 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining embeddings with fill-tuning: data-efficient generalised performance improvements for materials foundation models
Paper and Code
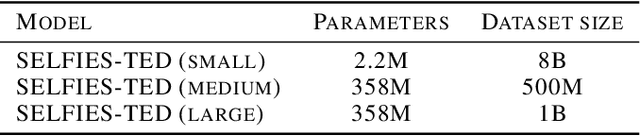
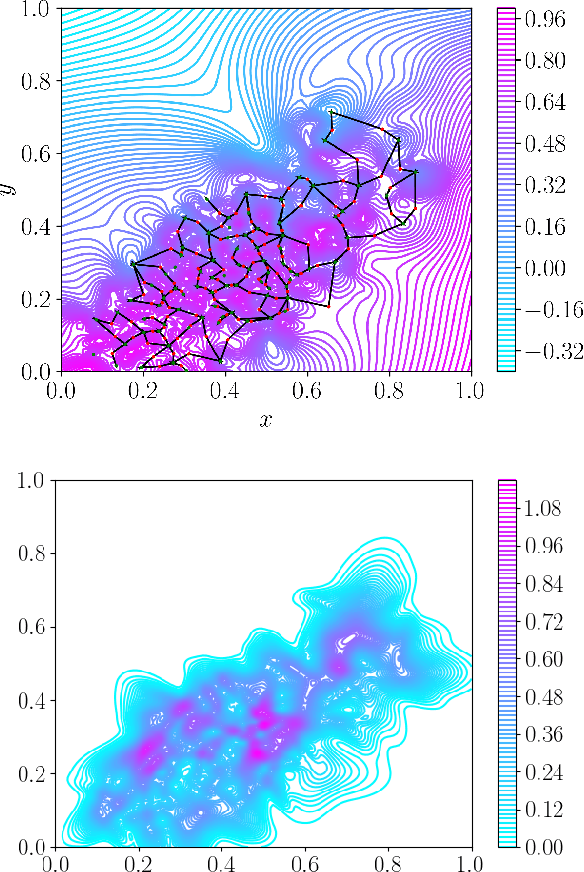

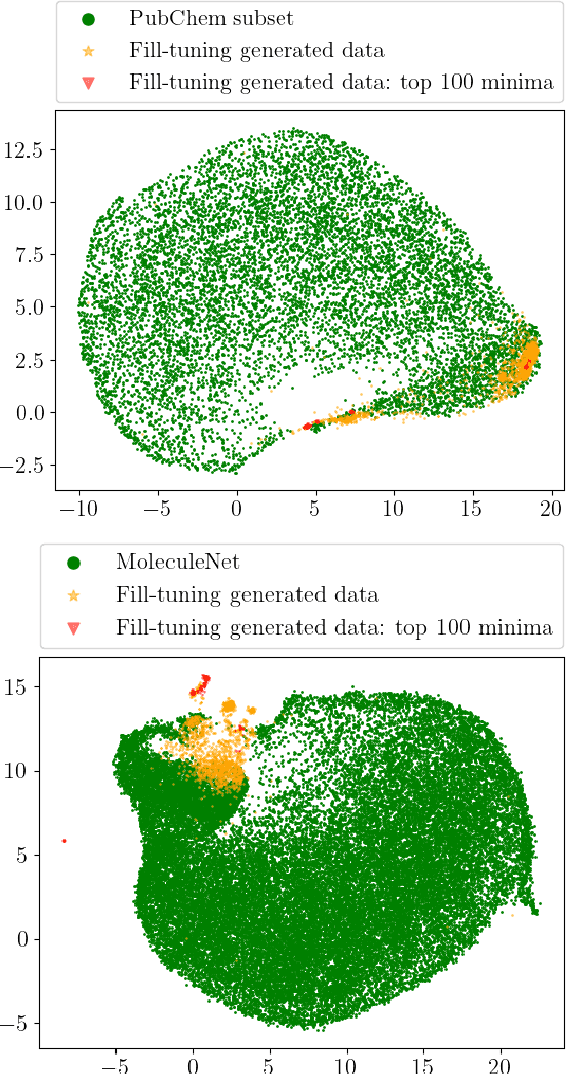
Pretrained foundation models learn embeddings that can be used for a wide range of downstream tasks. These embeddings optimise general performance, and if insufficiently accurate at a specific task the model can be fine-tuned to improve performance. For all current methodologies this operation necessarily degrades performance on all out-of-distribution tasks. In this work we present 'fill-tuning', a novel methodology to generate datasets for continued pretraining of foundation models that are not suited to a particular downstream task, but instead aim to correct poor regions of the embedding. We present the application of roughness analysis to latent space topologies and illustrate how it can be used to propose data that will be most valuable to improving the embedding. We apply fill-tuning to a set of state-of-the-art materials foundation models trained on $O(10^9)$ data points and show model improvement of almost 1% in all downstream tasks with the addition of only 100 data points. This method provides a route to the general improvement of foundation models at the computational cost of fine-tuning.