 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining embeddings with fill-tuning: data-efficient generalised performance improvements for materials foundation models
Feb 19, 2025
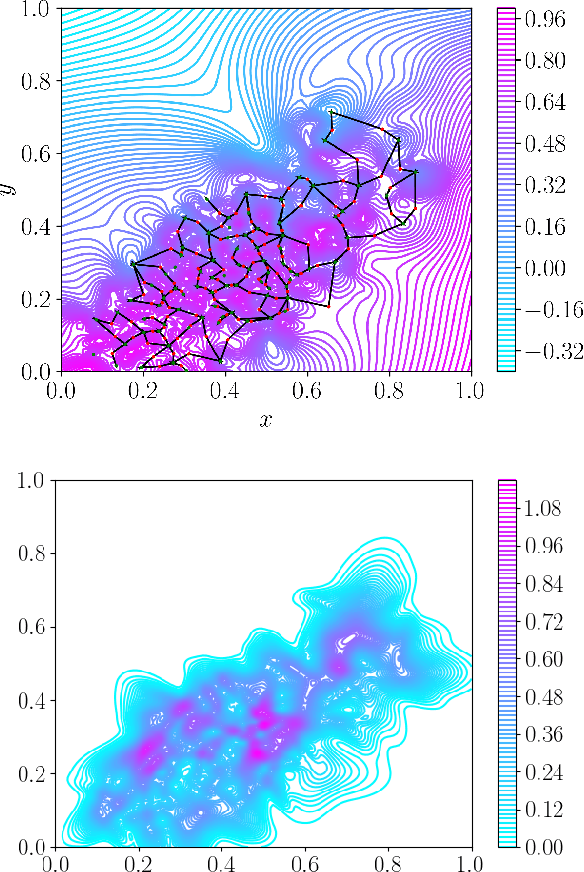

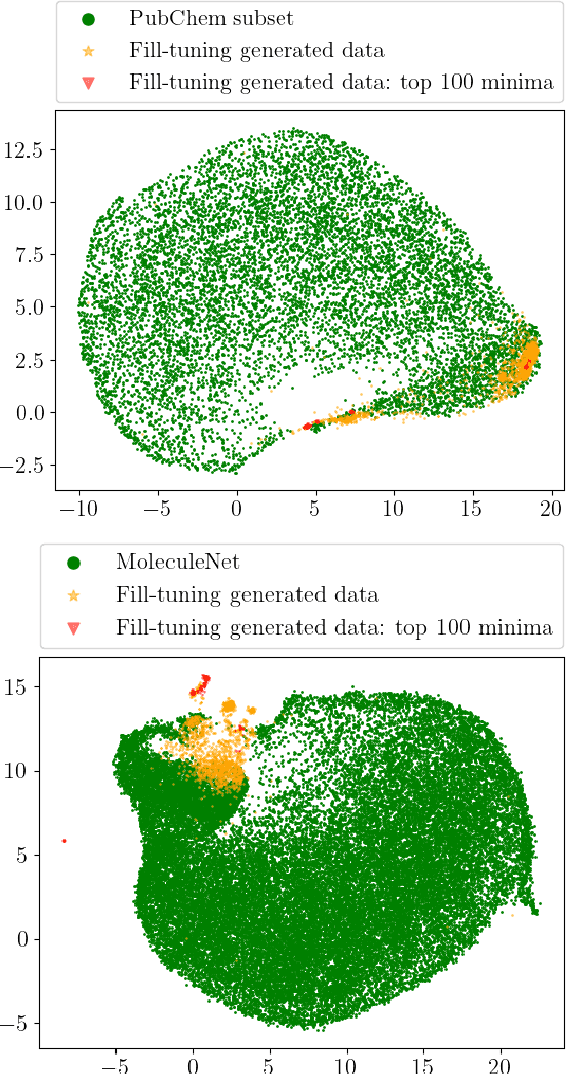
Pretrained foundation models learn embeddings that can be used for a wide range of downstream tasks. These embeddings optimise general performance, and if insufficiently accurate at a specific task the model can be fine-tuned to improve performance. For all current methodologies this operation necessarily degrades performance on all out-of-distribution tasks. In this work we present 'fill-tuning', a novel methodology to generate datasets for continued pretraining of foundation models that are not suited to a particular downstream task, but instead aim to correct poor regions of the embedding. We present the application of roughness analysis to latent space topologies and illustrate how it can be used to propose data that will be most valuable to improving the embedding. We apply fill-tuning to a set of state-of-the-art materials foundation models trained on $O(10^9)$ data points and show model improvement of almost 1% in all downstream tasks with the addition of only 100 data points. This method provides a route to the general improvement of foundation models at the computational cost of fine-tuning.
Evolution of $K$-means solution landscapes with the addition of dataset outliers and a robust clustering comparison measure for their analysis
Jun 25, 2023The $K$-means algorithm remains one of the most widely-used clustering methods due to its simplicity and general utility. The performance of $K$-means depends upon location of minima low in cost function, amongst a potentially vast number of solutions. Here, we use the energy landscape approach to map the change in $K$-means solution space as a result of increasing dataset outliers and show that the cost function surface becomes more funnelled. Kinetic analysis reveals that in all cases the overall funnel is composed of shallow locally-funnelled regions, each of which are separated by areas that do not support any clustering solutions. These shallow regions correspond to different types of clustering solution and their increasing number with outliers leads to longer pathways within the funnel and a reduced correlation between accuracy and cost function. Finally, we propose that the rates obtained from kinetic analysis provide a novel measure of clustering similarity that incorporates information about the paths between them. This measure is robust to outliers and we illustrate the application to datasets containing multiple outliers.
Physics Inspired Approaches Towards Understanding Gaussian Processes
May 18, 2023Prior beliefs about the latent function to shape inductive biases can be incorporated into a Gaussian Process (GP) via the kernel. However, beyond kernel choices, the decision-making process of GP models remains poorly understood. In this work, we contribute an analysis of the loss landscape for GP models using methods from physics. We demonstrate $\nu$-continuity for Matern kernels and outline aspects of catastrophe theory at critical points in the loss landscape. By directly including $\nu$ in the hyperparameter optimisation for Matern kernels, we find that typical values of $\nu$ are far from optimal in terms of performance, yet prevail in the literature due to the increased computational speed. We also provide an a priori method for evaluating the effect of GP ensembles and discuss various voting approaches based on physical properties of the loss landscape. The utility of these approaches is demonstrated for various synthetic and real datasets. Our findings provide an enhanced understanding of the decision-making process behind GPs and offer practical guidance for improving their performance and interpretability in a range of applications.