 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
No Modality Left Behind: Adapting to Missing Modalities via Knowledge Distillation for Brain Tumor Segmentation
Sep 18, 2025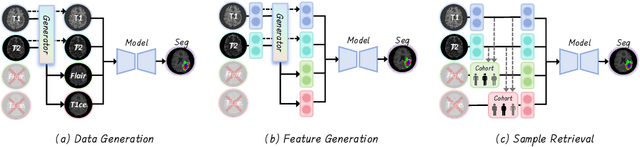
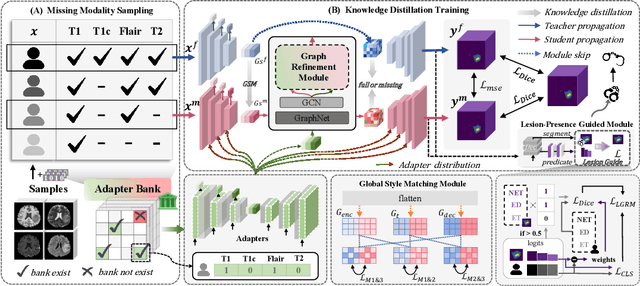
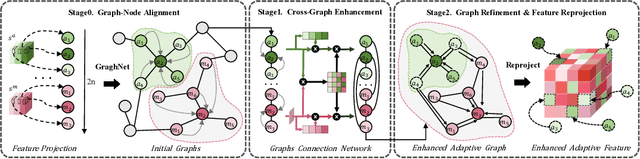
Accurate brain tumor segmentation is essential for preoperative evaluation and personalized treatment. Multi-modal MRI is widely used due to its ability to capture complementary tumor features across different sequences. However, in clinical practice, missing modalities are common, limiting the robustness and generalizability of existing deep learning methods that rely on complete inputs, especially under non-dominant modality combinations. To address this, we propose AdaMM, a multi-modal brain tumor segmentation framework tailored for missing-modality scenarios, centered on knowledge distillation and composed of three synergistic modules. The Graph-guided Adaptive Refinement Module explicitly models semantic associations between generalizable and modality-specific features, enhancing adaptability to modality absence. The Bi-Bottleneck Distillation Module transfers structural and textural knowledge from teacher to student models via global style matching and adversarial feature alignment. The Lesion-Presence-Guided Reliability Module predicts prior probabilities of lesion types through an auxiliary classification task, effectively suppressing false positives under incomplete inputs. Extensive experiments on the BraTS 2018 and 2024 datasets demonstrate that AdaMM consistently outperforms existing methods, exhibiting superior segmentation accuracy and robustness, particularly in single-modality and weak-modality configurations. In addition, we conduct a systematic evaluation of six categories of missing-modality strategies, confirming the superiority of knowledge distillation and offering practical guidance for method selection and future research. Our source code is available at https://github.com/Quanato607/AdaMM.
Bridging the Gap in Missing Modalities: Leveraging Knowledge Distillation and Style Matching for Brain Tumor Segmentation
Jul 30, 2025Accurate and reliable brain tumor segmentation, particularly when dealing with missing modalities, remains a critical challenge in medical image analysis. Previous studies have not fully resolved the challenges of tumor boundary segmentation insensitivity and feature transfer in the absence of key imaging modalities. In this study, we introduce MST-KDNet, aimed at addressing these critical issues. Our model features Multi-Scale Transformer Knowledge Distillation to effectively capture attention weights at various resolutions, Dual-Mode Logit Distillation to improve the transfer of knowledge, and a Global Style Matching Module that integrates feature matching with adversarial learning. Comprehensive experiments conducted on the BraTS and FeTS 2024 datasets demonstrate that MST-KDNet surpasses current leading methods in both Dice and HD95 scores, particularly in conditions with substantial modality loss. Our approach shows exceptional robustness and generalization potential, making it a promising candidate for real-world clinical applications. Our source code is available at https://github.com/Quanato607/MST-KDNet.
* 11 pages, 2 figures
SCJD: Sparse Correlation and Joint Distillation for Efficient 3D Human Pose Estimation
Mar 18, 2025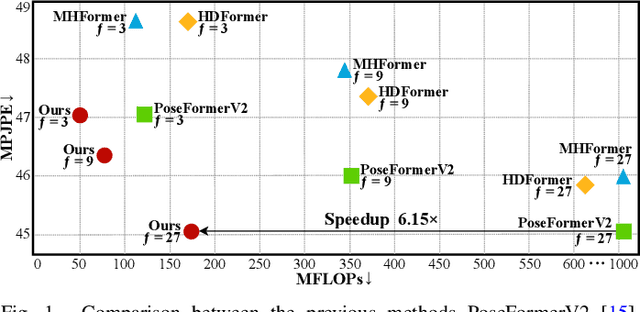
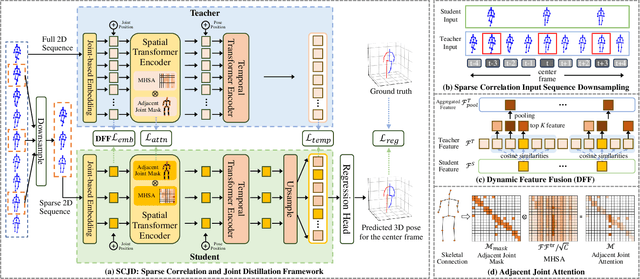
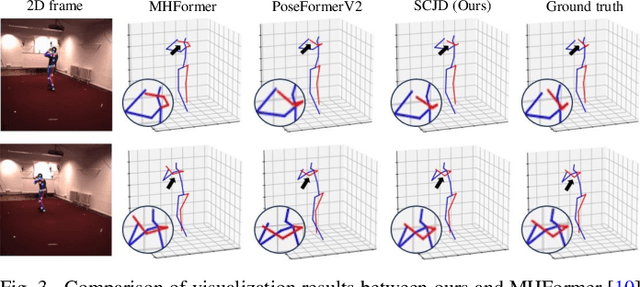
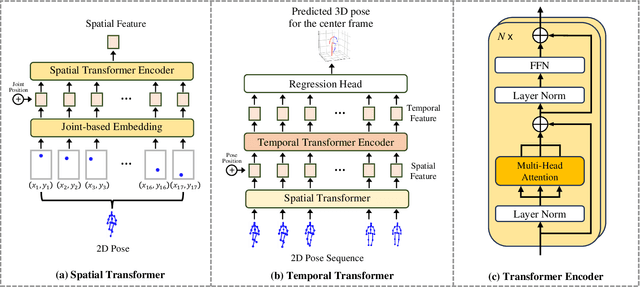
Existing 3D Human Pose Estimation (HPE) methods achieve high accuracy but suffer from computational overhead and slow inference, while knowledge distillation methods fail to address spatial relationships between joints and temporal correlations in multi-frame inputs. In this paper, we propose Sparse Correlation and Joint Distillation (SCJD), a novel framework that balances efficiency and accuracy for 3D HPE. SCJD introduces Sparse Correlation Input Sequence Downsampling to reduce redundancy in student network inputs while preserving inter-frame correlations. For effective knowledge transfer, we propose Dynamic Joint Spatial Attention Distillation, which includes Dynamic Joint Embedding Distillation to enhance the student's feature representation using the teacher's multi-frame context feature, and Adjacent Joint Attention Distillation to improve the student network's focus on adjacent joint relationships for better spatial understanding. Additionally, Temporal Consistency Distillation aligns the temporal correlations between teacher and student networks through upsampling and global supervision. Extensive experiments demonstrate that SCJD achieves state-of-the-art performance. Code is available at https://github.com/wileychan/SCJD.
XLSTM-HVED: Cross-Modal Brain Tumor Segmentation and MRI Reconstruction Method Using Vision XLSTM and Heteromodal Variational Encoder-Decoder
Dec 09, 2024



Neurogliomas are among the most aggressive forms of cancer, presenting considerable challenges in both treatment and monitoring due to their unpredictable biological behavior. Magnetic resonance imaging (MRI) is currently the preferred method for diagnosing and monitoring gliomas. However, the lack of specific imaging techniques often compromises the accuracy of tumor segmentation during the imaging process. To address this issue, we introduce the XLSTM-HVED model. This model integrates a hetero-modal encoder-decoder framework with the Vision XLSTM module to reconstruct missing MRI modalities. By deeply fusing spatial and temporal features, it enhances tumor segmentation performance. The key innovation of our approach is the Self-Attention Variational Encoder (SAVE) module, which improves the integration of modal features. Additionally, it optimizes the interaction of features between segmentation and reconstruction tasks through the Squeeze-Fusion-Excitation Cross Awareness (SFECA) module. Our experiments using the BraTS 2024 dataset demonstrate that our model significantly outperforms existing advanced methods in handling cases where modalities are missing. Our source code is available at https://github.com/Quanato607/XLSTM-HVED.