 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMSN and FAROS: OCTA Microstructure Segmentation Network and Fully Annotated Retinal OCTA Segmentation Dataset
Dec 26, 2022



The lack of efficient segmentation methods and fully-labeled datasets limits the comprehensive assessment of optical coherence tomography angiography (OCTA) microstructures like retinal vessel network (RVN) and foveal avascular zone (FAZ), which are of great value in ophthalmic and systematic diseases evaluation. Here, we introduce an innovative OCTA microstructure segmentation network (OMSN) by combining an encoder-decoder-based architecture with multi-scale skip connections and the split-attention-based residual network ResNeSt, paying specific attention to OCTA microstructural features while facilitating better model convergence and feature representations. The proposed OMSN achieves excellent single/multi-task performances for RVN or/and FAZ segmentation. Especially, the evaluation metrics on multi-task models outperform single-task models on the same dataset. On this basis, a fully annotated retinal OCTA segmentation (FAROS) dataset is constructed semi-automatically, filling the vacancy of a pixel-level fully-labeled OCTA dataset. OMSN multi-task segmentation model retrained with FAROS further certifies its outstanding accuracy for simultaneous RVN and FAZ segmentation.
Robust Face Recognition with Deeply Normalized Depth Images
May 01, 2018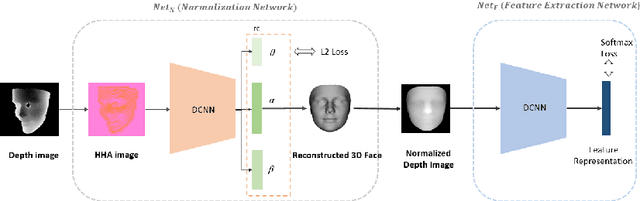


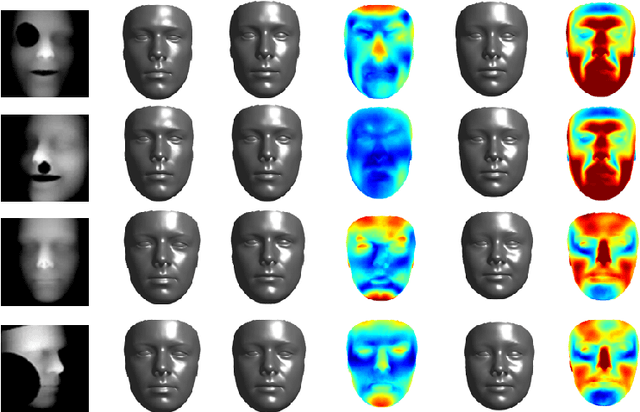
Depth information has been proven useful for face recognition. However, existing depth-image-based face recognition methods still suffer from noisy depth values and varying poses and expressions. In this paper, we propose a novel method for normalizing facial depth images to frontal pose and neutral expression and extracting robust features from the normalized depth images. The method is implemented via two deep convolutional neural networks (DCNN), normalization network ($Net_{N}$) and feature extraction network ($Net_{F}$). Given a facial depth image, $Net_{N}$ first converts it to an HHA image, from which the 3D face is reconstructed via a DCNN. $Net_{N}$ then generates a pose-and-expression normalized (PEN) depth image from the reconstructed 3D face. The PEN depth image is finally passed to $Net_{F}$, which extracts a robust feature representation via another DCNN for face recognition. Our preliminary evaluation results demonstrate the superiority of the proposed method in recognizing faces of arbitrary poses and expressions with depth images.