Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks for Synthetic Data Generation: A Comparative Study
Dec 03, 2021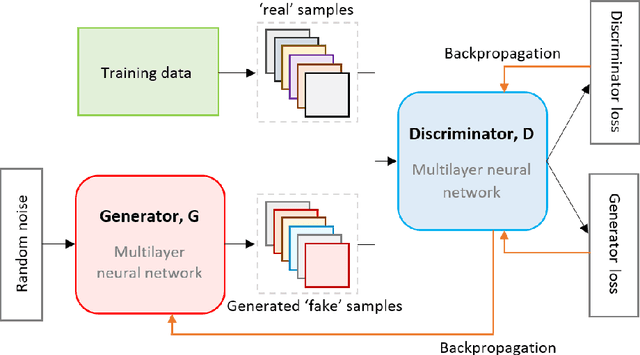
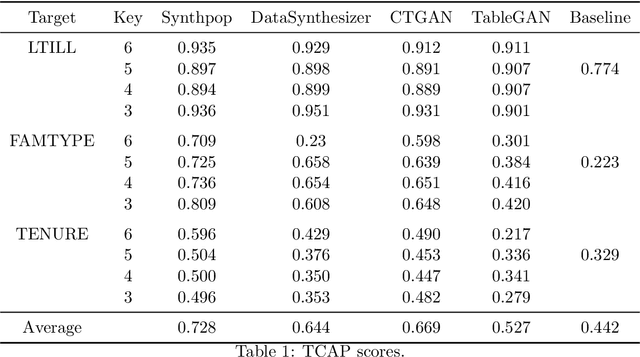
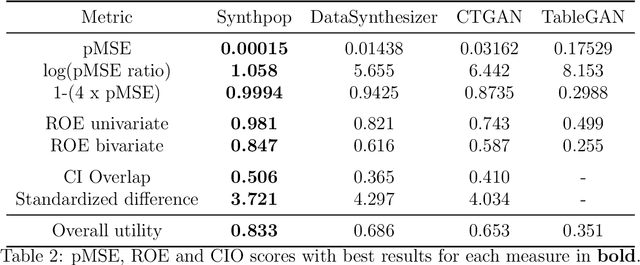
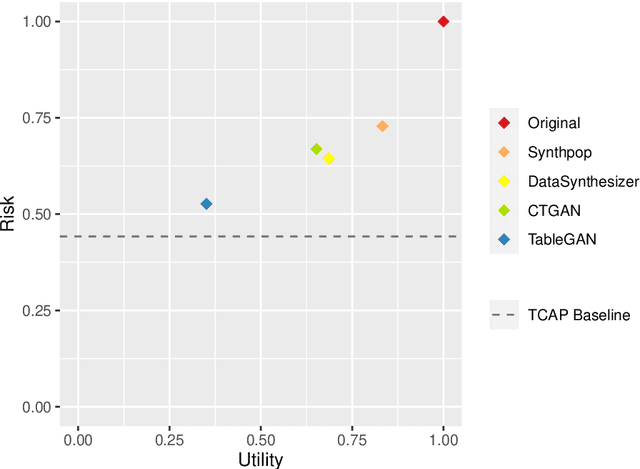
Generative Adversarial Networks (GANs) are gaining increasing attention as a means for synthesising data. So far much of this work has been applied to use cases outside of the data confidentiality domain with a common application being the production of artificial images. Here we consider the potential application of GANs for the purpose of generating synthetic census microdata. We employ a battery of utility metrics and a disclosure risk metric (the Targeted Correct Attribution Probability) to compare the data produced by tabular GANs with those produced using orthodox data synthesis methods.
Via