 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-TTS: LLM-based dual-streaming text-to-speech with CTC alignment
Feb 23, 2026Large-language-model (LLM)-based text-to-speech (TTS) systems can generate natural speech, but most are not designed for low-latency dual-streaming synthesis. High-quality dual-streaming TTS depends on accurate text--speech alignment and well-designed training sequences that balance synthesis quality and latency. Prior work often relies on GMM-HMM based forced-alignment toolkits (e.g., MFA), which are pipeline-heavy and less flexible than neural aligners; fixed-ratio interleaving of text and speech tokens struggles to capture text--speech alignment regularities. We propose CTC-TTS, which replaces MFA with a CTC based aligner and introduces a bi-word based interleaving strategy. Two variants are designed: CTC-TTS-L (token concatenation along the sequence length) for higher quality and CTC-TTS-F (embedding stacking along the feature dimension) for lower latency. Experiments show that CTC-TTS outperforms fixed-ratio interleaving and MFA-based baselines on streaming synthesis and zero-shot tasks. Speech samples are available at https://ctctts.github.io/.
UniHash: Unifying Pointwise and Pairwise Hashing Paradigms for Seen and Unseen Category Retrieval
Jan 14, 2026Effective retrieval across both seen and unseen categories is crucial for modern image retrieval systems. Retrieval on seen categories ensures precise recognition of known classes, while retrieval on unseen categories promotes generalization to novel classes with limited supervision. However, most existing deep hashing methods are confined to a single training paradigm, either pointwise or pairwise, where the former excels on seen categories and the latter generalizes better to unseen ones. To overcome this limitation, we propose Unified Hashing (UniHash), a dual-branch framework that unifies the strengths of both paradigms to achieve balanced retrieval performance across seen and unseen categories. UniHash consists of two complementary branches: a center-based branch following the pointwise paradigm and a pairwise branch following the pairwise paradigm. A novel hash code learning method is introduced to enable bidirectional knowledge transfer between branches, improving hash code discriminability and generalization. It employs a mutual learning loss to align hash representations and introduces a Split-Merge Mixture of Hash Experts (SM-MoH) module to enhance cross-branch exchange of hash representations. Theoretical analysis substantiates the effectiveness of UniHash, and extensive experiments on CIFAR-10, MSCOCO, and ImageNet demonstrate that UniHash consistently achieves state-of-the-art performance in both seen and unseen image retrieval scenarios.
How Particle-System Random Batch Methods Enhance Graph Transformer: Memory Efficiency and Parallel Computing Strategy
Nov 08, 2025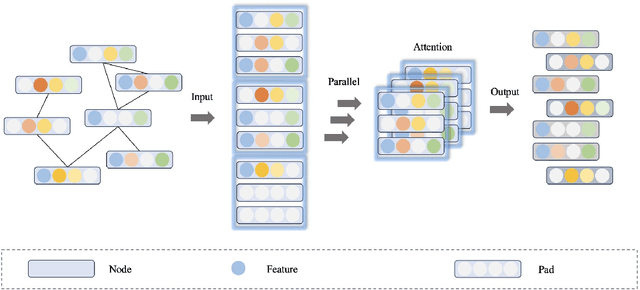


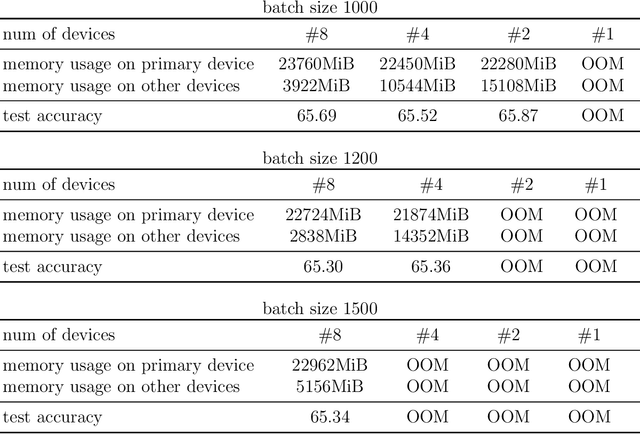
Attention mechanism is a significant part of Transformer models. It helps extract features from embedded vectors by adding global information and its expressivity has been proved to be powerful. Nevertheless, the quadratic complexity restricts its practicability. Although several researches have provided attention mechanism in sparse form, they are lack of theoretical analysis about the expressivity of their mechanism while reducing complexity. In this paper, we put forward Random Batch Attention (RBA), a linear self-attention mechanism, which has theoretical support of the ability to maintain its expressivity. Random Batch Attention has several significant strengths as follows: (1) Random Batch Attention has linear time complexity. Other than this, it can be implemented in parallel on a new dimension, which contributes to much memory saving. (2) Random Batch Attention mechanism can improve most of the existing models by replacing their attention mechanisms, even many previously improved attention mechanisms. (3) Random Batch Attention mechanism has theoretical explanation in convergence, as it comes from Random Batch Methods on computation mathematics. Experiments on large graphs have proved advantages mentioned above. Also, the theoretical modeling of self-attention mechanism is a new tool for future research on attention-mechanism analysis.
Training-Free ANN-to-SNN Conversion for High-Performance Spiking Transformer
Aug 11, 2025Leveraging the event-driven paradigm, Spiking Neural Networks (SNNs) offer a promising approach for constructing energy-efficient Transformer architectures. Compared to directly trained Spiking Transformers, ANN-to-SNN conversion methods bypass the high training costs. However, existing methods still suffer from notable limitations, failing to effectively handle nonlinear operations in Transformer architectures and requiring additional fine-tuning processes for pre-trained ANNs. To address these issues, we propose a high-performance and training-free ANN-to-SNN conversion framework tailored for Transformer architectures. Specifically, we introduce a Multi-basis Exponential Decay (MBE) neuron, which employs an exponential decay strategy and multi-basis encoding method to efficiently approximate various nonlinear operations. It removes the requirement for weight modifications in pre-trained ANNs. Extensive experiments across diverse tasks (CV, NLU, NLG) and mainstream Transformer architectures (ViT, RoBERTa, GPT-2) demonstrate that our method achieves near-lossless conversion accuracy with significantly lower latency. This provides a promising pathway for the efficient and scalable deployment of Spiking Transformers in real-world applications.
HyDRA: A Hybrid Dual-Mode Network for Closed- and Open-Set RFFI with Optimized VMD
Jul 16, 2025Device recognition is vital for security in wireless communication systems, particularly for applications like access control. Radio Frequency Fingerprint Identification (RFFI) offers a non-cryptographic solution by exploiting hardware-induced signal distortions. This paper proposes HyDRA, a Hybrid Dual-mode RF Architecture that integrates an optimized Variational Mode Decomposition (VMD) with a novel architecture based on the fusion of Convolutional Neural Networks (CNNs), Transformers, and Mamba components, designed to support both closed-set and open-set classification tasks. The optimized VMD enhances preprocessing efficiency and classification accuracy by fixing center frequencies and using closed-form solutions. HyDRA employs the Transformer Dynamic Sequence Encoder (TDSE) for global dependency modeling and the Mamba Linear Flow Encoder (MLFE) for linear-complexity processing, adapting to varying conditions. Evaluation on public datasets demonstrates state-of-the-art (SOTA) accuracy in closed-set scenarios and robust performance in our proposed open-set classification method, effectively identifying unauthorized devices. Deployed on NVIDIA Jetson Xavier NX, HyDRA achieves millisecond-level inference speed with low power consumption, providing a practical solution for real-time wireless authentication in real-world environments.
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
Jul 09, 2024
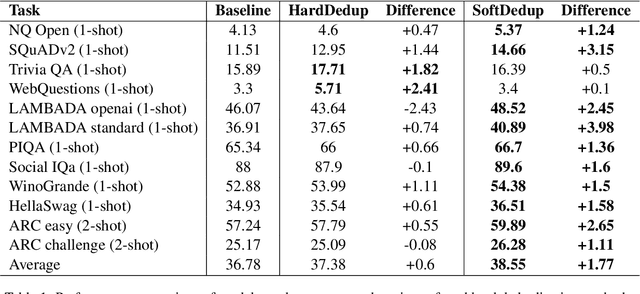
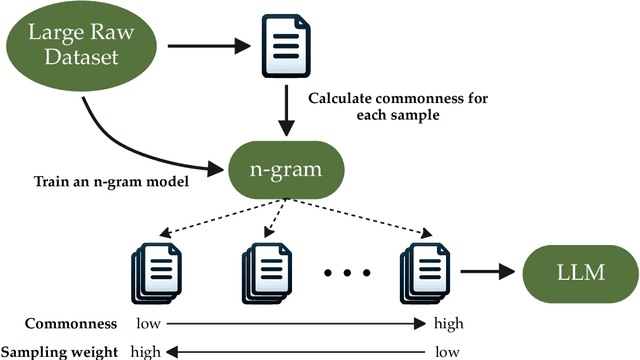
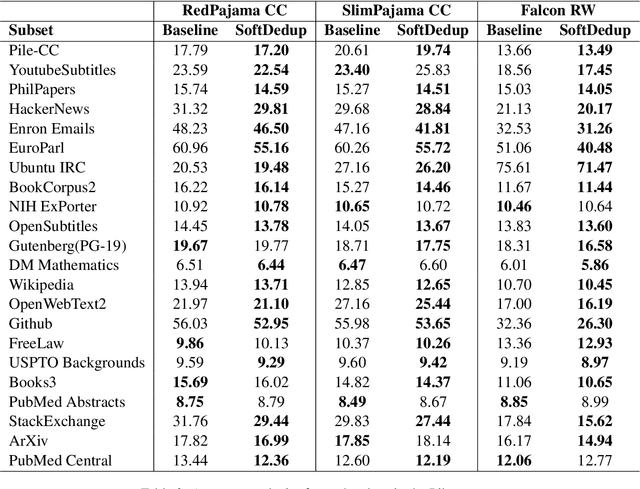
The effectiveness of large language models (LLMs) is often hindered by duplicated data in their extensive pre-training datasets. Current approaches primarily focus on detecting and removing duplicates, which risks the loss of valuable information and neglects the varying degrees of duplication. To address this, we propose a soft deduplication method that maintains dataset integrity while selectively reducing the sampling weight of data with high commonness. Central to our approach is the concept of "data commonness", a metric we introduce to quantify the degree of duplication by measuring the occurrence probabilities of samples using an n-gram model. Empirical analysis shows that this method significantly improves training efficiency, achieving comparable perplexity scores with at least a 26% reduction in required training steps. Additionally, it enhances average few-shot downstream accuracy by 1.77% when trained for an equivalent duration. Importantly, this approach consistently improves performance, even on rigorously deduplicated datasets, indicating its potential to complement existing methods and become a standard pre-training process for LLMs.
Mix-of-Granularity: Optimize the Chunking Granularity for Retrieval-Augmented Generation
Jun 01, 2024



Integrating information from different reference data sources is a major challenge for Retrieval-Augmented Generation (RAG) systems because each knowledge source adopts a unique data structure and follows different conventions. Retrieving from multiple knowledge sources with one fixed strategy usually leads to under-exploitation of information. To mitigate this drawback, inspired by Mix-of-Expert, we introduce Mix-of-Granularity (MoG), a method that dynamically determines the optimal granularity of a knowledge database based on input queries using a router. The router is efficiently trained with a newly proposed loss function employing soft labels. We further extend MoG to Mix-of-Granularity-Graph (MoGG), where reference documents are pre-processed into graphs, enabling the retrieval of relevant information from distantly situated chunks. Extensive experiments demonstrate that both MoG and MoGG effectively predict optimal granularity levels, significantly enhancing the performance of the RAG system in downstream tasks. The code of both MoG and MoGG will be made public.
EEG2TEXT: Open Vocabulary EEG-to-Text Decoding with EEG Pre-Training and Multi-View Transformer
May 03, 2024



Deciphering the intricacies of the human brain has captivated curiosity for centuries. Recent strides in Brain-Computer Interface (BCI) technology, particularly using motor imagery, have restored motor functions such as reaching, grasping, and walking in paralyzed individuals. However, unraveling natural language from brain signals remains a formidable challenge. Electroencephalography (EEG) is a non-invasive technique used to record electrical activity in the brain by placing electrodes on the scalp. Previous studies of EEG-to-text decoding have achieved high accuracy on small closed vocabularies, but still fall short of high accuracy when dealing with large open vocabularies. We propose a novel method, EEG2TEXT, to improve the accuracy of open vocabulary EEG-to-text decoding. Specifically, EEG2TEXT leverages EEG pre-training to enhance the learning of semantics from EEG signals and proposes a multi-view transformer to model the EEG signal processing by different spatial regions of the brain. Experiments show that EEG2TEXT has superior performance, outperforming the state-of-the-art baseline methods by a large margin of up to 5% in absolute BLEU and ROUGE scores. EEG2TEXT shows great potential for a high-performance open-vocabulary brain-to-text system to facilitate communication.
AI for Biomedicine in the Era of Large Language Models
Mar 23, 2024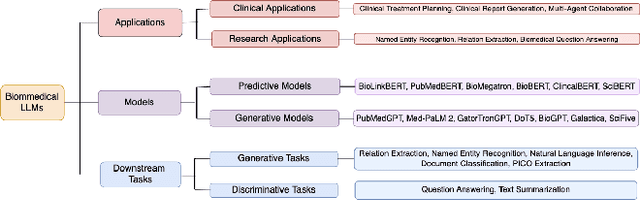
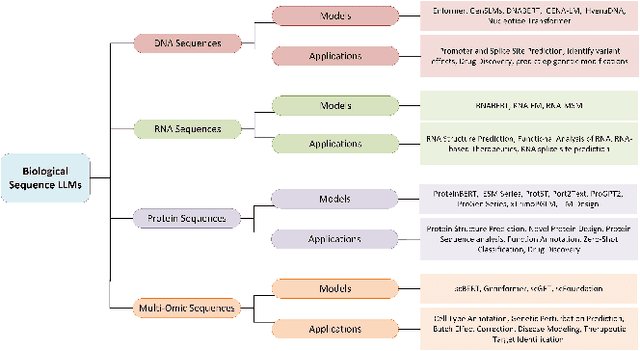
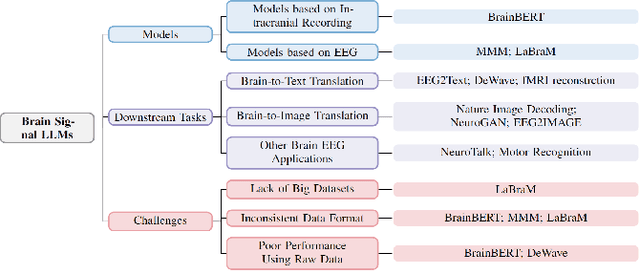
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
XAI-CLASS: Explanation-Enhanced Text Classification with Extremely Weak Supervision
Oct 31, 2023Text classification aims to effectively categorize documents into pre-defined categories. Traditional methods for text classification often rely on large amounts of manually annotated training data, making the process time-consuming and labor-intensive. To address this issue, recent studies have focused on weakly-supervised and extremely weakly-supervised settings, which require minimal or no human annotation, respectively. In previous methods of weakly supervised text classification, pseudo-training data is generated by assigning pseudo-labels to documents based on their alignment (e.g., keyword matching) with specific classes. However, these methods ignore the importance of incorporating the explanations of the generated pseudo-labels, or saliency of individual words, as additional guidance during the text classification training process. To address this limitation, we propose XAI-CLASS, a novel explanation-enhanced extremely weakly-supervised text classification method that incorporates word saliency prediction as an auxiliary task. XAI-CLASS begins by employing a multi-round question-answering process to generate pseudo-training data that promotes the mutual enhancement of class labels and corresponding explanation word generation. This pseudo-training data is then used to train a multi-task framework that simultaneously learns both text classification and word saliency prediction. Extensive experiments on several weakly-supervised text classification datasets show that XAI-CLASS outperforms other weakly-supervised text classification methods significantly. Moreover, experiments demonstrate that XAI-CLASS enhances both model performance and explainability.