Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Recommendation System via Differential Privacy
Paper and Code
May 16, 2020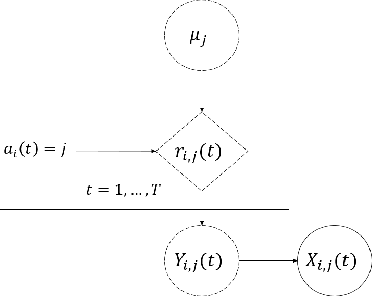

In this paper, we are interested in what we term the federated private bandits framework, that combines differential privacy with multi-agent bandit learning. We explore how differential privacy based Upper Confidence Bound (UCB) methods can be applied to multi-agent environments, and in particular to federated learning environments both in `master-worker' and `fully decentralized' settings. We provide a theoretical analysis on the privacy and regret performance of the proposed methods and explore the tradeoffs between these two.
* This paper is accepted by 2020 IEEE International Symposium on
Information Theory(ISIT 2020)
View paper on