 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective evolutionary GAN for tabular data synthesis
Apr 15, 2024



Synthetic data has a key role to play in data sharing by statistical agencies and other generators of statistical data products. Generative Adversarial Networks (GANs), typically applied to image synthesis, are also a promising method for tabular data synthesis. However, there are unique challenges in tabular data compared to images, eg tabular data may contain both continuous and discrete variables and conditional sampling, and, critically, the data should possess high utility and low disclosure risk (the risk of re-identifying a population unit or learning something new about them), providing an opportunity for multi-objective (MO) optimization. Inspired by MO GANs for images, this paper proposes a smart MO evolutionary conditional tabular GAN (SMOE-CTGAN). This approach models conditional synthetic data by applying conditional vectors in training, and uses concepts from MO optimisation to balance disclosure risk against utility. Our results indicate that SMOE-CTGAN is able to discover synthetic datasets with different risk and utility levels for multiple national census datasets. We also find a sweet spot in the early stage of training where a competitive utility and extremely low risk are achieved, by using an Improvement Score. The full code can be downloaded from https://github.com/HuskyNian/SMO\_EGAN\_pytorch.
Comparing the Utility and Disclosure Risk of Synthetic Data with Samples of Microdata
Jul 02, 2022
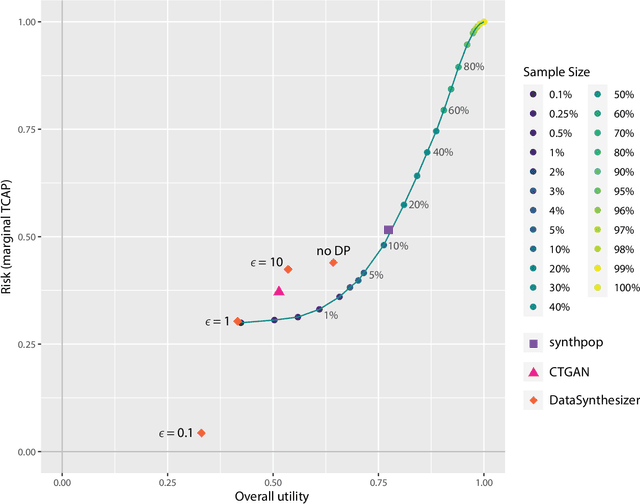
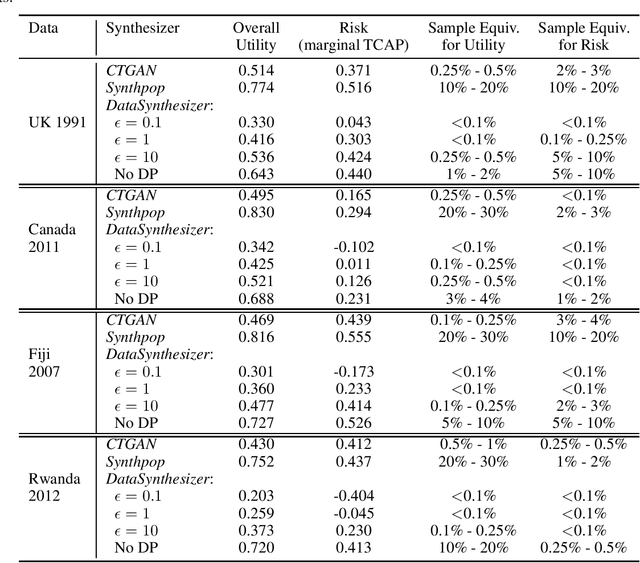
Most statistical agencies release randomly selected samples of Census microdata, usually with sample fractions under 10% and with other forms of statistical disclosure control (SDC) applied. An alternative to SDC is data synthesis, which has been attracting growing interest, yet there is no clear consensus on how to measure the associated utility and disclosure risk of the data. The ability to produce synthetic Census microdata, where the utility and associated risks are clearly understood, could mean that more timely and wider-ranging access to microdata would be possible. This paper follows on from previous work by the authors which mapped synthetic Census data on a risk-utility (R-U) map. The paper presents a framework to measure the utility and disclosure risk of synthetic data by comparing it to samples of the original data of varying sample fractions, thereby identifying the sample fraction which has equivalent utility and risk to the synthetic data. Three commonly used data synthesis packages are compared with some interesting results. Further work is needed in several directions but the methodology looks very promising.
Generative Adversarial Networks for Synthetic Data Generation: A Comparative Study
Dec 03, 2021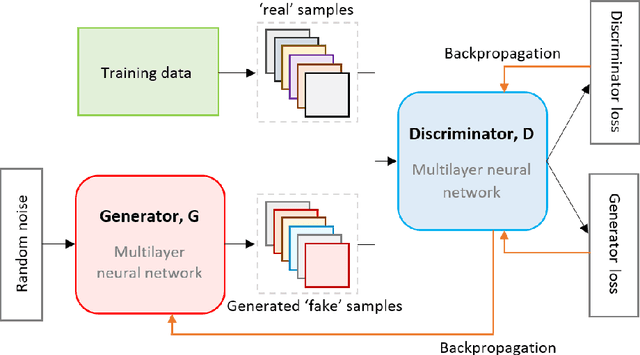
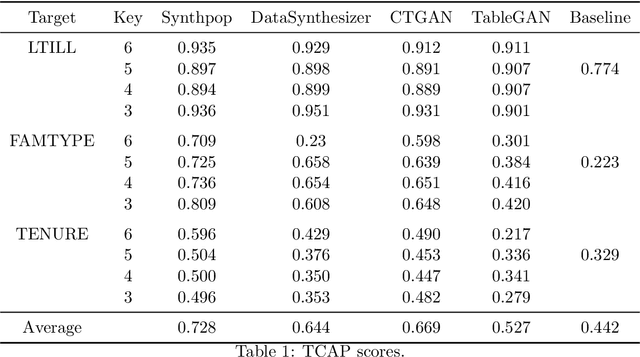
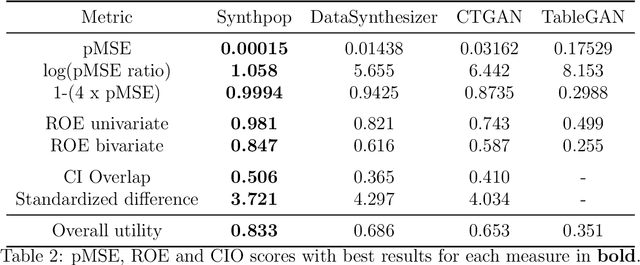
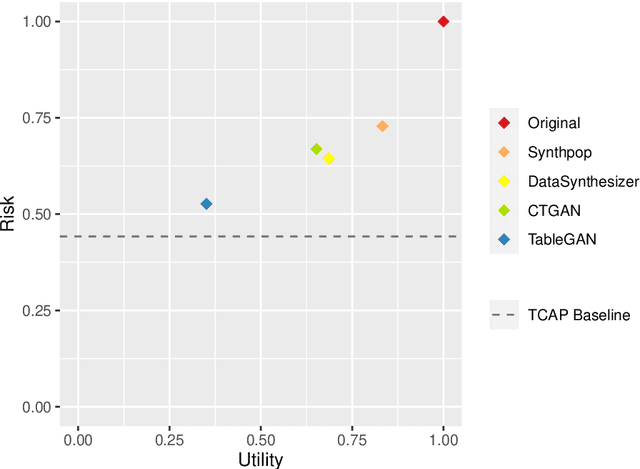
Generative Adversarial Networks (GANs) are gaining increasing attention as a means for synthesising data. So far much of this work has been applied to use cases outside of the data confidentiality domain with a common application being the production of artificial images. Here we consider the potential application of GANs for the purpose of generating synthetic census microdata. We employ a battery of utility metrics and a disclosure risk metric (the Targeted Correct Attribution Probability) to compare the data produced by tabular GANs with those produced using orthodox data synthesis methods.