 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Machine Learning-based Failure Management in Optical Networks
Aug 23, 2022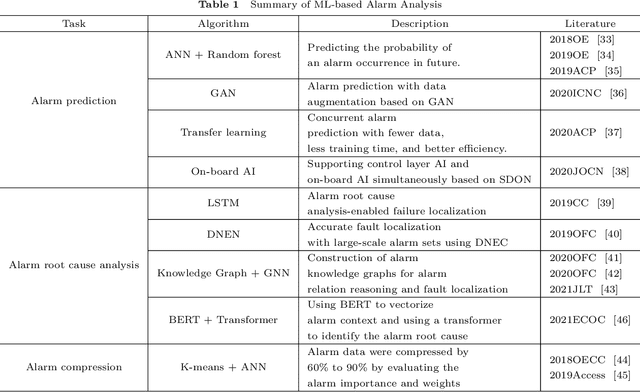
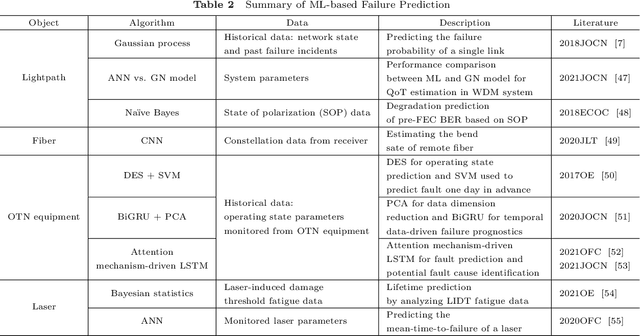
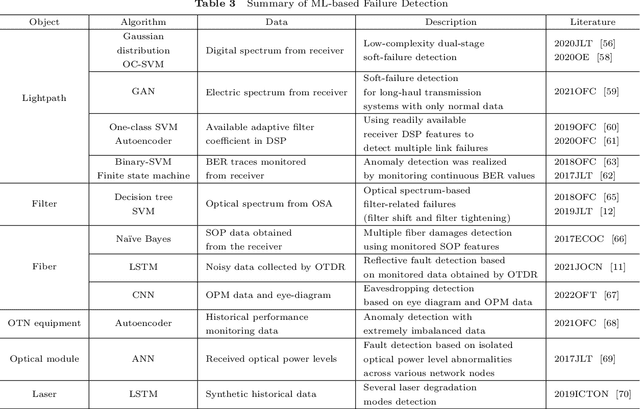
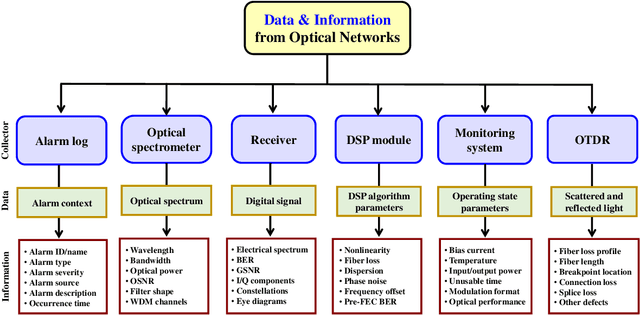
Failure management plays a significant role in optical networks. It ensures secure operation, mitigates potential risks, and executes proactive protection. Machine learning (ML) is considered to be an extremely powerful technique for performing comprehensive data analysis and complex network management and is widely utilized for failure management in optical networks to revolutionize the conventional manual methods. In this study, the background of failure management is introduced, where typical failure tasks, physical objects, ML algorithms, data source, and extracted information are illustrated in detail. An overview of the applications of ML in failure management is provided in terms of alarm analysis, failure prediction, failure detection, failure localization, and failure identification. Finally, the future directions on ML for failure management are discussed from the perspective of data, model, task, and emerging techniques.
Bridging the Distribution Gap of Visible-Infrared Person Re-identification with Modality Batch Normalization
Mar 08, 2021
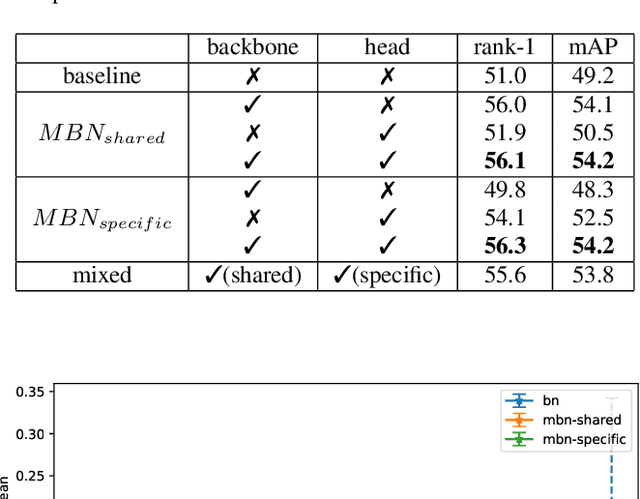
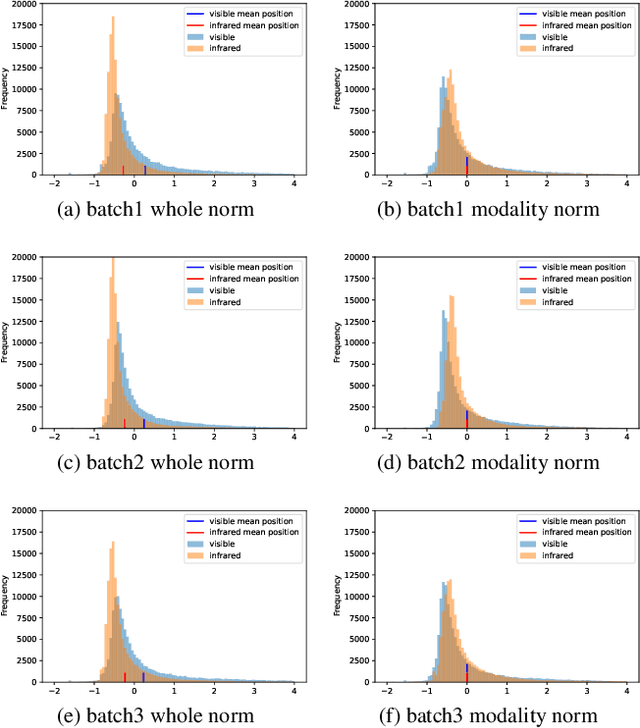
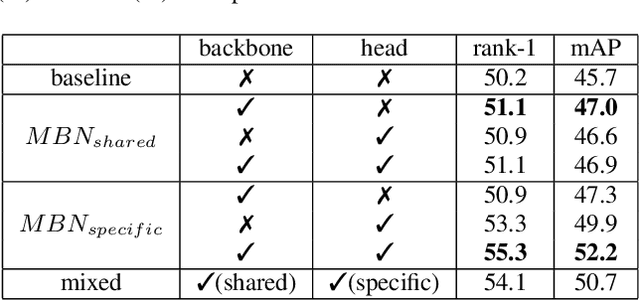
Visible-infrared cross-modality person re-identification (VI-ReID), whose aim is to match person images between visible and infrared modality, is a challenging cross-modality image retrieval task. Most existing works integrate batch normalization layers into their neural network, but we found out that batch normalization layers would lead to two types of distribution gap: 1) inter-mini-batch distribution gap -- the distribution gap of the same modality between each mini-batch; 2) intra-mini-batch modality distribution gap -- the distribution gap of different modality within the same mini-batch. To address these problems, we propose a new batch normalization layer called Modality Batch Normalization (MBN), which normalizes each modality sub-mini-batch respectively instead of the whole mini-batch, and can reduce these distribution gap significantly. Extensive experiments show that our MBN is able to boost the performance of VI-ReID models, even with different datasets, backbones and losses.
Unified Batch All Triplet Loss for Visible-Infrared Person Re-identification
Mar 08, 2021

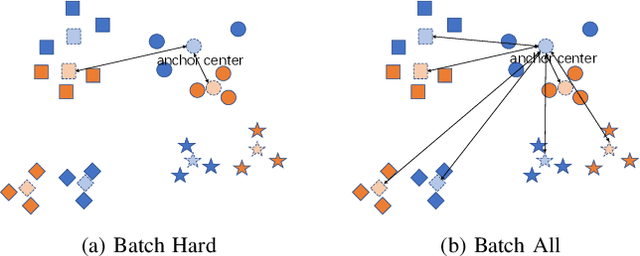
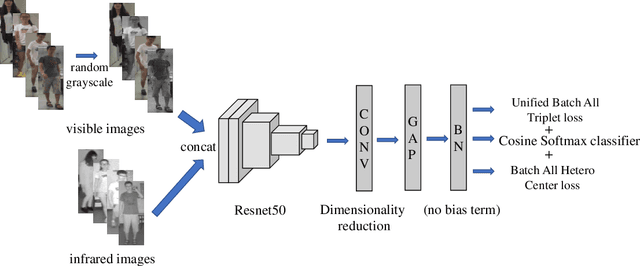
Visible-Infrared cross-modality person re-identification (VI-ReID), whose aim is to match person images between visible and infrared modality, is a challenging cross-modality image retrieval task. Batch Hard Triplet loss is widely used in person re-identification tasks, but it does not perform well in the Visible-Infrared person re-identification task. Because it only optimizes the hardest triplet for each anchor image within the mini-batch, samples in the hardest triplet may all belong to the same modality, which will lead to the imbalance problem of modality optimization. To address this problem, we adopt the batch all triplet selection strategy, which selects all the possible triplets among samples to optimize instead of the hardest triplet. Furthermore, we introduce Unified Batch All Triplet loss and Cosine Softmax loss to collaboratively optimize the cosine distance between image vectors. Similarly, we rewrite the Hetero Center Triplet loss, which is proposed for VI-ReID task, into a batch all form to improve model performance. Extensive experiments indicate the effectiveness of the proposed methods, which outperform state-of-the-art methods by a wide margin.
Multi-Grid Back-Projection Networks
Jan 01, 2021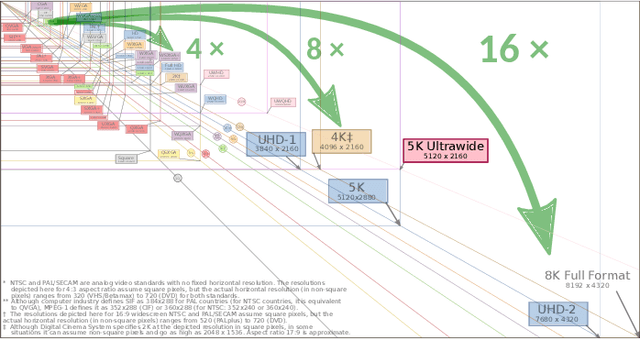

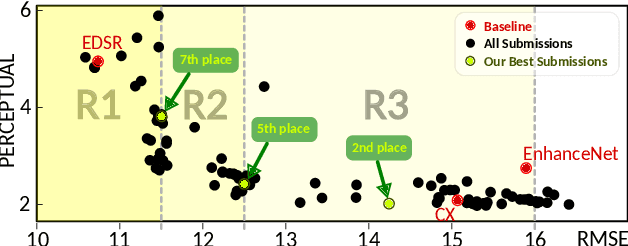

Multi-Grid Back-Projection (MGBP) is a fully-convolutional network architecture that can learn to restore images and videos with upscaling artifacts. Using the same strategy of multi-grid partial differential equation (PDE) solvers this multiscale architecture scales computational complexity efficiently with increasing output resolutions. The basic processing block is inspired in the iterative back-projection (IBP) algorithm and constitutes a type of cross-scale residual block with feedback from low resolution references. The architecture performs in par with state-of-the-arts alternatives for regression targets that aim to recover an exact copy of a high resolution image or video from which only a downscale image is known. A perceptual quality target aims to create more realistic outputs by introducing artificial changes that can be different from a high resolution original content as long as they are consistent with the low resolution input. For this target we propose a strategy using noise inputs in different resolution scales to control the amount of artificial details generated in the output. The noise input controls the amount of innovation that the network uses to create artificial realistic details. The effectiveness of this strategy is shown in benchmarks and it is explained as a particular strategy to traverse the perception-distortion plane.
MGBPv2: Scaling Up Multi-Grid Back-Projection Networks
Sep 27, 2019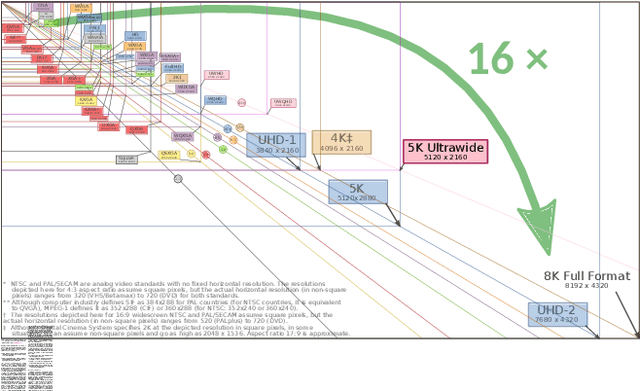
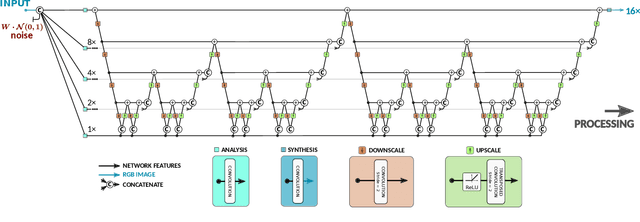
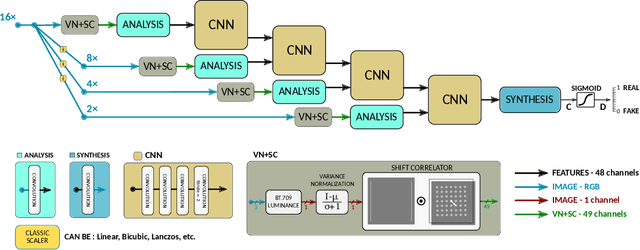

Here, we describe our solution for the AIM-2019 Extreme Super-Resolution Challenge, where we won the 1st place in terms of perceptual quality (MOS) similar to the ground truth and achieved the 5th place in terms of high-fidelity (PSNR). To tackle this challenge, we introduce the second generation of MultiGrid BackProjection networks (MGBPv2) whose major modifications make the system scalable and more general than its predecessor. It combines the scalability of the multigrid algorithm and the performance of iterative backprojections. In its original form, MGBP is limited to a small number of parameters due to a strongly recursive structure. In MGBPv2, we make full use of the multigrid recursion from the beginning of the network; we allow different parameters in every module of the network; we simplify the main modules; and finally, we allow adjustments of the number of network features based on the scale of operation. For inference tasks, we introduce an overlapping patch approach to further allow processing of very large images (e.g. 8K). Our training strategies make use of a multiscale loss, combining distortion and/or perception losses on the output as well as downscaled output images. The final system can balance between high quality and high performance.