 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbeWebAgent: Embedding Web Agents into Any Customized UI
Feb 16, 2026Most web agents operate at the human interface level, observing screenshots or raw DOM trees without application-level access, which limits robustness and action expressiveness. In enterprise settings, however, explicit control of both the frontend and backend is available. We present EmbeWebAgent, a framework for embedding agents directly into existing UIs using lightweight frontend hooks (curated ARIA and URL-based observations, and a per-page function registry exposed via a WebSocket) and a reusable backend workflow that performs reasoning and takes actions. EmbeWebAgent is stack-agnostic (e.g., React or Angular), supports mixed-granularity actions ranging from GUI primitives to higher-level composites, and orchestrates navigation, manipulation, and domain-specific analytics via MCP tools. Our demo shows minimal retrofitting effort and robust multi-step behaviors grounded in a live UI setting. Live Demo: https://youtu.be/Cy06Ljee1JQ
An adaptive approach to Bayesian Optimization with switching costs
May 14, 2024


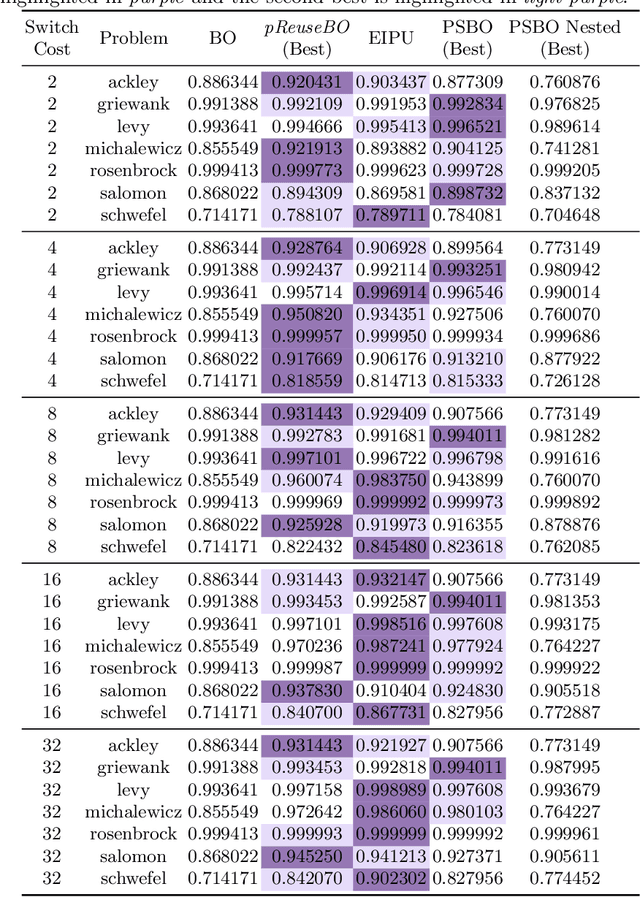
We investigate modifications to Bayesian Optimization for a resource-constrained setting of sequential experimental design where changes to certain design variables of the search space incur a switching cost. This models the scenario where there is a trade-off between evaluating more while maintaining the same setup, or switching and restricting the number of possible evaluations due to the incurred cost. We adapt two process-constrained batch algorithms to this sequential problem formulation, and propose two new methods: one cost-aware and one cost-ignorant. We validate and compare the algorithms using a set of 7 scalable test functions in different dimensionalities and switching-cost settings for 30 total configurations. Our proposed cost-aware hyperparameter-free algorithm yields comparable results to tuned process-constrained algorithms in all settings we considered, suggesting some degree of robustness to varying landscape features and cost trade-offs. This method starts to outperform the other algorithms with increasing switching-cost. Our work broadens out from other recent Bayesian Optimization studies in resource-constrained settings that consider a batch setting only. While the contributions of this work are relevant to the general class of resource-constrained problems, they are particularly relevant to problems where adaptability to varying resource availability is of high importance
A Principled Method for the Creation of Synthetic Multi-fidelity Data Sets
Aug 26, 2022
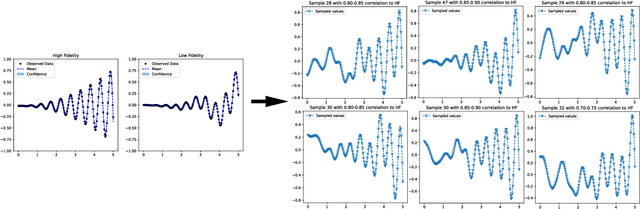
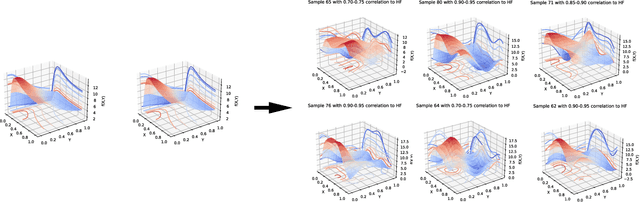
Multifidelity and multioutput optimisation algorithms are of active interest in many areas of computational design as they allow cheaper computational proxies to be used intelligently to aid experimental searches for high-performing species. Characterisation of these algorithms involves benchmarks that typically either use analytic functions or existing multifidelity datasets. However, analytic functions are often not representative of relevant problems, while preexisting datasets do not allow systematic investigation of the influence of characteristics of the lower fidelity proxies. To bridge this gap, we present a methodology for systematic generation of synthetic fidelities derived from preexisting datasets. This allows for the construction of benchmarks that are both representative of practical optimisation problems while also allowing systematic investigation of the influence of the lower fidelity proxies.
Powerful, transferable representations for molecules through intelligent task selection in deep multitask networks
Sep 17, 2018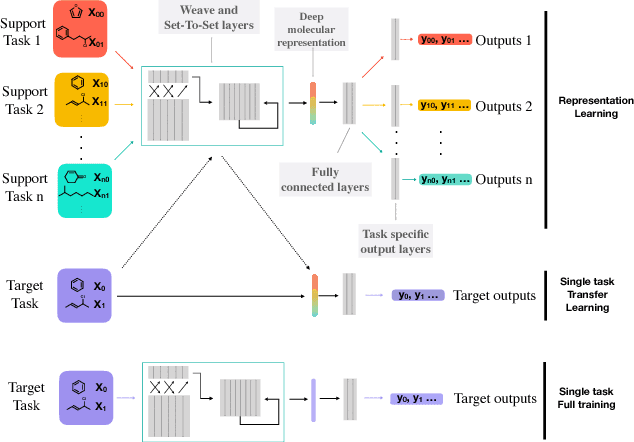

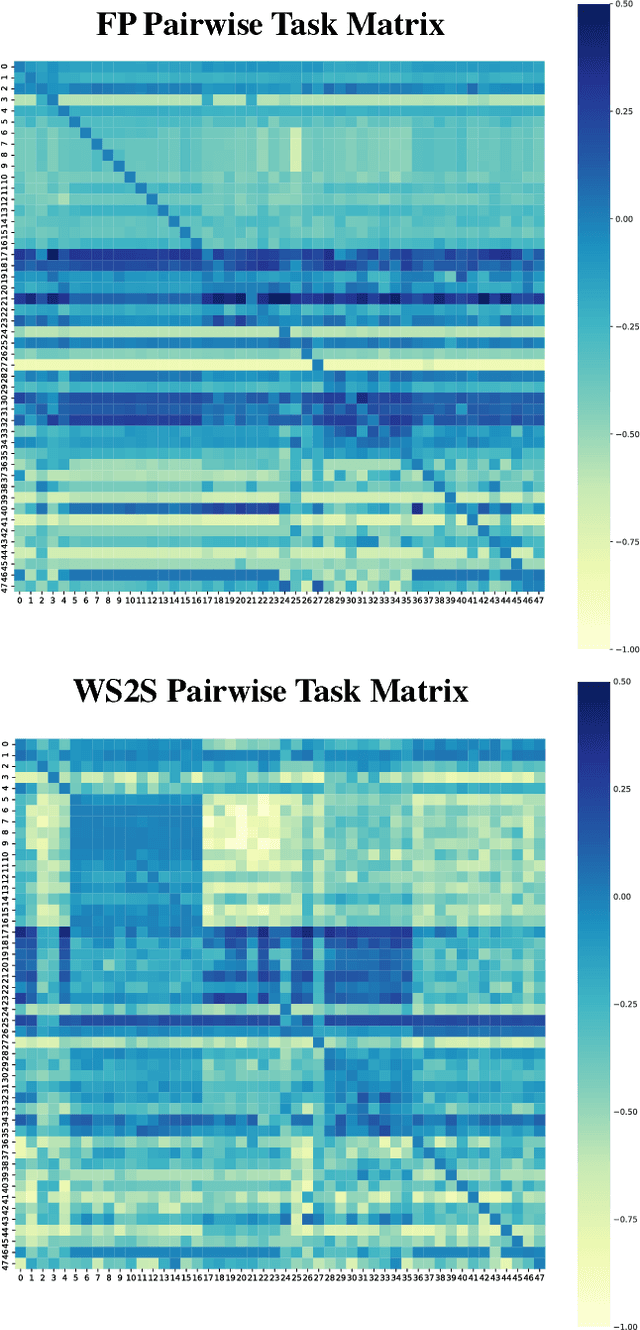
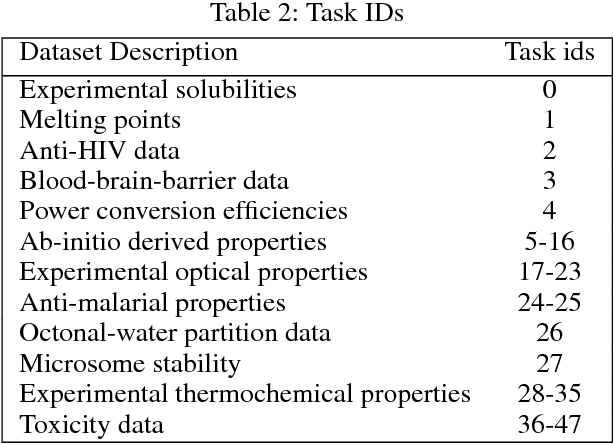
Chemical representations derived from deep learning are emerging as a powerful tool in areas such as drug discovery and materials innovation. Currently, this methodology has three major limitations - the cost of representation generation, risk of inherited bias, and the requirement for large amounts of data. We propose the use of multi-task learning in tandem with transfer learning to address these limitations directly. In order to avoid introducing unknown bias into multi-task learning through the task selection itself, we calculate task similarity through pairwise task affinity, and use this measure to programmatically select tasks. We test this methodology on several real-world data sets to demonstrate its potential for execution in complex and low-data environments. Finally, we utilise the task similarity to further probe the expressiveness of the learned representation through a comparison to a commonly used cheminformatics fingerprint, and show that the deep representation is able to capture more expressive task-based information.