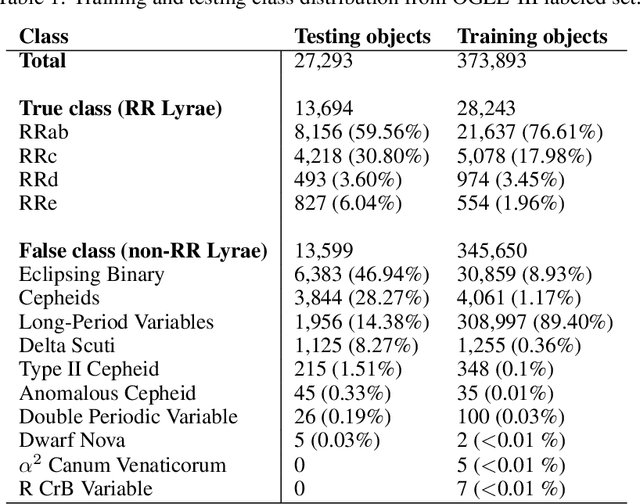
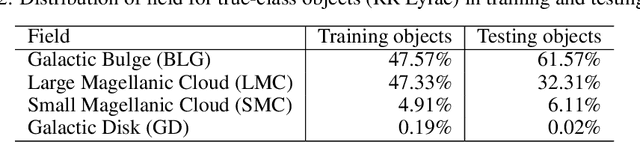
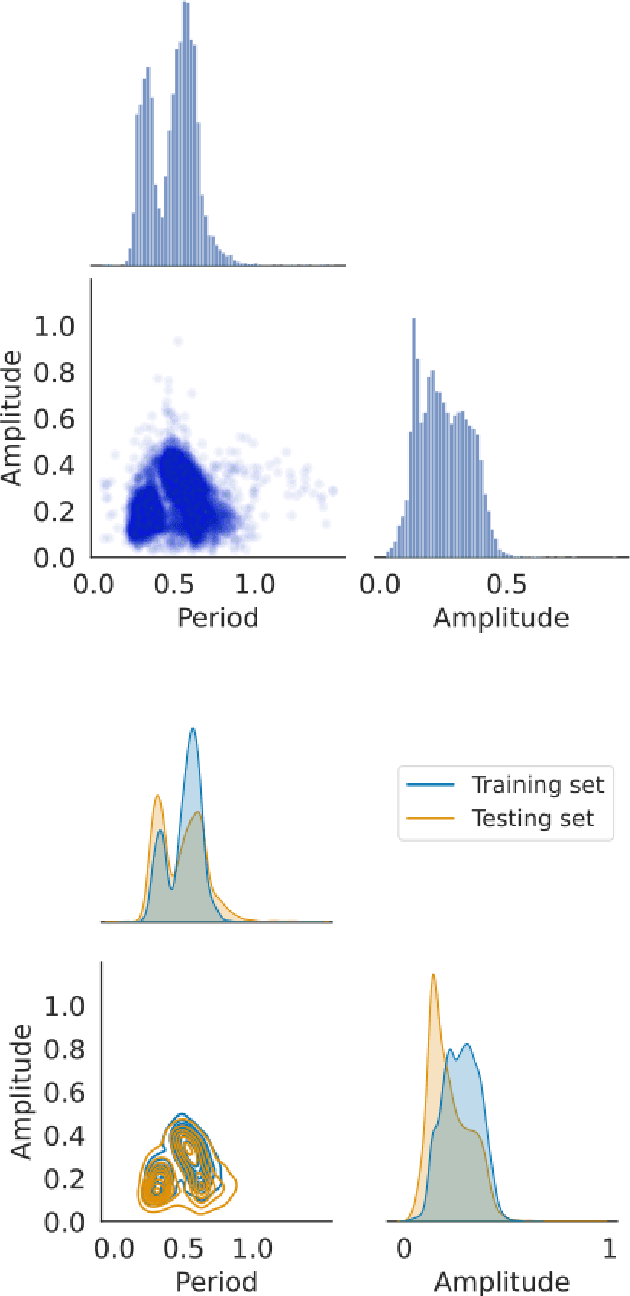
In recent decades, machine learning has provided valuable models and algorithms for processing and extracting knowledge from time-series surveys. Different classifiers have been proposed and performed to an excellent standard. Nevertheless, few papers have tackled the data shift problem in labeled training sets, which occurs when there is a mismatch between the data distribution in the training set and the testing set. This drawback can damage the prediction performance in unseen data. Consequently, we propose a scalable and easily adaptable approach based on an informative regularization and an ad-hoc training procedure to mitigate the shift problem during the training of a multi-layer perceptron for RR Lyrae classification. We collect ranges for characteristic features to construct a symbolic representation of prior knowledge, which was used to model the informative regularizer component. Simultaneously, we design a two-step back-propagation algorithm to integrate this knowledge into the neural network, whereby one step is applied in each epoch to minimize classification error, while another is applied to ensure regularization. Our algorithm defines a subset of parameters (a mask) for each loss function. This approach handles the forgetting effect, which stems from a trade-off between these loss functions (learning from data versus learning expert knowledge) during training. Experiments were conducted using recently proposed shifted benchmark sets for RR Lyrae stars, outperforming baseline models by up to 3\% through a more reliable classifier. Our method provides a new path to incorporate knowledge from characteristic features into artificial neural networks to manage the underlying data shift problem.