 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scaling: Assessing Strategic Reasoning and Rapid Decision-Making Capability of LLMs in Zero-sum Environments
Mar 10, 2026Large Language Models (LLMs) have achieved strong performance on static reasoning benchmarks, yet their effectiveness as interactive agents operating in adversarial, time-sensitive environments remains poorly understood. Existing evaluations largely treat reasoning as a single-shot capability, overlooking the challenges of opponent-aware decision-making, temporal constraints, and execution under pressure. This paper introduces Strategic Tactical Agent Reasoning (STAR) Benchmark, a multi-agent evaluation framework that assesses LLMs through 1v1 zero-sum competitive interactions, framing reasoning as an iterative, adaptive decision-making process. STAR supports both turn-based and real-time settings, enabling controlled analysis of long-horizon strategic planning and fast-paced tactical execution within a unified environment. Built on a modular architecture with a standardized API and fully implemented execution engine, STAR facilitates reproducible evaluation and flexible task customization. To move beyond binary win-loss outcomes, we introduce a Strategic Evaluation Suite that assesses not only competitive success but also the quality of strategic behavior, such as execution efficiency and outcome stability. Extensive pairwise evaluations reveal a pronounced strategy-execution gap: while reasoning-intensive models dominate turn-based settings, their inference latency often leads to inferior performance in real-time scenarios, where faster instruction-tuned models prevail. These results show that strategic intelligence in interactive environments depends not only on reasoning depth, but also on the ability to translate plans into timely actions, positioning STAR as a principled benchmark for studying this trade-off in competitive, dynamic settings.
Model Inversion Attack via Dynamic Memory Learning
Aug 24, 2023
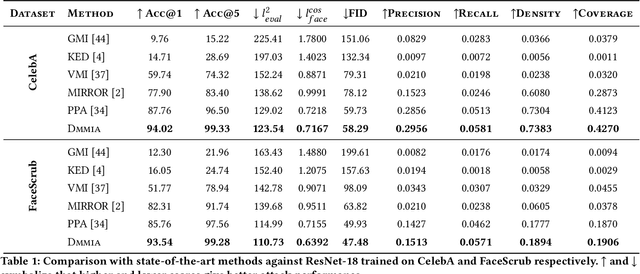
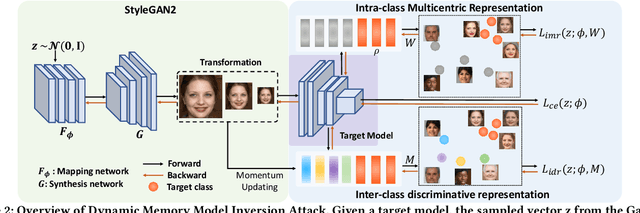
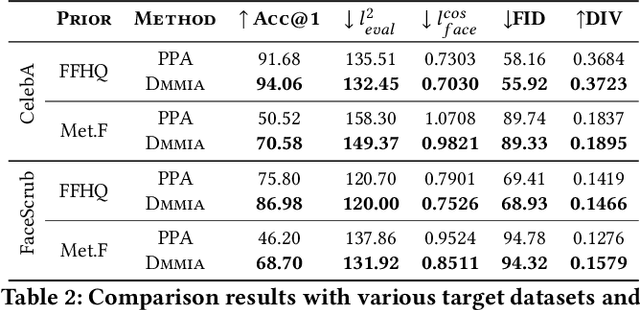
Model Inversion (MI) attacks aim to recover the private training data from the target model, which has raised security concerns about the deployment of DNNs in practice. Recent advances in generative adversarial models have rendered them particularly effective in MI attacks, primarily due to their ability to generate high-fidelity and perceptually realistic images that closely resemble the target data. In this work, we propose a novel Dynamic Memory Model Inversion Attack (DMMIA) to leverage historically learned knowledge, which interacts with samples (during the training) to induce diverse generations. DMMIA constructs two types of prototypes to inject the information about historically learned knowledge: Intra-class Multicentric Representation (IMR) representing target-related concepts by multiple learnable prototypes, and Inter-class Discriminative Representation (IDR) characterizing the memorized samples as learned prototypes to capture more privacy-related information. As a result, our DMMIA has a more informative representation, which brings more diverse and discriminative generated results. Experiments on multiple benchmarks show that DMMIA performs better than state-of-the-art MI attack methods.
Robust Automatic Speech Recognition via WavAugment Guided Phoneme Adversarial Training
Jul 24, 2023


Developing a practically-robust automatic speech recognition (ASR) is challenging since the model should not only maintain the original performance on clean samples, but also achieve consistent efficacy under small volume perturbations and large domain shifts. To address this problem, we propose a novel WavAugment Guided Phoneme Adversarial Training (wapat). wapat use adversarial examples in phoneme space as augmentation to make the model invariant to minor fluctuations in phoneme representation and preserve the performance on clean samples. In addition, wapat utilizes the phoneme representation of augmented samples to guide the generation of adversaries, which helps to find more stable and diverse gradient-directions, resulting in improved generalization. Extensive experiments demonstrate the effectiveness of wapat on End-to-end Speech Challenge Benchmark (ESB). Notably, SpeechLM-wapat outperforms the original model by 6.28% WER reduction on ESB, achieving the new state-of-the-art.
Enhance the Visual Representation via Discrete Adversarial Training
Sep 16, 2022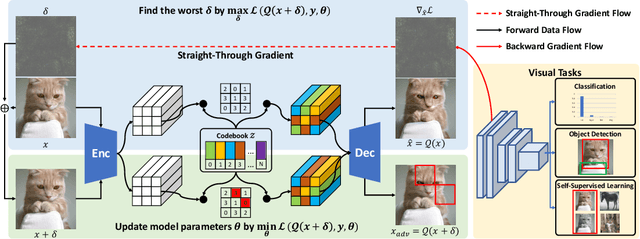
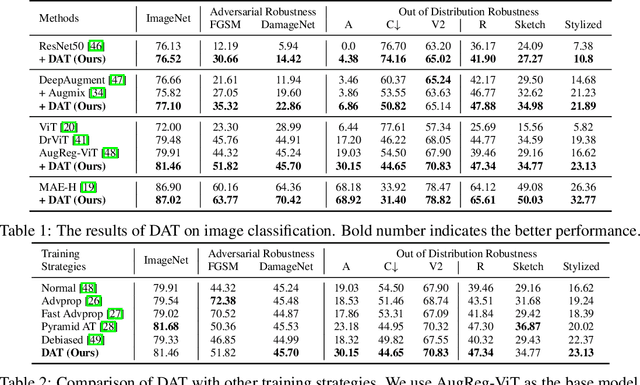
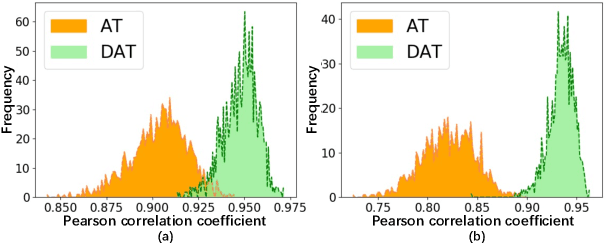
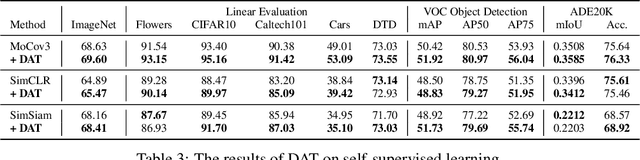
Adversarial Training (AT), which is commonly accepted as one of the most effective approaches defending against adversarial examples, can largely harm the standard performance, thus has limited usefulness on industrial-scale production and applications. Surprisingly, this phenomenon is totally opposite in Natural Language Processing (NLP) task, where AT can even benefit for generalization. We notice the merit of AT in NLP tasks could derive from the discrete and symbolic input space. For borrowing the advantage from NLP-style AT, we propose Discrete Adversarial Training (DAT). DAT leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations. We further give an explanation from the perspective of distribution to demonstrate the effectiveness of DAT. As a plug-and-play technique for enhancing the visual representation, DAT achieves significant improvement on multiple tasks including image classification, object detection and self-supervised learning. Especially, the model pre-trained with Masked Auto-Encoding (MAE) and fine-tuned by our DAT without extra data can get 31.40 mCE on ImageNet-C and 32.77% top-1 accuracy on Stylized-ImageNet, building the new state-of-the-art. The code will be available at https://github.com/alibaba/easyrobust.
Towards Robust Vision Transformer
May 26, 2021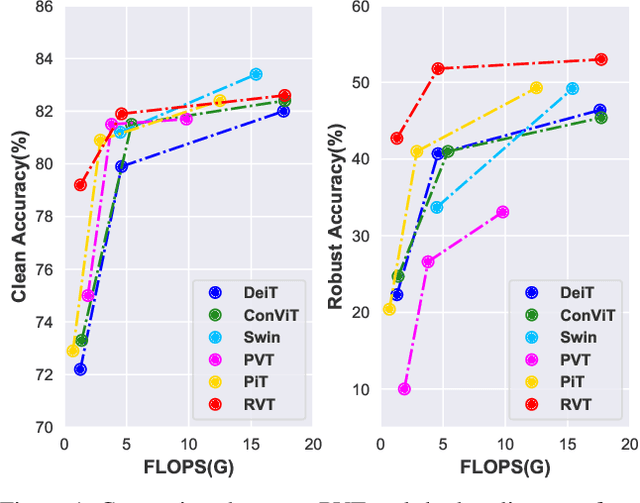
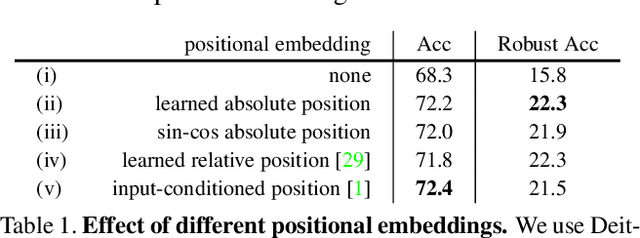
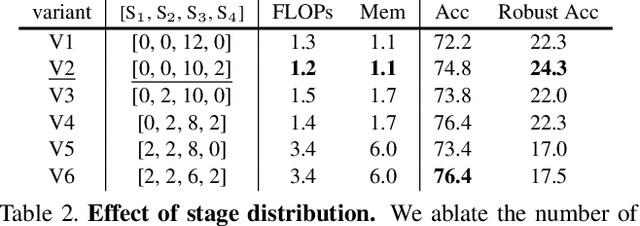
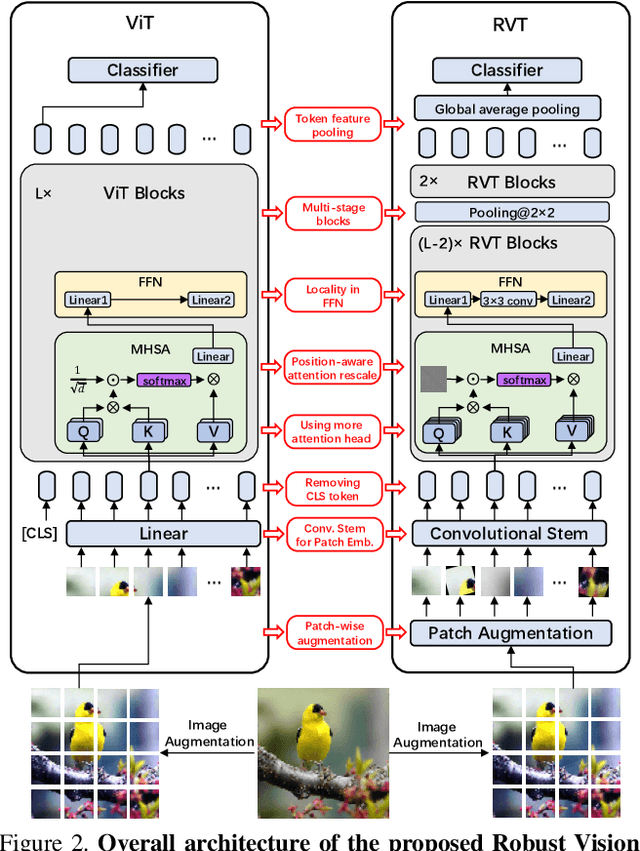
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://git.io/Jswdk}.
Stabilized Medical Image Attacks
Mar 09, 2021

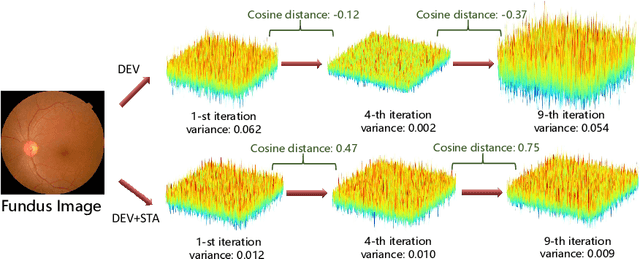
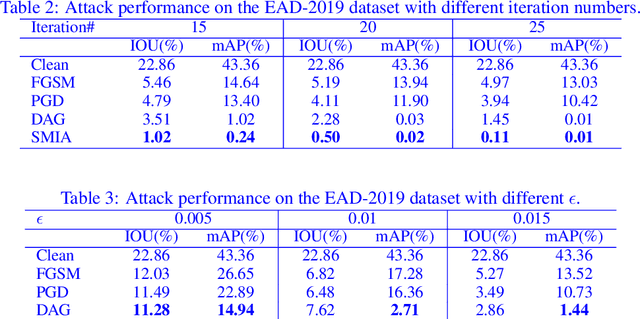
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, a threat to these systems arises that adversarial attacks make CNNs vulnerable. Inaccurate diagnosis results make a negative influence on human healthcare. There is a need to investigate potential adversarial attacks to robustify deep medical diagnosis systems. On the other side, there are several modalities of medical images (e.g., CT, fundus, and endoscopic image) of which each type is significantly different from others. It is more challenging to generate adversarial perturbations for different types of medical images. In this paper, we propose an image-based medical adversarial attack method to consistently produce adversarial perturbations on medical images. The objective function of our method consists of a loss deviation term and a loss stabilization term. The loss deviation term increases the divergence between the CNN prediction of an adversarial example and its ground truth label. Meanwhile, the loss stabilization term ensures similar CNN predictions of this example and its smoothed input. From the perspective of the whole iterations for perturbation generation, the proposed loss stabilization term exhaustively searches the perturbation space to smooth the single spot for local optimum escape. We further analyze the KL-divergence of the proposed loss function and find that the loss stabilization term makes the perturbations updated towards a fixed objective spot while deviating from the ground truth. This stabilization ensures the proposed medical attack effective for different types of medical images while producing perturbations in small variance. Experiments on several medical image analysis benchmarks including the recent COVID-19 dataset show the stability of the proposed method.