 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models in Resource-Constrained Environments
Paper and Code
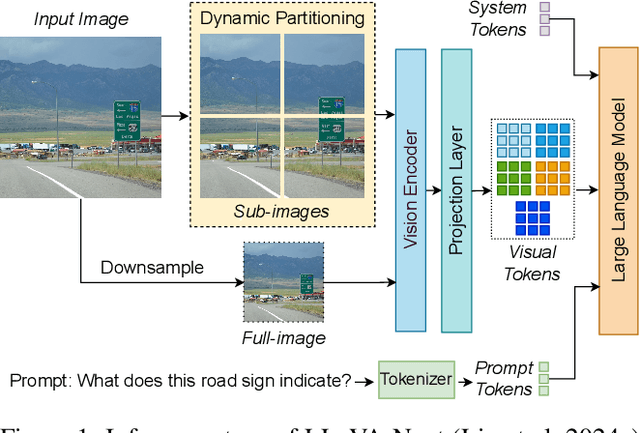

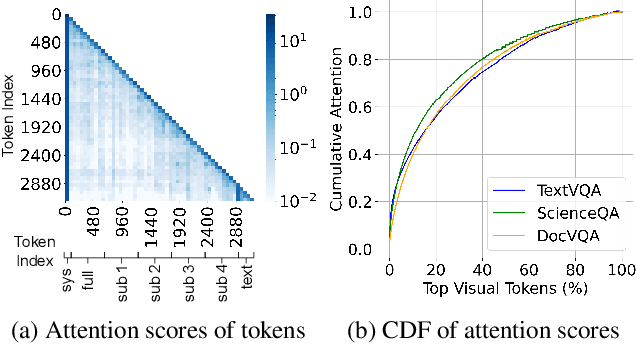

High-resolution Vision-Language Models (VLMs) have been widely used in multimodal tasks to enhance accuracy by preserving detailed image information. However, these models often generate excessive visual tokens due to encoding multiple partitions of the input image. Processing these excessive visual tokens is computationally challenging, especially in resource-constrained environments with commodity GPUs. To support high-resolution images while meeting resource constraints, we propose High-Resolution Early Dropping (HiRED), a token-dropping scheme that operates within a fixed token budget before the Large Language Model (LLM) stage. HiRED can be integrated with existing high-resolution VLMs in a plug-and-play manner, as it requires no additional training while still maintaining superior accuracy. We strategically use the vision encoder's attention in the initial layers to assess the visual content of each image partition and allocate the token budget accordingly. Then, using the attention in the final layer, we select the most important visual tokens from each partition within the allocated budget, dropping the rest. Empirically, when applied to LLaVA-Next-7B on NVIDIA TESLA P40 GPU, HiRED with a 20% token budget increases token generation throughput by 4.7, reduces first-token generation latency by 15 seconds, and saves 2.3 GB of GPU memory for a single inference.