 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmyx: Fast and efficient all-atom protein generation
Jun 12, 2026Computational enzyme design requires generating proteins that scaffold catalytic residues and ligands, a task that demands both geometric accuracy and structural diversity from the underlying generative model. Current all-atom generators inherit expensive architectures from structure prediction, leading to high training costs and limited sample diversity. We argue that much of this complexity is unnecessary for generators, which condition on sparse geometric constraints rather than rich co-evolutionary signals. Emyx is a 140M-parameter conditional flow matching model that concentrates capacity within standard transformer blocks, replacing heavy embedding stacks with lightweight conditional representations and sparse connectivity. We additionally derive an exact reparametrisation of the flow matching interpolant into the EDM noise-level framework, bridging flow matching training efficiency with state-of-the-art sampling methods designed for diffusion models without retraining. Despite being the smallest model, Emyx outperforms both Proteína-Complexa and RFdiffusion3 against the AME enzyme design benchmark across success rate under strict evaluation requiring both global fold recovery and catalytic geometry accuracy, structural novelty, scaffold diversity, and geometric validity, while training in just $682$ GPU-hours, roughly $4\times$ less than RFdiffusion3.
Refining embeddings with fill-tuning: data-efficient generalised performance improvements for materials foundation models
Feb 19, 2025
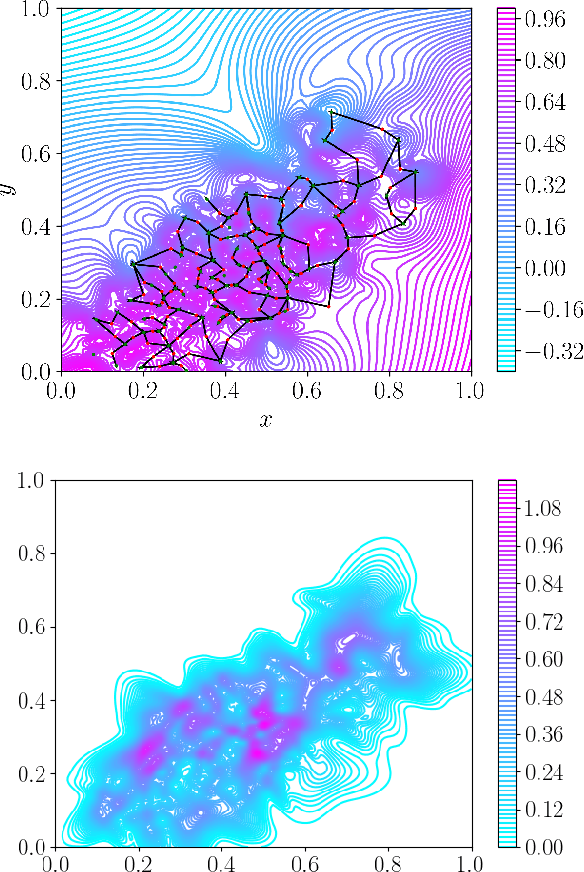

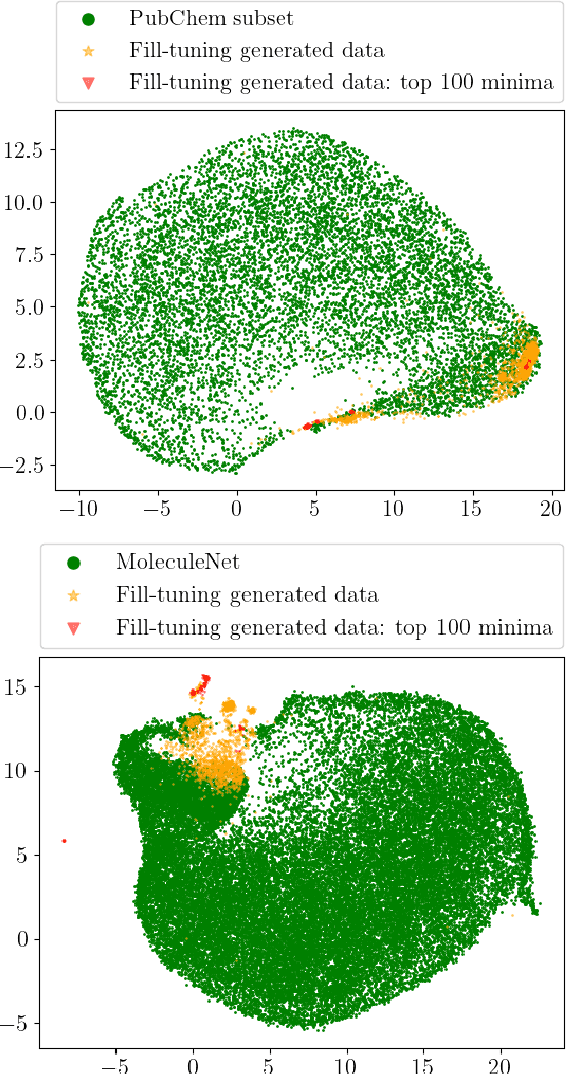
Pretrained foundation models learn embeddings that can be used for a wide range of downstream tasks. These embeddings optimise general performance, and if insufficiently accurate at a specific task the model can be fine-tuned to improve performance. For all current methodologies this operation necessarily degrades performance on all out-of-distribution tasks. In this work we present 'fill-tuning', a novel methodology to generate datasets for continued pretraining of foundation models that are not suited to a particular downstream task, but instead aim to correct poor regions of the embedding. We present the application of roughness analysis to latent space topologies and illustrate how it can be used to propose data that will be most valuable to improving the embedding. We apply fill-tuning to a set of state-of-the-art materials foundation models trained on $O(10^9)$ data points and show model improvement of almost 1% in all downstream tasks with the addition of only 100 data points. This method provides a route to the general improvement of foundation models at the computational cost of fine-tuning.
Hessian QM9: A quantum chemistry database of molecular Hessians in implicit solvents
Aug 15, 2024



A significant challenge in computational chemistry is developing approximations that accelerate \emph{ab initio} methods while preserving accuracy. Machine learning interatomic potentials (MLIPs) have emerged as a promising solution for constructing atomistic potentials that can be transferred across different molecular and crystalline systems. Most MLIPs are trained only on energies and forces in vacuum, while an improved description of the potential energy surface could be achieved by including the curvature of the potential energy surface. We present Hessian QM9, the first database of equilibrium configurations and numerical Hessian matrices, consisting of 41,645 molecules from the QM9 dataset at the $\omega$B97x/6-31G* level. Molecular Hessians were calculated in vacuum, as well as water, tetrahydrofuran, and toluene using an implicit solvation model. To demonstrate the utility of this dataset, we show that incorporating second derivatives of the potential energy surface into the loss function of a MLIP significantly improves the prediction of vibrational frequencies in all solvent environments, thus making this dataset extremely useful for studying organic molecules in realistic solvent environments for experimental characterization.
Physics Inspired Approaches Towards Understanding Gaussian Processes
May 18, 2023Prior beliefs about the latent function to shape inductive biases can be incorporated into a Gaussian Process (GP) via the kernel. However, beyond kernel choices, the decision-making process of GP models remains poorly understood. In this work, we contribute an analysis of the loss landscape for GP models using methods from physics. We demonstrate $\nu$-continuity for Matern kernels and outline aspects of catastrophe theory at critical points in the loss landscape. By directly including $\nu$ in the hyperparameter optimisation for Matern kernels, we find that typical values of $\nu$ are far from optimal in terms of performance, yet prevail in the literature due to the increased computational speed. We also provide an a priori method for evaluating the effect of GP ensembles and discuss various voting approaches based on physical properties of the loss landscape. The utility of these approaches is demonstrated for various synthetic and real datasets. Our findings provide an enhanced understanding of the decision-making process behind GPs and offer practical guidance for improving their performance and interpretability in a range of applications.
A Principled Method for the Creation of Synthetic Multi-fidelity Data Sets
Aug 26, 2022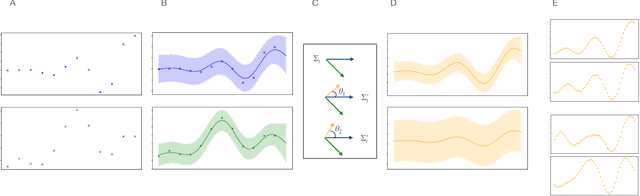
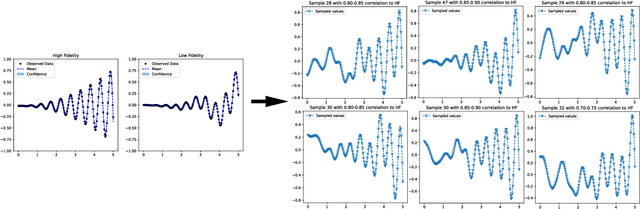
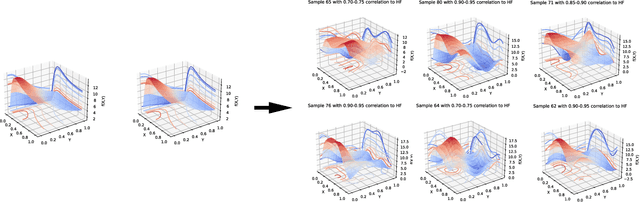
Multifidelity and multioutput optimisation algorithms are of active interest in many areas of computational design as they allow cheaper computational proxies to be used intelligently to aid experimental searches for high-performing species. Characterisation of these algorithms involves benchmarks that typically either use analytic functions or existing multifidelity datasets. However, analytic functions are often not representative of relevant problems, while preexisting datasets do not allow systematic investigation of the influence of characteristics of the lower fidelity proxies. To bridge this gap, we present a methodology for systematic generation of synthetic fidelities derived from preexisting datasets. This allows for the construction of benchmarks that are both representative of practical optimisation problems while also allowing systematic investigation of the influence of the lower fidelity proxies.
Self-focusing virtual screening with active design space pruning
May 03, 2022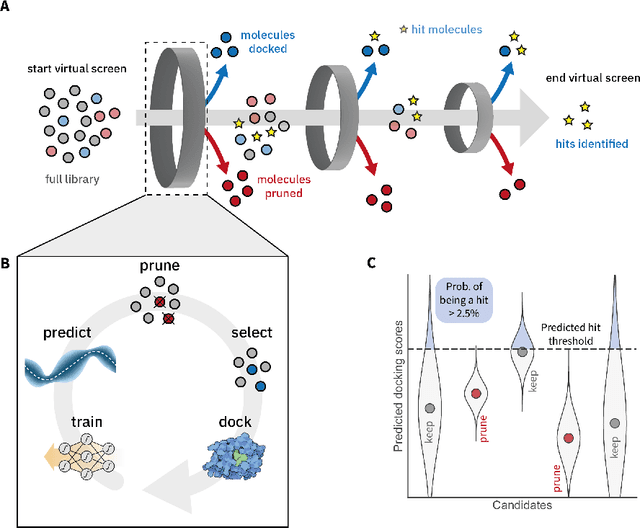
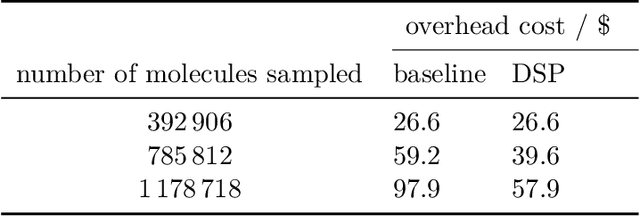
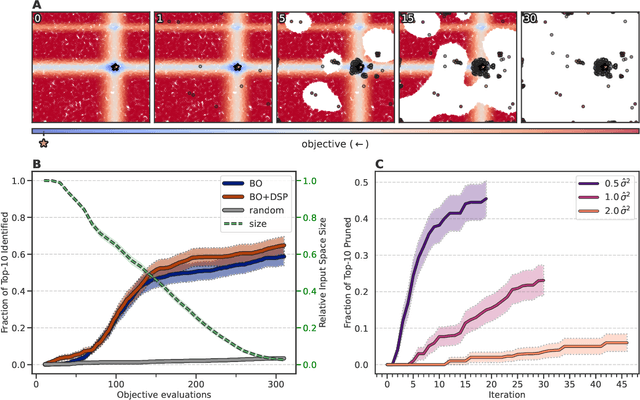
High-throughput virtual screening is an indispensable technique utilized in the discovery of small molecules. In cases where the library of molecules is exceedingly large, the cost of an exhaustive virtual screen may be prohibitive. Model-guided optimization has been employed to lower these costs through dramatic increases in sample efficiency compared to random selection. However, these techniques introduce new costs to the workflow through the surrogate model training and inference steps. In this study, we propose an extension to the framework of model-guided optimization that mitigates inferences costs using a technique we refer to as design space pruning (DSP), which irreversibly removes poor-performing candidates from consideration. We study the application of DSP to a variety of optimization tasks and observe significant reductions in overhead costs while exhibiting similar performance to the baseline optimization. DSP represents an attractive extension of model-guided optimization that can limit overhead costs in optimization settings where these costs are non-negligible relative to objective costs, such as docking.
Using Bayesian Optimization to Accelerate Virtual Screening for the Discovery of Therapeutics Appropriate for Repurposing for COVID-19
May 11, 2020
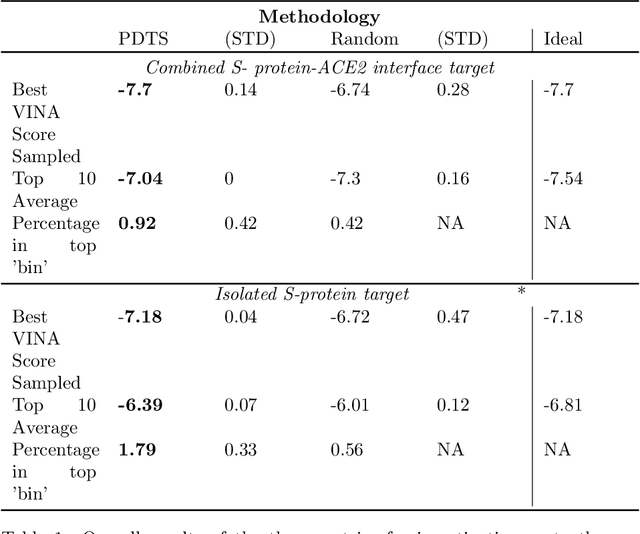
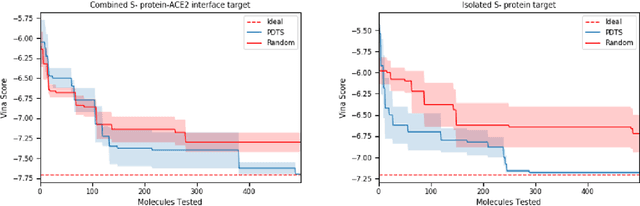

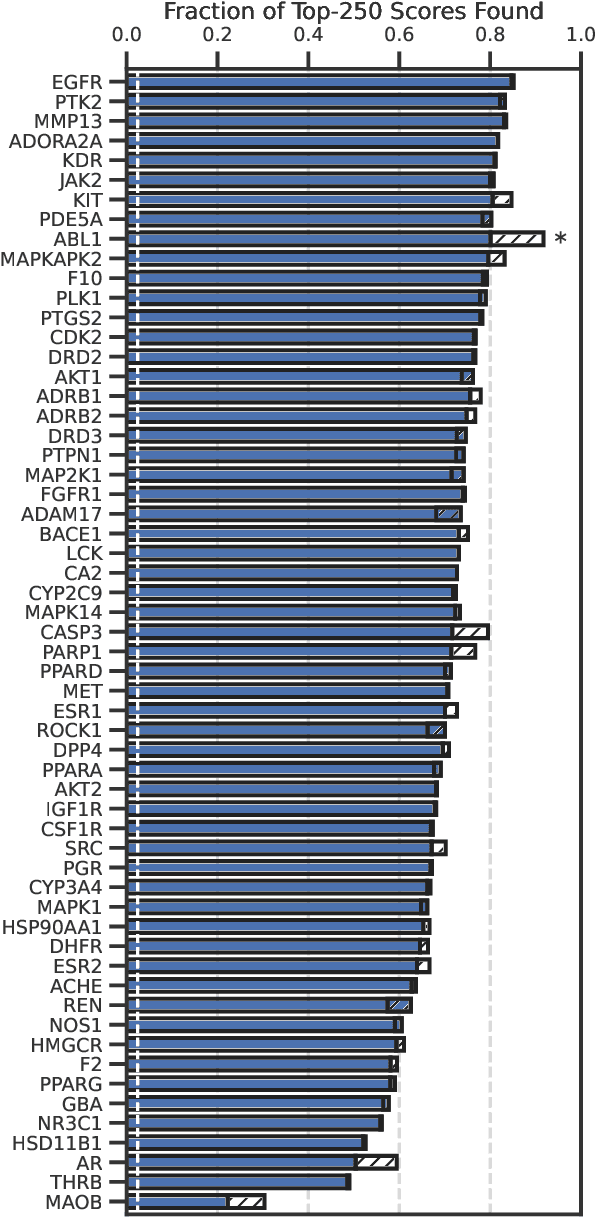
The novel Wuhan coronavirus known as SARS-CoV-2 has brought almost unprecedented effects for a non-wartime setting, hitting social, economic and health systems hard.~ Being able to bring to bear pharmaceutical interventions to counteract its effects will represent a major turning point in the fight to turn the tides in this ongoing battle.~ Recently, the World's most powerful supercomputer, SUMMIT, was used to identify existing small molecule pharmaceuticals which may have the desired activity against SARS-CoV-2 through a high throughput virtual screening approach. In this communication, we demonstrate how the use of Bayesian optimization can provide a valuable service for the prioritisation of these calculations, leading to the accelerated identification of high-performing candidates, and thus expanding the scope of the utility of HPC systems for time critical screening
Privacy-Preserving Gaussian Process Regression -- A Modular Approach to the Application of Homomorphic Encryption
Jan 28, 2020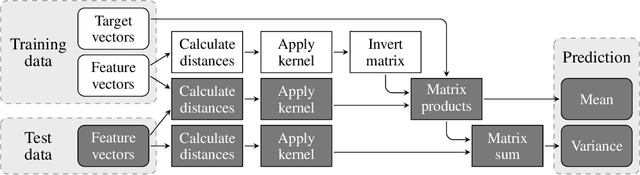
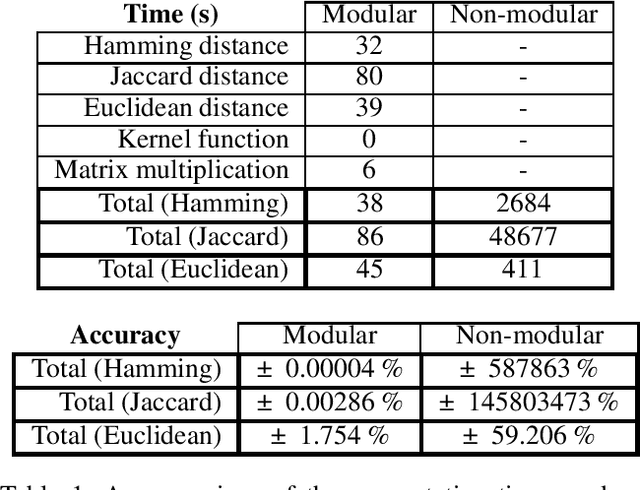
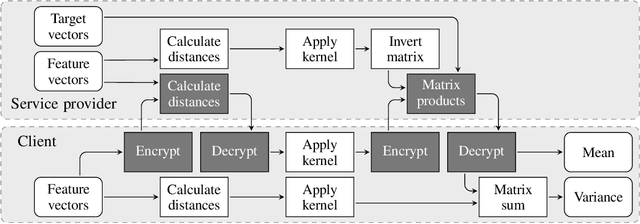
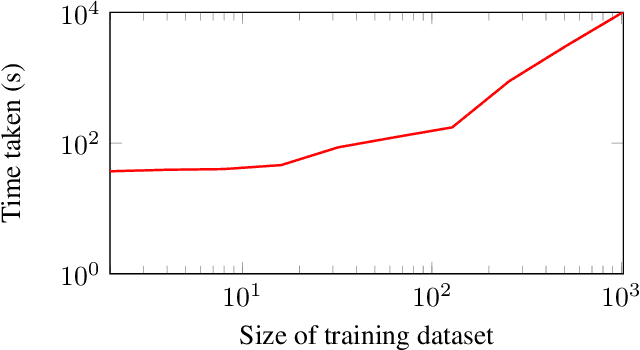
Much of machine learning relies on the use of large amounts of data to train models to make predictions. When this data comes from multiple sources, for example when evaluation of data against a machine learning model is offered as a service, there can be privacy issues and legal concerns over the sharing of data. Fully homomorphic encryption (FHE) allows data to be computed on whilst encrypted, which can provide a solution to the problem of data privacy. However, FHE is both slow and restrictive, so existing algorithms must be manipulated to make them work efficiently under the FHE paradigm. Some commonly used machine learning algorithms, such as Gaussian process regression, are poorly suited to FHE and cannot be manipulated to work both efficiently and accurately. In this paper, we show that a modular approach, which applies FHE to only the sensitive steps of a workflow that need protection, allows one party to make predictions on their data using a Gaussian process regression model built from another party's data, without either party gaining access to the other's data, in a way which is both accurate and efficient. This construction is, to our knowledge, the first example of an effectively encrypted Gaussian process.
Fully Bayesian Recurrent Neural Networks for Safe Reinforcement Learning
Nov 26, 2019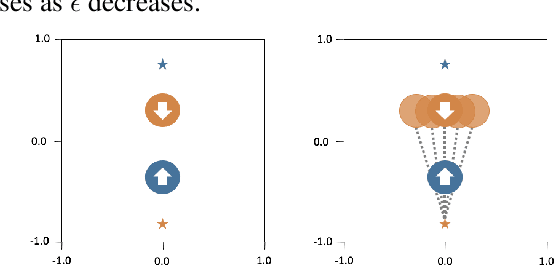


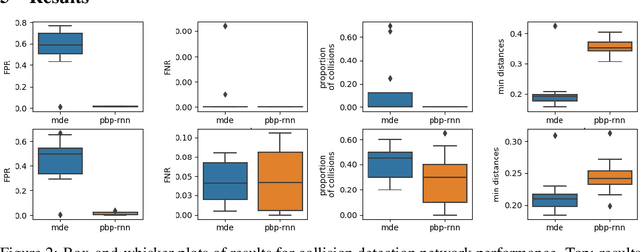
Reinforcement Learning (RL) has demonstrated state-of-the-art results in a number of autonomous system applications, however many of the underlying algorithms rely on black-box predictions. This results in poor explainability of the behaviour of these systems, raising concerns as to their use in safety-critical applications. Recent work has demonstrated that uncertainty-aware models exhibit more cautious behaviours through the incorporation of model uncertainty estimates. In this work, we build on Probabilistic Backpropagation to introduce a fully Bayesian Recurrent Neural Network architecture. We apply this within a Safe RL scenario, and demonstrate that the proposed method significantly outperforms a popular approach for obtaining model uncertainties in collision avoidance tasks. Furthermore, we demonstrate that the proposed approach requires less training and is far more efficient than the current leading method, both in terms of compute resource and memory footprint.
Efficient and Scalable Batch Bayesian Optimization Using K-Means
Sep 19, 2018
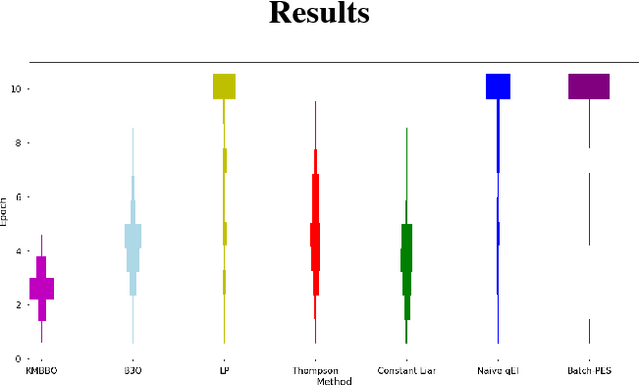

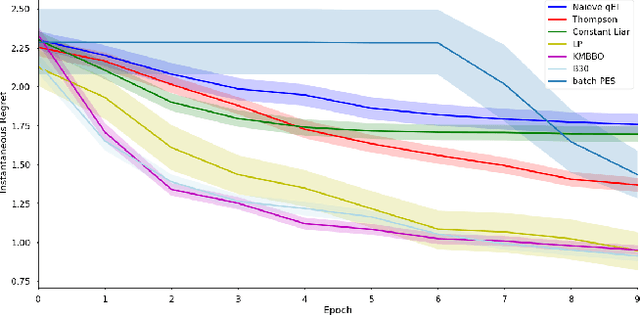
We present K-Means Batch Bayesian Optimization (KMBBO), a novel batch sampling algorithm for Bayesian Optimization (BO). KMBBO uses unsupervised learning to efficiently estimate peaks of the model acquisition function. We show in empirical experiments that our method outperforms the current state-of-the-art batch allocation algorithms on a variety of test problems including tuning of algorithm hyper-parameters and a challenging drug discovery problem. In order to accommodate the real-world problem of high dimensional data, we propose a modification to KMBBO by combining it with compressed sensing to project the optimization into a lower dimensional subspace. We demonstrate empirically that this 2-step method outperforms algorithms where no dimensionality reduction has taken place.