 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Prompt Tuning of Large Vision-Language Model for Fine-Grained Ship Classification
Mar 13, 2024Fine-grained ship classification in remote sensing (RS-FGSC) poses a significant challenge due to the high similarity between classes and the limited availability of labeled data, limiting the effectiveness of traditional supervised classification methods. Recent advancements in large pre-trained Vision-Language Models (VLMs) have demonstrated impressive capabilities in few-shot or zero-shot learning, particularly in understanding image content. This study delves into harnessing the potential of VLMs to enhance classification accuracy for unseen ship categories, which holds considerable significance in scenarios with restricted data due to cost or privacy constraints. Directly fine-tuning VLMs for RS-FGSC often encounters the challenge of overfitting the seen classes, resulting in suboptimal generalization to unseen classes, which highlights the difficulty in differentiating complex backgrounds and capturing distinct ship features. To address these issues, we introduce a novel prompt tuning technique that employs a hierarchical, multi-granularity prompt design. Our approach integrates remote sensing ship priors through bias terms, learned from a small trainable network. This strategy enhances the model's generalization capabilities while improving its ability to discern intricate backgrounds and learn discriminative ship features. Furthermore, we contribute to the field by introducing a comprehensive dataset, FGSCM-52, significantly expanding existing datasets with more extensive data and detailed annotations for less common ship classes. Extensive experimental evaluations demonstrate the superiority of our proposed method over current state-of-the-art techniques. The source code will be made publicly available.
Audio Description from Image by Modal Translation Network
Mar 18, 2021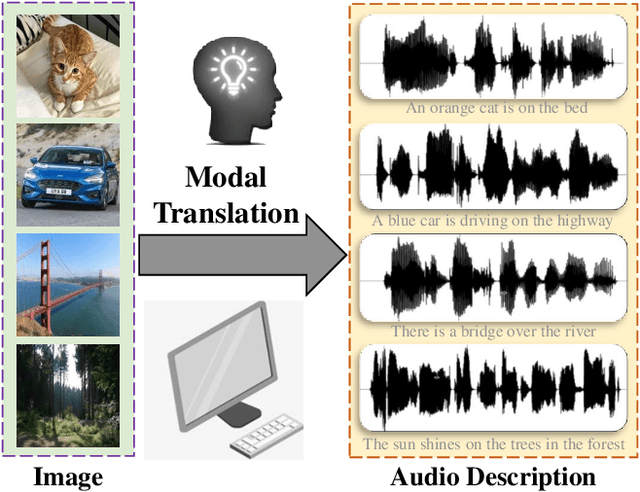
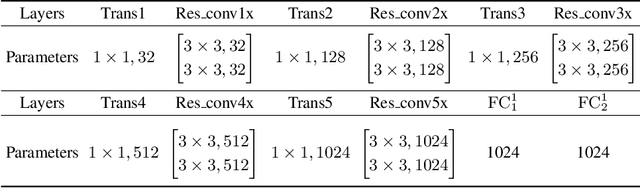
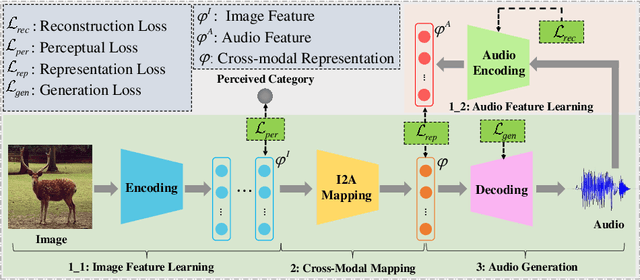

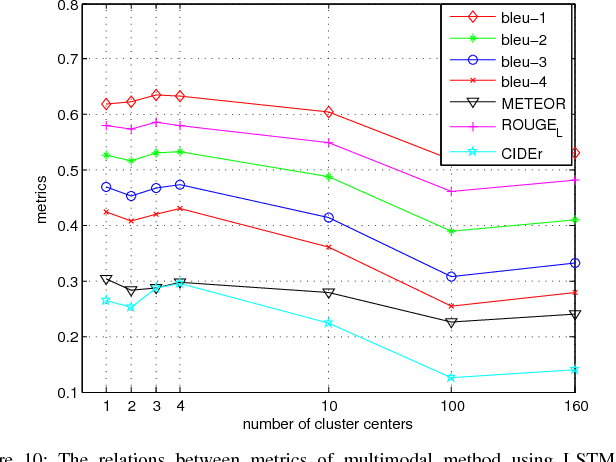
Audio is the main form for the visually impaired to obtain information. In reality, all kinds of visual data always exist, but audio data does not exist in many cases. In order to help the visually impaired people to better perceive the information around them, an image-to-audio-description (I2AD) task is proposed to generate audio descriptions from images in this paper. To complete this totally new task, a modal translation network (MT-Net) from visual to auditory sense is proposed. The proposed MT-Net includes three progressive sub-networks: 1) feature learning, 2) cross-modal mapping, and 3) audio generation. First, the feature learning sub-network aims to learn semantic features from image and audio, including image feature learning and audio feature learning. Second, the cross-modal mapping sub-network transforms the image feature into a cross-modal representation with the same semantic concept as the audio feature. In this way, the correlation of inter-modal data is effectively mined for easing the heterogeneous gap between image and audio. Finally, the audio generation sub-network is designed to generate the audio waveform from the cross-modal representation. The generated audio waveform is interpolated to obtain the corresponding audio file according to the sample frequency. Being the first attempt to explore the I2AD task, three large-scale datasets with plenty of manual audio descriptions are built. Experiments on the datasets verify the feasibility of generating intelligible audio from an image directly and the effectiveness of proposed method.
Exploring Models and Data for Remote Sensing Image Caption Generation
Dec 21, 2017

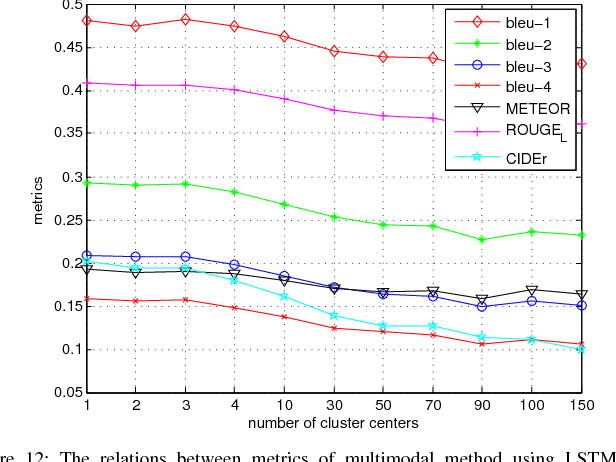
Inspired by recent development of artificial satellite, remote sensing images have attracted extensive attention. Recently, noticeable progress has been made in scene classification and target detection.However, it is still not clear how to describe the remote sensing image content with accurate and concise sentences. In this paper, we investigate to describe the remote sensing images with accurate and flexible sentences. First, some annotated instructions are presented to better describe the remote sensing images considering the special characteristics of remote sensing images. Second, in order to exhaustively exploit the contents of remote sensing images, a large-scale aerial image data set is constructed for remote sensing image caption. Finally, a comprehensive review is presented on the proposed data set to fully advance the task of remote sensing caption. Extensive experiments on the proposed data set demonstrate that the content of the remote sensing image can be completely described by generating language descriptions. The data set is available at https://github.com/201528014227051/RSICD_optimal