 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Long-tailed Medical Diagnosis with Relation-aware Representation Learning and Iterative Classifier Calibration
Feb 05, 2025



Recently computer-aided diagnosis has demonstrated promising performance, effectively alleviating the workload of clinicians. However, the inherent sample imbalance among different diseases leads algorithms biased to the majority categories, leading to poor performance for rare categories. Existing works formulated this challenge as a long-tailed problem and attempted to tackle it by decoupling the feature representation and classification. Yet, due to the imbalanced distribution and limited samples from tail classes, these works are prone to biased representation learning and insufficient classifier calibration. To tackle these problems, we propose a new Long-tailed Medical Diagnosis (LMD) framework for balanced medical image classification on long-tailed datasets. In the initial stage, we develop a Relation-aware Representation Learning (RRL) scheme to boost the representation ability by encouraging the encoder to capture intrinsic semantic features through different data augmentations. In the subsequent stage, we propose an Iterative Classifier Calibration (ICC) scheme to calibrate the classifier iteratively. This is achieved by generating a large number of balanced virtual features and fine-tuning the encoder using an Expectation-Maximization manner. The proposed ICC compensates for minority categories to facilitate unbiased classifier optimization while maintaining the diagnostic knowledge in majority classes. Comprehensive experiments on three public long-tailed medical datasets demonstrate that our LMD framework significantly surpasses state-of-the-art approaches. The source code can be accessed at https://github.com/peterlipan/LMD.
Focus on Focus: Focus-oriented Representation Learning and Multi-view Cross-modal Alignment for Glioma Grading
Aug 16, 2024



Recently, multimodal deep learning, which integrates histopathology slides and molecular biomarkers, has achieved a promising performance in glioma grading. Despite great progress, due to the intra-modality complexity and inter-modality heterogeneity, existing studies suffer from inadequate histopathology representation learning and inefficient molecular-pathology knowledge alignment. These two issues hinder existing methods to precisely interpret diagnostic molecular-pathology features, thereby limiting their grading performance. Moreover, the real-world applicability of existing multimodal approaches is significantly restricted as molecular biomarkers are not always available during clinical deployment. To address these problems, we introduce a novel Focus on Focus (FoF) framework with paired pathology-genomic training and applicable pathology-only inference, enhancing molecular-pathology representation effectively. Specifically, we propose a Focus-oriented Representation Learning (FRL) module to encourage the model to identify regions positively or negatively related to glioma grading and guide it to focus on the diagnostic areas with a consistency constraint. To effectively link the molecular biomarkers to morphological features, we propose a Multi-view Cross-modal Alignment (MCA) module that projects histopathology representations into molecular subspaces, aligning morphological features with corresponding molecular biomarker status by supervised contrastive learning. Experiments on the TCGA GBM-LGG dataset demonstrate that our FoF framework significantly improves the glioma grading. Remarkably, our FoF achieves superior performance using only histopathology slides compared to existing multimodal methods. The source code is available at https://github.com/peterlipan/FoF.
Unified Multi-modal Diagnostic Framework with Reconstruction Pre-training and Heterogeneity-combat Tuning
Apr 09, 2024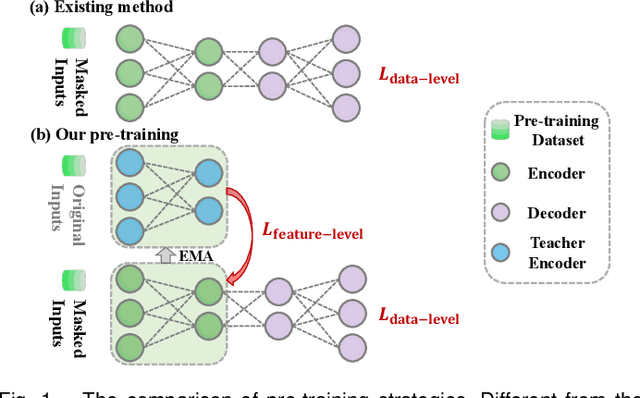
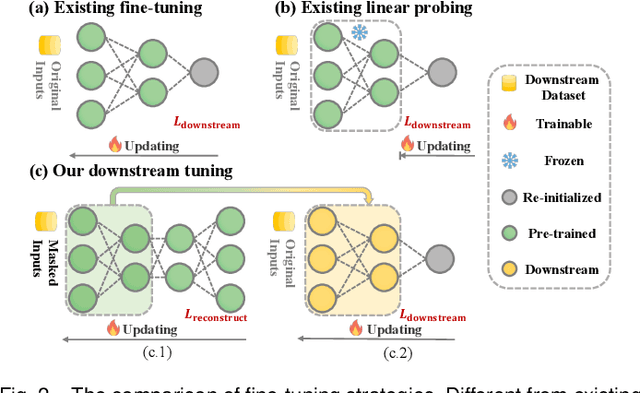
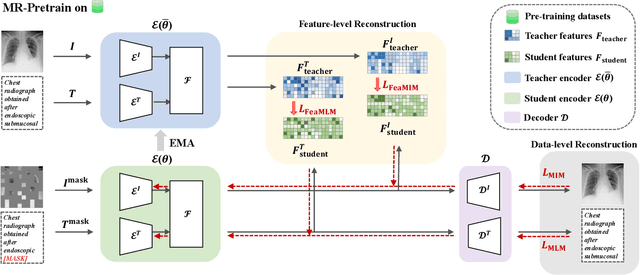
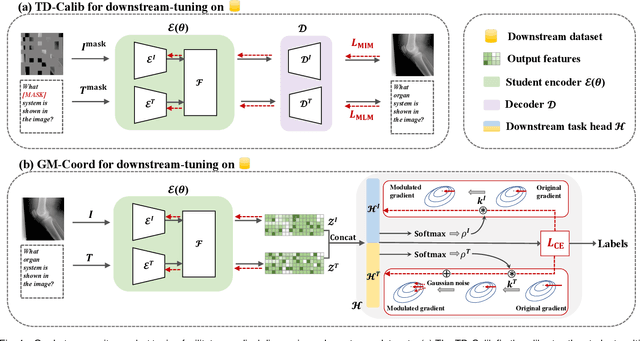
Medical multi-modal pre-training has revealed promise in computer-aided diagnosis by leveraging large-scale unlabeled datasets. However, existing methods based on masked autoencoders mainly rely on data-level reconstruction tasks, but lack high-level semantic information. Furthermore, two significant heterogeneity challenges hinder the transfer of pre-trained knowledge to downstream tasks, \textit{i.e.}, the distribution heterogeneity between pre-training data and downstream data, and the modality heterogeneity within downstream data. To address these challenges, we propose a Unified Medical Multi-modal Diagnostic (UMD) framework with tailored pre-training and downstream tuning strategies. Specifically, to enhance the representation abilities of vision and language encoders, we propose the Multi-level Reconstruction Pre-training (MR-Pretrain) strategy, including a feature-level and data-level reconstruction, which guides models to capture the semantic information from masked inputs of different modalities. Moreover, to tackle two kinds of heterogeneities during the downstream tuning, we present the heterogeneity-combat downstream tuning strategy, which consists of a Task-oriented Distribution Calibration (TD-Calib) and a Gradient-guided Modality Coordination (GM-Coord). In particular, TD-Calib fine-tunes the pre-trained model regarding the distribution of downstream datasets, and GM-Coord adjusts the gradient weights according to the dynamic optimization status of different modalities. Extensive experiments on five public medical datasets demonstrate the effectiveness of our UMD framework, which remarkably outperforms existing approaches on three kinds of downstream tasks.
Truncated Non-Uniform Quantization for Distributed SGD
Feb 02, 2024
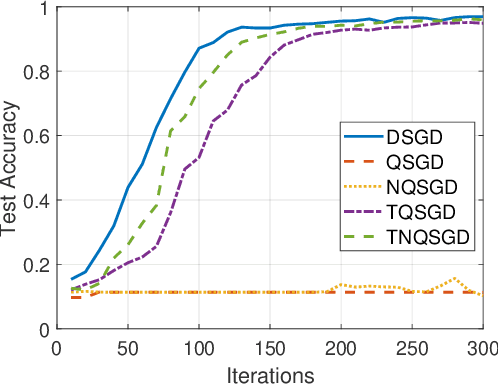
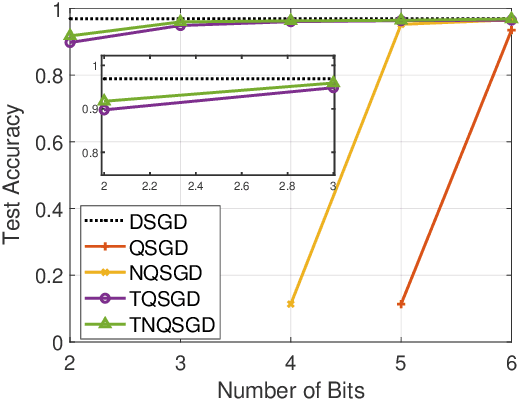
To address the communication bottleneck challenge in distributed learning, our work introduces a novel two-stage quantization strategy designed to enhance the communication efficiency of distributed Stochastic Gradient Descent (SGD). The proposed method initially employs truncation to mitigate the impact of long-tail noise, followed by a non-uniform quantization of the post-truncation gradients based on their statistical characteristics. We provide a comprehensive convergence analysis of the quantized distributed SGD, establishing theoretical guarantees for its performance. Furthermore, by minimizing the convergence error, we derive optimal closed-form solutions for the truncation threshold and non-uniform quantization levels under given communication constraints. Both theoretical insights and extensive experimental evaluations demonstrate that our proposed algorithm outperforms existing quantization schemes, striking a superior balance between communication efficiency and convergence performance.
Improved Quantization Strategies for Managing Heavy-tailed Gradients in Distributed Learning
Feb 02, 2024Gradient compression has surfaced as a key technique to address the challenge of communication efficiency in distributed learning. In distributed deep learning, however, it is observed that gradient distributions are heavy-tailed, with outliers significantly influencing the design of compression strategies. Existing parameter quantization methods experience performance degradation when this heavy-tailed feature is ignored. In this paper, we introduce a novel compression scheme specifically engineered for heavy-tailed gradients, which effectively combines gradient truncation with quantization. This scheme is adeptly implemented within a communication-limited distributed Stochastic Gradient Descent (SGD) framework. We consider a general family of heavy-tail gradients that follow a power-law distribution, we aim to minimize the error resulting from quantization, thereby determining optimal values for two critical parameters: the truncation threshold and the quantization density. We provide a theoretical analysis on the convergence error bound under both uniform and non-uniform quantization scenarios. Comparative experiments with other benchmarks demonstrate the effectiveness of our proposed method in managing the heavy-tailed gradients in a distributed learning environment.
Killing Two Birds with One Stone: Quantization Achieves Privacy in Distributed Learning
Apr 26, 2023Communication efficiency and privacy protection are two critical issues in distributed machine learning. Existing methods tackle these two issues separately and may have a high implementation complexity that constrains their application in a resource-limited environment. We propose a comprehensive quantization-based solution that could simultaneously achieve communication efficiency and privacy protection, providing new insights into the correlated nature of communication and privacy. Specifically, we demonstrate the effectiveness of our proposed solutions in the distributed stochastic gradient descent (SGD) framework by adding binomial noise to the uniformly quantized gradients to reach the desired differential privacy level but with a minor sacrifice in communication efficiency. We theoretically capture the new trade-offs between communication, privacy, and learning performance.
Privacy-Preserving Communication-Efficient Federated Multi-Armed Bandits
Nov 02, 2021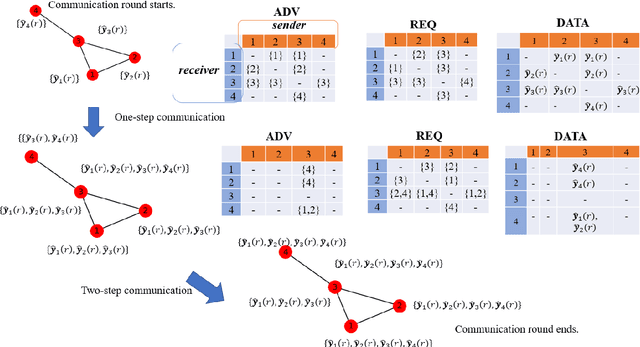
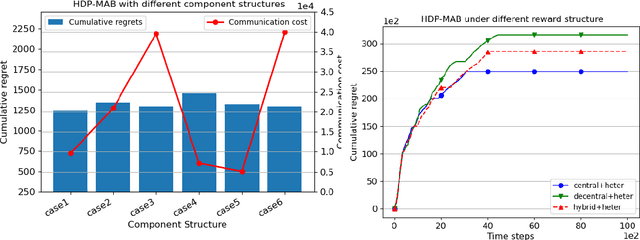
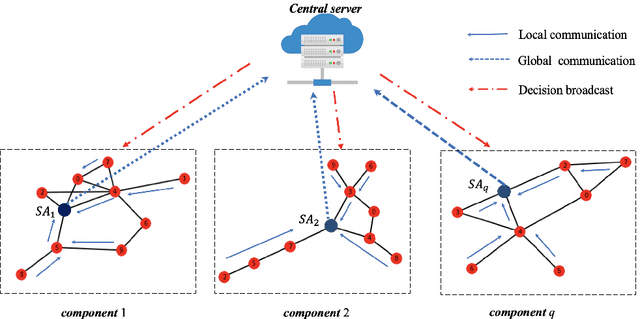
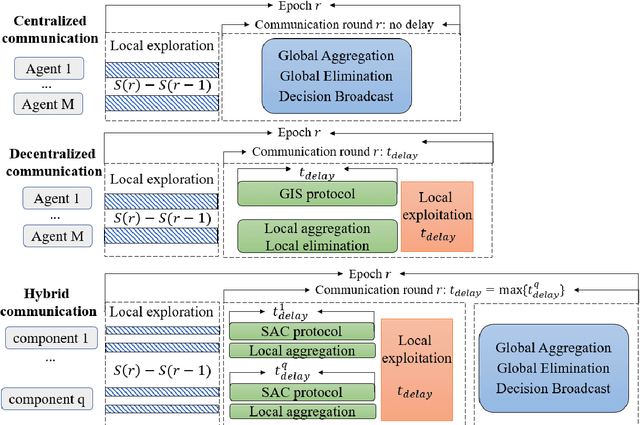
Communication bottleneck and data privacy are two critical concerns in federated multi-armed bandit (MAB) problems, such as situations in decision-making and recommendations of connected vehicles via wireless. In this paper, we design the privacy-preserving communication-efficient algorithm in such problems and study the interactions among privacy, communication and learning performance in terms of the regret. To be specific, we design privacy-preserving learning algorithms and communication protocols and derive the learning regret when networked private agents are performing online bandit learning in a master-worker, a decentralized and a hybrid structure. Our bandit learning algorithms are based on epoch-wise sub-optimal arm eliminations at each agent and agents exchange learning knowledge with the server/each other at the end of each epoch. Furthermore, we adopt the differential privacy (DP) approach to protect the data privacy at each agent when exchanging information; and we curtail communication costs by making less frequent communications with fewer agents participation. By analyzing the regret of our proposed algorithmic framework in the master-worker, decentralized and hybrid structures, we theoretically show tradeoffs between regret and communication costs/privacy. Finally, we empirically show these trade-offs which are consistent with our theoretical analysis.
Distributed Thompson Sampling
Dec 03, 2020We study a cooperative multi-agent multi-armed bandits with M agents and K arms. The goal of the agents is to minimized the cumulative regret. We adapt a traditional Thompson Sampling algoirthm under the distributed setting. However, with agent's ability to communicate, we note that communication may further reduce the upper bound of the regret for a distributed Thompson Sampling approach. To further improve the performance of distributed Thompson Sampling, we propose a distributed Elimination based Thompson Sampling algorithm that allow the agents to learn collaboratively. We analyse the algorithm under Bernoulli reward and derived a problem dependent upper bound on the cumulative regret.
Federated Recommendation System via Differential Privacy
May 16, 2020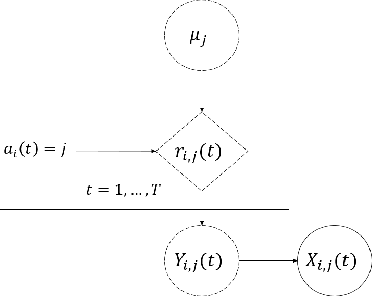

In this paper, we are interested in what we term the federated private bandits framework, that combines differential privacy with multi-agent bandit learning. We explore how differential privacy based Upper Confidence Bound (UCB) methods can be applied to multi-agent environments, and in particular to federated learning environments both in `master-worker' and `fully decentralized' settings. We provide a theoretical analysis on the privacy and regret performance of the proposed methods and explore the tradeoffs between these two.