 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Multi-Objective Bayesian Optimisation via Predictive-Gradient Catalysts
Jun 05, 2026This paper presents a general acceleration mechanism for multi-objective Bayesian optimisation (MOBO) that leverages Gaussian process predictive gradients as auxiliary signals. Rather than replacing existing Pareto-compliant acquisition functions, the proposed approach augments them with local stationarity information derived from surrogate-derived gradients, enabling faster convergence toward the global Pareto set under limited evaluation budgets. Two catalyst instantiations are investigated: an adaptive Multiple-Gradient Descent Algorithm-Based Catalyst (MGDA) and a predefined-weight variant that enables focused exploration when budgets are tight. Experiments on the DTLZ benchmark suite (using 2 objectives and 10 decision variables) show that predictive gradient catalysis can deliver significant acceleration compared to other acquisition functions (EHVI, AugTch, tMPoI, SAF) when surrogates are accurate, particularly for stationary problems.
Bayesian Generative Adversarial Networks via Gaussian Approximation for Tabular Data Synthesis
Feb 25, 2026Generative Adversarial Networks (GAN) have been used in many studies to synthesise mixed tabular data. Conditional tabular GAN (CTGAN) have been the most popular variant but struggle to effectively navigate the risk-utility trade-off. Bayesian GAN have received less attention for tabular data, but have been explored with unstructured data such as images and text. The most used technique employed in Bayesian GAN is Markov Chain Monte Carlo (MCMC), but it is computationally intensive, particularly in terms of weight storage. In this paper, we introduce Gaussian Approximation of CTGAN (GACTGAN), an integration of the Bayesian posterior approximation technique using Stochastic Weight Averaging-Gaussian (SWAG) within the CTGAN generator to synthesise tabular data, reducing computational overhead after the training phase. We demonstrate that GACTGAN yields better synthetic data compared to CTGAN, achieving better preservation of tabular structure and inferential statistics with less privacy risk. These results highlight GACTGAN as a simpler, effective implementation of Bayesian tabular synthesis.
Counterfactual Credit Guided Bayesian Optimization
Oct 06, 2025Bayesian optimization has emerged as a prominent methodology for optimizing expensive black-box functions by leveraging Gaussian process surrogates, which focus on capturing the global characteristics of the objective function. However, in numerous practical scenarios, the primary objective is not to construct an exhaustive global surrogate, but rather to quickly pinpoint the global optimum. Due to the aleatoric nature of the sequential optimization problem and its dependence on the quality of the surrogate model and the initial design, it is restrictive to assume that all observed samples contribute equally to the discovery of the optimum in this context. In this paper, we introduce Counterfactual Credit Guided Bayesian Optimization (CCGBO), a novel framework that explicitly quantifies the contribution of individual historical observations through counterfactual credit. By incorporating counterfactual credit into the acquisition function, our approach can selectively allocate resources in areas where optimal solutions are most likely to occur. We prove that CCGBO retains sublinear regret. Empirical evaluations on various synthetic and real-world benchmarks demonstrate that CCGBO consistently reduces simple regret and accelerates convergence to the global optimum.
Gradient-based Sample Selection for Faster Bayesian Optimization
Apr 10, 2025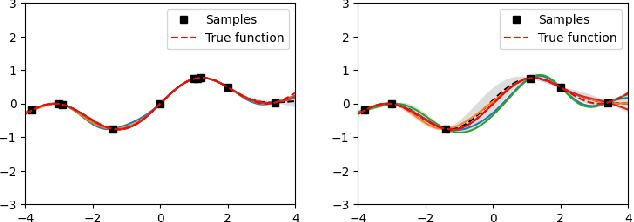
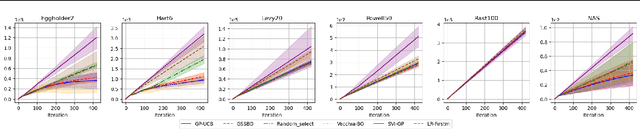
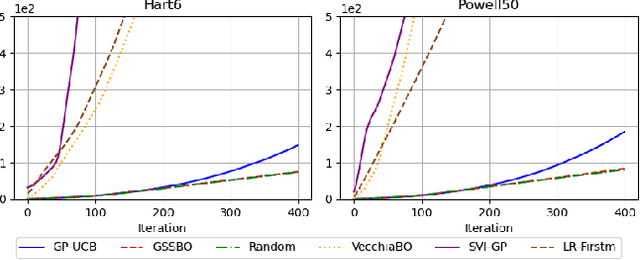
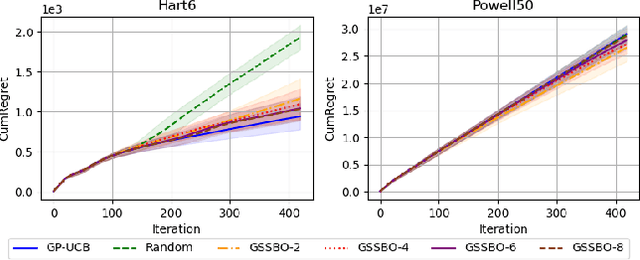
Bayesian optimization (BO) is an effective technique for black-box optimization. However, its applicability is typically limited to moderate-budget problems due to the cubic complexity in computing the Gaussian process (GP) surrogate model. In large-budget scenarios, directly employing the standard GP model faces significant challenges in computational time and resource requirements. In this paper, we propose a novel approach, gradient-based sample selection Bayesian Optimization (GSSBO), to enhance the computational efficiency of BO. The GP model is constructed on a selected set of samples instead of the whole dataset. These samples are selected by leveraging gradient information to maintain diversity and representation. We provide a theoretical analysis of the gradient-based sample selection strategy and obtain explicit sublinear regret bounds for our proposed framework. Extensive experiments on synthetic and real-world tasks demonstrate that our approach significantly reduces the computational cost of GP fitting in BO while maintaining optimization performance comparable to baseline methods.
TAR: Teacher-Aligned Representations via Contrastive Learning for Quadrupedal Locomotion
Mar 26, 2025Quadrupedal locomotion via Reinforcement Learning (RL) is commonly addressed using the teacher-student paradigm, where a privileged teacher guides a proprioceptive student policy. However, key challenges such as representation misalignment between the privileged teacher and the proprioceptive-only student, covariate shift due to behavioral cloning, and lack of deployable adaptation lead to poor generalization in real-world scenarios. We propose Teacher-Aligned Representations via Contrastive Learning (TAR), a framework that leverages privileged information with self-supervised contrastive learning to bridge this gap. By aligning representations to a privileged teacher in simulation via contrastive objectives, our student policy learns structured latent spaces and exhibits robust generalization to Out-of-Distribution (OOD) scenarios, surpassing the fully privileged "Teacher". Results showed accelerated training by 2x compared to state-of-the-art baselines to achieve peak performance. OOD scenarios showed better generalization by 40 percent on average compared to existing methods. Additionally, TAR transitions seamlessly into learning during deployment without requiring privileged states, setting a new benchmark in sample-efficient, adaptive locomotion and enabling continual fine-tuning in real-world scenarios. Open-source code and videos are available at https://ammousa.github.io/TARLoco/.
Automated Flow Pattern Classification in Multi-phase Systems Using AI and Capacitance Sensing Techniques
Feb 23, 2025In multiphase flow systems, classifying flow patterns is crucial to optimize fluid dynamics and enhance system efficiency. Current industrial methods and scientific laboratories mainly depend on techniques such as flow visualization using regular cameras or the naked eye, as well as high-speed imaging at elevated flow rates. These methods are limited by their reliance on subjective interpretations and are particularly applicable in transparent pipes. Consequently, conventional techniques usually achieve context-dependent accuracy rates and often lack generalizability. This study introduces a novel platform that integrates a capacitance sensor and AI-driven classification methods, benchmarked against traditional techniques. Experimental results demonstrate that the proposed approach, utilizing a 1D SENet deep learning model, achieves over 85\% accuracy on experiment-based datasets and 71\% accuracy on pattern-based datasets. These results highlight significant improvements in robustness and reliability compared to existing methodologies. This work offers a transformative pathway for real-time flow monitoring and predictive modeling, addressing key challenges in industrial applications.
MOLLM: Multi-Objective Large Language Model for Molecular Design -- Optimizing with Experts
Feb 18, 2025Molecular design plays a critical role in advancing fields such as drug discovery, materials science, and chemical engineering. This work introduces the Multi-Objective Large Language Model for Molecular Design (MOLLM), a novel framework that combines domain-specific knowledge with the adaptability of Large Language Models to optimize molecular properties across multiple objectives. Leveraging in-context learning and multi-objective optimization, MOLLM achieves superior efficiency, innovation, and performance, significantly surpassing state-of-the-art (SOTA) methods. Recognizing the substantial impact of initial populations on evolutionary algorithms, we categorize them into three types: best initial, worst initial, and random initial, to ensure the initial molecules are the same for each method across experiments. Our results demonstrate that MOLLM consistently outperforms SOTA models in all of our experiments. We also provide extensive ablation studies to evaluate the superiority of our components.
Dynamic Detection of Relevant Objectives and Adaptation to Preference Drifts in Interactive Evolutionary Multi-Objective Optimization
Nov 07, 2024



Evolutionary Multi-Objective Optimization Algorithms (EMOAs) are widely employed to tackle problems with multiple conflicting objectives. Recent research indicates that not all objectives are equally important to the decision-maker (DM). In the context of interactive EMOAs, preference information elicited from the DM during the optimization process can be leveraged to identify and discard irrelevant objectives, a crucial step when objective evaluations are computationally expensive. However, much of the existing literature fails to account for the dynamic nature of DM preferences, which can evolve throughout the decision-making process and affect the relevance of objectives. This study addresses this limitation by simulating dynamic shifts in DM preferences within a ranking-based interactive algorithm. Additionally, we propose methods to discard outdated or conflicting preferences when such shifts occur. Building on prior research, we also introduce a mechanism to safeguard relevant objectives that may become trapped in local or global optima due to the diminished correlation with the DM-provided rankings. Our experimental results demonstrate that the proposed methods effectively manage evolving preferences and significantly enhance the quality and desirability of the solutions produced by the algorithm.
Spatial-aware decision-making with ring attractors in reinforcement learning systems
Oct 04, 2024This paper explores the integration of ring attractors, a mathematical model inspired by neural circuit dynamics, into the reinforcement learning (RL) action selection process. Ring attractors, as specialized brain-inspired structures that encode spatial information and uncertainty, offer a biologically plausible mechanism to improve learning speed and predictive performance. They do so by explicitly encoding the action space, facilitating the organization of neural activity, and enabling the distribution of spatial representations across the neural network in the context of deep RL. The application of ring attractors in the RL action selection process involves mapping actions to specific locations on the ring and decoding the selected action based on neural activity. We investigate the application of ring attractors by both building them as exogenous models and integrating them as part of a Deep Learning policy algorithm. Our results show a significant improvement in state-of-the-art models for the Atari 100k benchmark. Notably, our integrated approach improves the performance of state-of-the-art models by half, representing a 53\% increase over selected baselines.
HR-Extreme: A High-Resolution Dataset for Extreme Weather Forecasting
Sep 27, 2024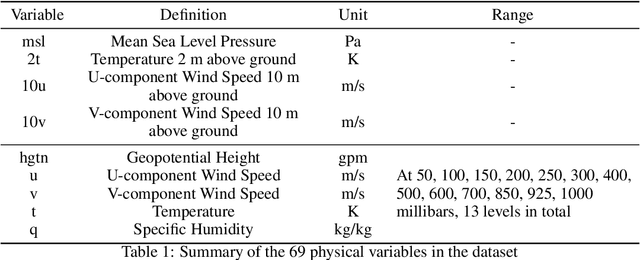


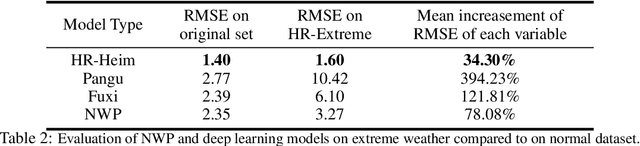
The application of large deep learning models in weather forecasting has led to significant advancements in the field, including higher-resolution forecasting and extended prediction periods exemplified by models such as Pangu and Fuxi. Despite these successes, previous research has largely been characterized by the neglect of extreme weather events, and the availability of datasets specifically curated for such events remains limited. Given the critical importance of accurately forecasting extreme weather, this study introduces a comprehensive dataset that incorporates high-resolution extreme weather cases derived from the High-Resolution Rapid Refresh (HRRR) data, a 3-km real-time dataset provided by NOAA. We also evaluate the current state-of-the-art deep learning models and Numerical Weather Prediction (NWP) systems on HR-Extreme, and provide a improved baseline deep learning model called HR-Heim which has superior performance on both general loss and HR-Extreme compared to others. Our results reveal that the errors of extreme weather cases are significantly larger than overall forecast error, highlighting them as an crucial source of loss in weather prediction. These findings underscore the necessity for future research to focus on improving the accuracy of extreme weather forecasts to enhance their practical utility.