 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding temporally weakly supervised training: A case study for keyword spotting
Paper and Code
May 30, 2023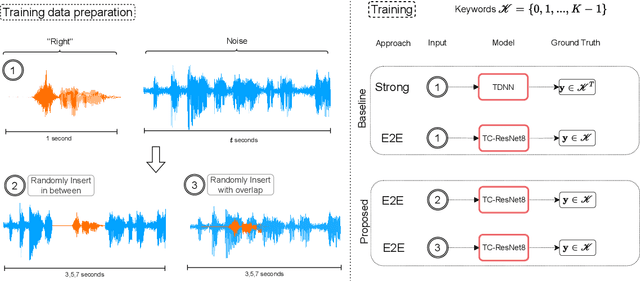



The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.