 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGMamba: Context-Aware Gated Cross-Modal Mamba Network for Multimodal Sentiment Analysis
Apr 04, 2026Multimodal Sentiment Analysis (MSA) requires effective modeling of cross-modal interactions and contextual dependencies while remaining computationally efficient. Existing fusion approaches predominantly rely on Transformer-based cross-modal attention, which incurs quadratic complexity with respect to sequence length and limits scalability. Moreover, contextual information from preceding utterances is often incorporated through concatenation or independent fusion, without explicit temporal modeling that captures sentiment evolution across dialogue turns. To address these limitations, we propose CAGMamba, a context-aware gated cross-modal Mamba framework for dialogue-based sentiment analysis. Specifically, we organize the contextual and the current-utterance features into a temporally ordered binary sequence, which provides Mamba with explicit temporal structure for modeling sentiment evolution. To further enable controllable cross-modal integration, we propose a Gated Cross-Modal Mamba Network (GCMN) that integrates cross-modal and unimodal paths via learnable gating to balance information fusion and modality preservation, and is trained with a three-branch multi-task objective over text, audio, and fused predictions. Experiments on three benchmark datasets demonstrate that CAGMamba achieves state-of-the-art or competitive results across multiple evaluation metrics. All codes are available at https://github.com/User2024-xj/CAGMamba.
Full end-to-end diagnostic workflow automation of 3D OCT via foundation model-driven AI for retinal diseases
Feb 03, 2026Optical coherence tomography (OCT) has revolutionized retinal disease diagnosis with its high-resolution and three-dimensional imaging nature, yet its full diagnostic automation in clinical practices remains constrained by multi-stage workflows and conventional single-slice single-task AI models. We present Full-process OCT-based Clinical Utility System (FOCUS), a foundation model-driven framework enabling end-to-end automation of 3D OCT retinal disease diagnosis. FOCUS sequentially performs image quality assessment with EfficientNetV2-S, followed by abnormality detection and multi-disease classification using a fine-tuned Vision Foundation Model. Crucially, FOCUS leverages a unified adaptive aggregation method to intelligently integrate 2D slices-level predictions into comprehensive 3D patient-level diagnosis. Trained and tested on 3,300 patients (40,672 slices), and externally validated on 1,345 patients (18,498 slices) across four different-tier centers and diverse OCT devices, FOCUS achieved high F1 scores for quality assessment (99.01%), abnormally detection (97.46%), and patient-level diagnosis (94.39%). Real-world validation across centers also showed stable performance (F1: 90.22%-95.24%). In human-machine comparisons, FOCUS matched expert performance in abnormality detection (F1: 95.47% vs 90.91%) and multi-disease diagnosis (F1: 93.49% vs 91.35%), while demonstrating better efficiency. FOCUS automates the image-to-diagnosis pipeline, representing a critical advance towards unmanned ophthalmology with a validated blueprint for autonomous screening to enhance population scale retinal care accessibility and efficiency.
A Hybrid Autoencoder-Transformer Model for Robust Day-Ahead Electricity Price Forecasting under Extreme Conditions
Nov 10, 2025



Accurate day-ahead electricity price forecasting (DAEPF) is critical for the efficient operation of power systems, but extreme condition and market anomalies pose significant challenges to existing forecasting methods. To overcome these challenges, this paper proposes a novel hybrid deep learning framework that integrates a Distilled Attention Transformer (DAT) model and an Autoencoder Self-regression Model (ASM). The DAT leverages a self-attention mechanism to dynamically assign higher weights to critical segments of historical data, effectively capturing both long-term trends and short-term fluctuations. Concurrently, the ASM employs unsupervised learning to detect and isolate anomalous patterns induced by extreme conditions, such as heavy rain, heat waves, or human festivals. Experiments on datasets sampled from California and Shandong Province demonstrate that our framework significantly outperforms state-of-the-art methods in prediction accuracy, robustness, and computational efficiency. Our framework thus holds promise for enhancing grid resilience and optimizing market operations in future power systems.
COTN: A Chaotic Oscillatory Transformer Network for Complex Volatile Systems under Extreme Conditions
Nov 09, 2025



Accurate prediction of financial and electricity markets, especially under extreme conditions, remains a significant challenge due to their intrinsic nonlinearity, rapid fluctuations, and chaotic patterns. To address these limitations, we propose the Chaotic Oscillatory Transformer Network (COTN). COTN innovatively combines a Transformer architecture with a novel Lee Oscillator activation function, processed through Max-over-Time pooling and a lambda-gating mechanism. This design is specifically tailored to effectively capture chaotic dynamics and improve responsiveness during periods of heightened volatility, where conventional activation functions (e.g., ReLU, GELU) tend to saturate. Furthermore, COTN incorporates an Autoencoder Self-Regressive (ASR) module to detect and isolate abnormal market patterns, such as sudden price spikes or crashes, thereby preventing corruption of the core prediction process and enhancing robustness. Extensive experiments across electricity spot markets and financial markets demonstrate the practical applicability and resilience of COTN. Our approach outperforms state-of-the-art deep learning models like Informer by up to 17% and traditional statistical methods like GARCH by as much as 40%. These results underscore COTN's effectiveness in navigating real-world market uncertainty and complexity, offering a powerful tool for forecasting highly volatile systems under duress.
Restoring Real-World Images with an Internal Detail Enhancement Diffusion Model
May 24, 2025Restoring real-world degraded images, such as old photographs or low-resolution images, presents a significant challenge due to the complex, mixed degradations they exhibit, such as scratches, color fading, and noise. Recent data-driven approaches have struggled with two main challenges: achieving high-fidelity restoration and providing object-level control over colorization. While diffusion models have shown promise in generating high-quality images with specific controls, they often fail to fully preserve image details during restoration. In this work, we propose an internal detail-preserving diffusion model for high-fidelity restoration of real-world degraded images. Our method utilizes a pre-trained Stable Diffusion model as a generative prior, eliminating the need to train a model from scratch. Central to our approach is the Internal Image Detail Enhancement (IIDE) technique, which directs the diffusion model to preserve essential structural and textural information while mitigating degradation effects. The process starts by mapping the input image into a latent space, where we inject the diffusion denoising process with degradation operations that simulate the effects of various degradation factors. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art models in both qualitative assessments and perceptual quantitative evaluations. Additionally, our approach supports text-guided restoration, enabling object-level colorization control that mimics the expertise of professional photo editing.
SCJD: Sparse Correlation and Joint Distillation for Efficient 3D Human Pose Estimation
Mar 18, 2025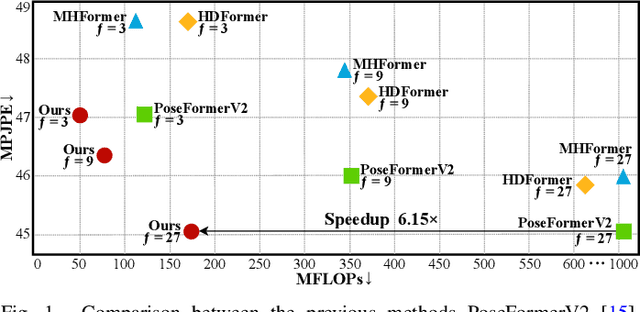
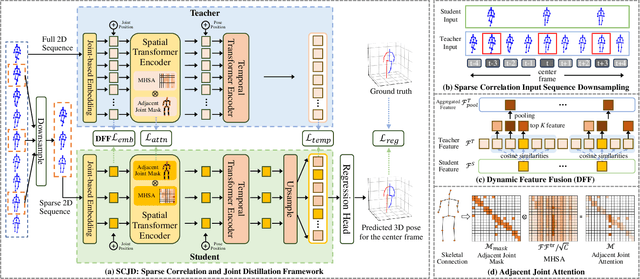
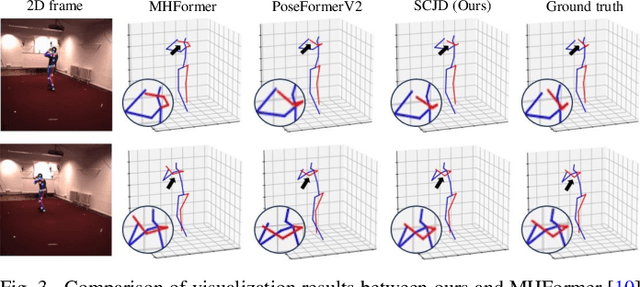
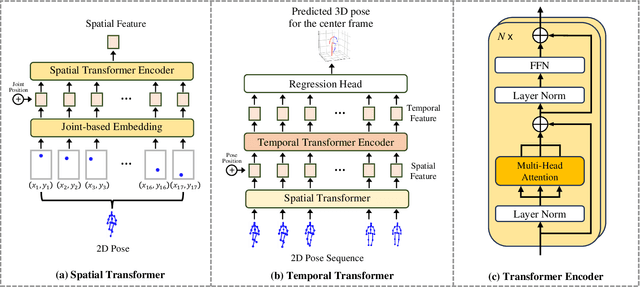
Existing 3D Human Pose Estimation (HPE) methods achieve high accuracy but suffer from computational overhead and slow inference, while knowledge distillation methods fail to address spatial relationships between joints and temporal correlations in multi-frame inputs. In this paper, we propose Sparse Correlation and Joint Distillation (SCJD), a novel framework that balances efficiency and accuracy for 3D HPE. SCJD introduces Sparse Correlation Input Sequence Downsampling to reduce redundancy in student network inputs while preserving inter-frame correlations. For effective knowledge transfer, we propose Dynamic Joint Spatial Attention Distillation, which includes Dynamic Joint Embedding Distillation to enhance the student's feature representation using the teacher's multi-frame context feature, and Adjacent Joint Attention Distillation to improve the student network's focus on adjacent joint relationships for better spatial understanding. Additionally, Temporal Consistency Distillation aligns the temporal correlations between teacher and student networks through upsampling and global supervision. Extensive experiments demonstrate that SCJD achieves state-of-the-art performance. Code is available at https://github.com/wileychan/SCJD.
MRJ-Agent: An Effective Jailbreak Agent for Multi-Round Dialogue
Nov 06, 2024



Large Language Models (LLMs) demonstrate outstanding performance in their reservoir of knowledge and understanding capabilities, but they have also been shown to be prone to illegal or unethical reactions when subjected to jailbreak attacks. To ensure their responsible deployment in critical applications, it is crucial to understand the safety capabilities and vulnerabilities of LLMs. Previous works mainly focus on jailbreak in single-round dialogue, overlooking the potential jailbreak risks in multi-round dialogues, which are a vital way humans interact with and extract information from LLMs. Some studies have increasingly concentrated on the risks associated with jailbreak in multi-round dialogues. These efforts typically involve the use of manually crafted templates or prompt engineering techniques. However, due to the inherent complexity of multi-round dialogues, their jailbreak performance is limited. To solve this problem, we propose a novel multi-round dialogue jailbreaking agent, emphasizing the importance of stealthiness in identifying and mitigating potential threats to human values posed by LLMs. We propose a risk decomposition strategy that distributes risks across multiple rounds of queries and utilizes psychological strategies to enhance attack strength. Extensive experiments show that our proposed method surpasses other attack methods and achieves state-of-the-art attack success rate. We will make the corresponding code and dataset available for future research. The code will be released soon.
HR-Extreme: A High-Resolution Dataset for Extreme Weather Forecasting
Sep 27, 2024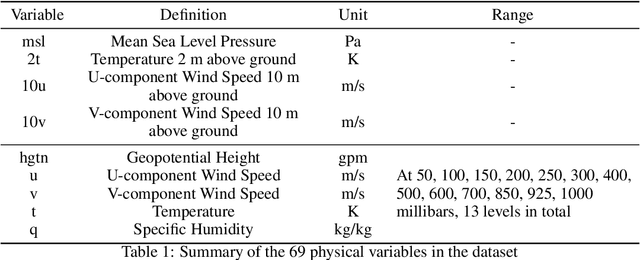


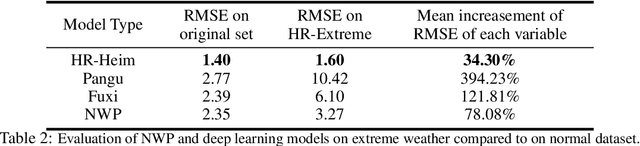
The application of large deep learning models in weather forecasting has led to significant advancements in the field, including higher-resolution forecasting and extended prediction periods exemplified by models such as Pangu and Fuxi. Despite these successes, previous research has largely been characterized by the neglect of extreme weather events, and the availability of datasets specifically curated for such events remains limited. Given the critical importance of accurately forecasting extreme weather, this study introduces a comprehensive dataset that incorporates high-resolution extreme weather cases derived from the High-Resolution Rapid Refresh (HRRR) data, a 3-km real-time dataset provided by NOAA. We also evaluate the current state-of-the-art deep learning models and Numerical Weather Prediction (NWP) systems on HR-Extreme, and provide a improved baseline deep learning model called HR-Heim which has superior performance on both general loss and HR-Extreme compared to others. Our results reveal that the errors of extreme weather cases are significantly larger than overall forecast error, highlighting them as an crucial source of loss in weather prediction. These findings underscore the necessity for future research to focus on improving the accuracy of extreme weather forecasts to enhance their practical utility.
DiffColor: Toward High Fidelity Text-Guided Image Colorization with Diffusion Models
Aug 03, 2023



Recent data-driven image colorization methods have enabled automatic or reference-based colorization, while still suffering from unsatisfactory and inaccurate object-level color control. To address these issues, we propose a new method called DiffColor that leverages the power of pre-trained diffusion models to recover vivid colors conditioned on a prompt text, without any additional inputs. DiffColor mainly contains two stages: colorization with generative color prior and in-context controllable colorization. Specifically, we first fine-tune a pre-trained text-to-image model to generate colorized images using a CLIP-based contrastive loss. Then we try to obtain an optimized text embedding aligning the colorized image and the text prompt, and a fine-tuned diffusion model enabling high-quality image reconstruction. Our method can produce vivid and diverse colors with a few iterations, and keep the structure and background intact while having colors well-aligned with the target language guidance. Moreover, our method allows for in-context colorization, i.e., producing different colorization results by modifying prompt texts without any fine-tuning, and can achieve object-level controllable colorization results. Extensive experiments and user studies demonstrate that DiffColor outperforms previous works in terms of visual quality, color fidelity, and diversity of colorization options.
OMSN and FAROS: OCTA Microstructure Segmentation Network and Fully Annotated Retinal OCTA Segmentation Dataset
Dec 26, 2022



The lack of efficient segmentation methods and fully-labeled datasets limits the comprehensive assessment of optical coherence tomography angiography (OCTA) microstructures like retinal vessel network (RVN) and foveal avascular zone (FAZ), which are of great value in ophthalmic and systematic diseases evaluation. Here, we introduce an innovative OCTA microstructure segmentation network (OMSN) by combining an encoder-decoder-based architecture with multi-scale skip connections and the split-attention-based residual network ResNeSt, paying specific attention to OCTA microstructural features while facilitating better model convergence and feature representations. The proposed OMSN achieves excellent single/multi-task performances for RVN or/and FAZ segmentation. Especially, the evaluation metrics on multi-task models outperform single-task models on the same dataset. On this basis, a fully annotated retinal OCTA segmentation (FAROS) dataset is constructed semi-automatically, filling the vacancy of a pixel-level fully-labeled OCTA dataset. OMSN multi-task segmentation model retrained with FAROS further certifies its outstanding accuracy for simultaneous RVN and FAZ segmentation.