 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing the Utility and Disclosure Risk of Synthetic Data with Samples of Microdata
Paper and Code
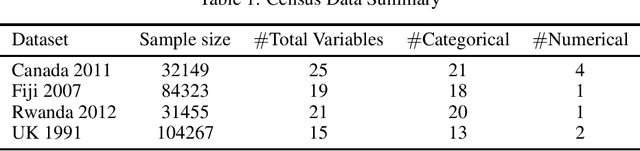
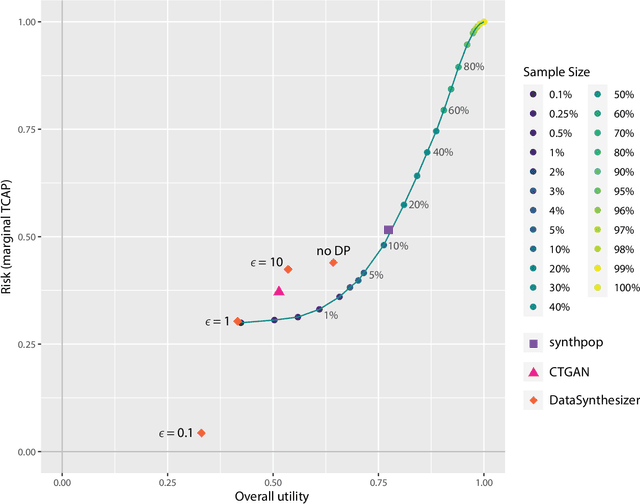
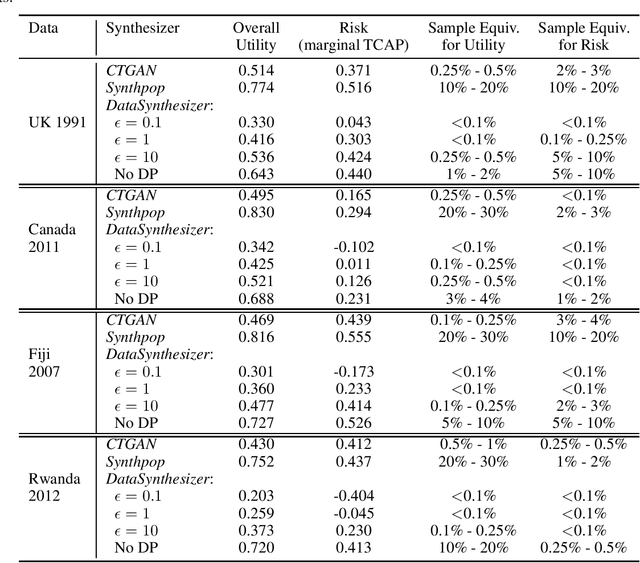
Most statistical agencies release randomly selected samples of Census microdata, usually with sample fractions under 10% and with other forms of statistical disclosure control (SDC) applied. An alternative to SDC is data synthesis, which has been attracting growing interest, yet there is no clear consensus on how to measure the associated utility and disclosure risk of the data. The ability to produce synthetic Census microdata, where the utility and associated risks are clearly understood, could mean that more timely and wider-ranging access to microdata would be possible. This paper follows on from previous work by the authors which mapped synthetic Census data on a risk-utility (R-U) map. The paper presents a framework to measure the utility and disclosure risk of synthetic data by comparing it to samples of the original data of varying sample fractions, thereby identifying the sample fraction which has equivalent utility and risk to the synthetic data. Three commonly used data synthesis packages are compared with some interesting results. Further work is needed in several directions but the methodology looks very promising.