 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Contextual Reasoning from Broad Descriptions for ASR with Speech-LLM via Metadata-Driven Reasoning Chains
Jun 09, 2026Speech recognition often fails on rare, domain-specific terms and context-related named entities. Existing contextualization techniques typically bias decoding with keywords or phrase lists, which does not scale well or exploit deeper knowledge. We propose a training method that teaches a speech-LLM to use broad descriptions (e.g. from videos) as weak semantic priors to perform contextual reasoning grounded in the audio. We build 400 hours of reasoning-augmented speech data by pairing erroneous hypotheses with video metadata and LLM-generated reasoning explanations that justify context-driven corrections. We finetune the speech-LLM to perform chain-of-thought reasoning: generate an initial transcript, then reason over the context, and finally return a corrected transcript. On held-out YouTube-derived test sets, our approach reduces errors, with specific improvements on rare words and named entities, and lays groundwork for deeper contextual reasoning in speech recognition.
Speech Encoder Fusion for LLM-based Automatic Speech Recognition
Jun 09, 2026Speech-aware large language models (LLMs) can incorporate speech through pre-trained acoustic encoders that project speech features into the LLM embedding space. While the choice of the speech encoder critically influences performance, different encoders often exhibit complementary strengths, motivating their combination. In this work, we investigate whether fusing multiple pre-trained speech encoders can enhance speech-aware LLMs for automatic speech recognition (ASR). We explore several fusion strategies beyond simple feature concatenation, including learned combinations and Transformer-based fusion architectures, and evaluate them across mono- and multilingual ASR settings as well as diarized speech recognition. Our results indicate that carefully fusing multiple parallel speech encoders improves downstream performance in all scenarios with limited computational overhead.
Phoneme-First Prediction for LLM-Based Speech Recognition
Jun 09, 2026Recent research has explored integrating Large Language Models (LLMs) with speech encoders to create speech-augmented LLMs capable of contextualized speech recognition. The main challenge lies in aligning the semantic embeddings of LLMs with the acoustic representations of speech encoders. We propose a novel approach that teaches the LLM to first predict phonemes from the speech features before generating the final transcript. By integrating a phoneme prediction step directly into the LLM, the model develops a fine-grained knowledge of pronunciation, reducing acoustic confusion and improving transcription accuracy and explainability. Our method is cheap and simple, as phoneme targets can be automatically derived from existing transcripts. Through comprehensive experiments, we show that intermediate phoneme prediction can improve speech recognition, particularly in low-resource settings, and yields outputs that are acoustically more faithful to the speech.
Leveraging Broadcast Media Subtitle Transcripts for Automatic Speech Recognition and Subtitling
Feb 05, 2025



The recent advancement of speech recognition technology has been driven by large-scale datasets and attention-based architectures, but many challenges still remain, especially for low-resource languages and dialects. This paper explores the integration of weakly supervised transcripts from TV subtitles into automatic speech recognition (ASR) systems, aiming to improve both verbatim transcriptions and automatically generated subtitles. To this end, verbatim data and subtitles are regarded as different domains or languages, due to their distinct characteristics. We propose and compare several end-to-end architectures that are designed to jointly model both modalities with separate or shared encoders and decoders. The proposed methods are able to jointly generate a verbatim transcription and a subtitle. Evaluation on Flemish (Belgian Dutch) demonstrates that a model with cascaded encoders and separate decoders allows to represent the differences between the two data types most efficiently while improving on both domains. Despite differences in domain and linguistic variations, combining verbatim transcripts with subtitle data leads to notable ASR improvements without the need for extensive preprocessing. Additionally, experiments with a large-scale subtitle dataset show the scalability of the proposed approach. The methods not only improve ASR accuracy but also generate subtitles that closely match standard written text, offering several potential applications.
Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models
Sep 04, 2024



Continuous speech can be converted into a discrete sequence by deriving discrete units from the hidden features of self-supervised learned (SSL) speech models. Although SSL models are becoming larger and trained on more data, they are often sensitive to real-life distortions like additive noise or reverberation, which translates to a shift in discrete units. We propose a parameter-efficient approach to generate noise-robust discrete units from pre-trained SSL models by training a small encoder-decoder model, with or without adapters, to simultaneously denoise and discretise the hidden features of the SSL model. The model learns to generate a clean discrete sequence for a noisy utterance, conditioned on the SSL features. The proposed denoiser outperforms several pre-training methods on the tasks of noisy discretisation and noisy speech recognition, and can be finetuned to the target environment with a few recordings of unlabeled target data.
Unsupervised Accent Adaptation Through Masked Language Model Correction Of Discrete Self-Supervised Speech Units
Sep 25, 2023



Self-supervised pre-trained speech models have strongly improved speech recognition, yet they are still sensitive to domain shifts and accented or atypical speech. Many of these models rely on quantisation or clustering to learn discrete acoustic units. We propose to correct the discovered discrete units for accented speech back to a standard pronunciation in an unsupervised manner. A masked language model is trained on discrete units from a standard accent and iteratively corrects an accented token sequence by masking unexpected cluster sequences and predicting their common variant. Small accent adapter blocks are inserted in the pre-trained model and fine-tuned by predicting the corrected clusters, which leads to an increased robustness of the pre-trained model towards a target accent, and this without supervision. We are able to improve a state-of-the-art HuBERT Large model on a downstream accented speech recognition task by altering the training regime with the proposed method.
Learning to Jointly Transcribe and Subtitle for End-to-End Spontaneous Speech Recognition
Oct 14, 2022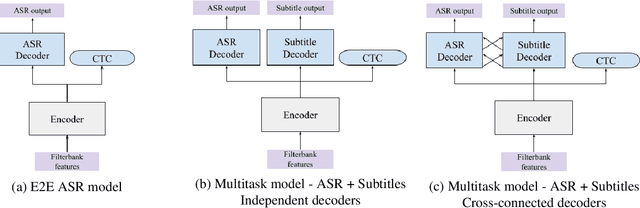
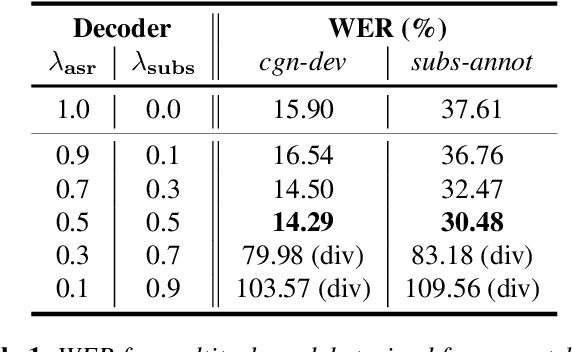

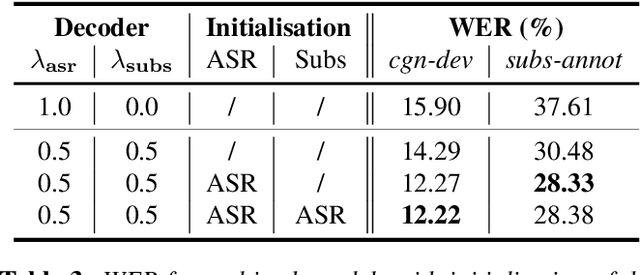
TV subtitles are a rich source of transcriptions of many types of speech, ranging from read speech in news reports to conversational and spontaneous speech in talk shows and soaps. However, subtitles are not verbatim (i.e. exact) transcriptions of speech, so they cannot be used directly to improve an Automatic Speech Recognition (ASR) model. We propose a multitask dual-decoder Transformer model that jointly performs ASR and automatic subtitling. The ASR decoder (possibly pre-trained) predicts the verbatim output and the subtitle decoder generates a subtitle, while sharing the encoder. The two decoders can be independent or connected. The model is trained to perform both tasks jointly, and is able to effectively use subtitle data. We show improvements on regular ASR and on spontaneous and conversational ASR by incorporating the additional subtitle decoder. The method does not require preprocessing (aligning, filtering, pseudo-labeling, ...) of the subtitles.
Comparison of Self-Supervised Speech Pre-Training Methods on Flemish Dutch
Sep 29, 2021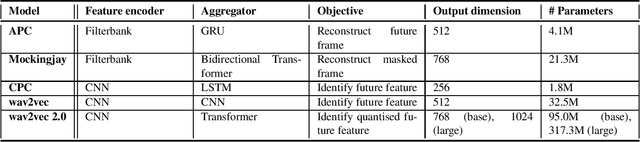
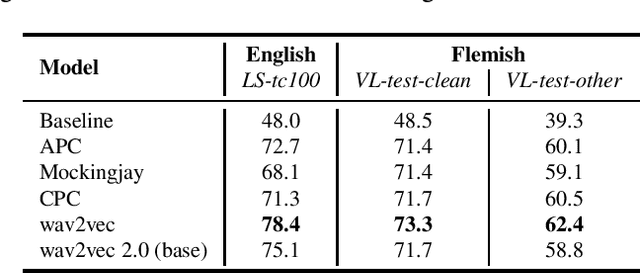
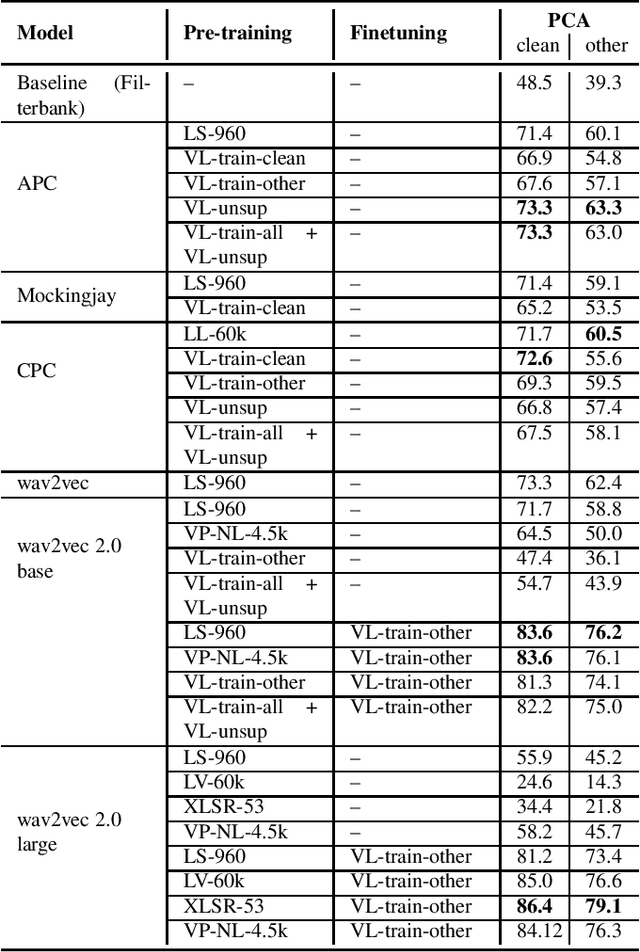
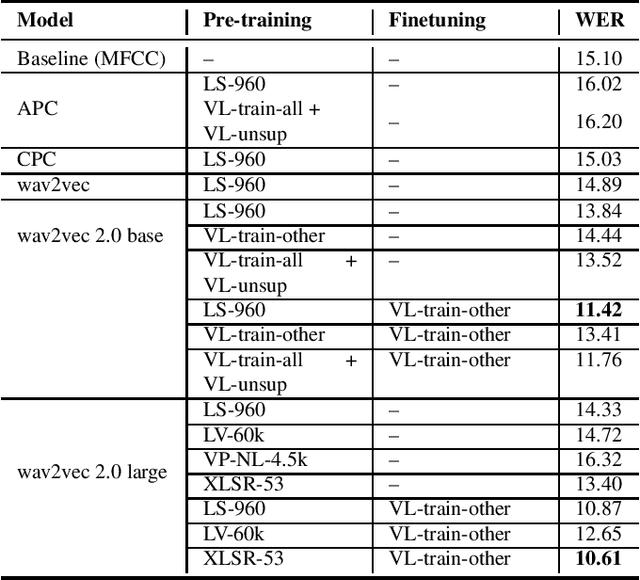
Recent research in speech processing exhibits a growing interest in unsupervised and self-supervised representation learning from unlabelled data to alleviate the need for large amounts of annotated data. We investigate several popular pre-training methods and apply them to Flemish Dutch. We compare off-the-shelf English pre-trained models to models trained on an increasing amount of Flemish data. We find that the most important factors for positive transfer to downstream speech recognition tasks include a substantial amount of data and a matching pre-training domain. Ideally, we also finetune on an annotated subset in the target language. All pre-trained models improve linear phone separability in Flemish, but not all methods improve Automatic Speech Recognition. We experience superior performance with wav2vec 2.0 and we obtain a 30% WER improvement by finetuning the multilingually pre-trained XLSR-53 model on Flemish Dutch, after integration into an HMM-DNN acoustic model.