 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalParse: Towards Unified and Scalable Singing Voice Transcription with Large Audio Language Models
May 06, 2026High-quality singing annotations are fundamental to modern Singing Voice Synthesis (SVS) systems. However, obtaining these annotations at scale through manual labeling is unrealistic due to the substantial labor and musical expertise required, making automatic annotation highly necessary. Despite their utility, current automatic transcription systems face significant challenges: they often rely on complex multi-stage pipelines, struggle to recover text-note alignments, and exhibit poor generalization to out-of-distribution (OOD) singing data. To alleviate these issues, we present VocalParse, a unified singing voice transcription (SVT) model built upon a Large Audio Language Model (LALM). Specifically, our novel contribution is to introduce an interleaved prompting formulation that jointly models lyrics, melody, and word-note correspondence, yielding a generated sequence that directly maps to a structured musical score. Furthermore, we propose a Chain-of-Thought (CoT) style prompting strategy, which decodes lyrics first as a semantic scaffold, significantly mitigating the context disruption problem while preserving the structural benefits of interleaved generation. Experiments demonstrate that VocalParse achieves state-of-the-art SVT performance on multiple singing datasets. The source code and checkpoint are available at https://github.com/pymaster17/VocalParse.
Spiking Vocos: An Energy-Efficient Neural Vocoder
Sep 16, 2025Despite the remarkable progress in the synthesis speed and fidelity of neural vocoders, their high energy consumption remains a critical barrier to practical deployment on computationally restricted edge devices. Spiking Neural Networks (SNNs), widely recognized for their high energy efficiency due to their event-driven nature, offer a promising solution for low-resource scenarios. In this paper, we propose Spiking Vocos, a novel spiking neural vocoder with ultra-low energy consumption, built upon the efficient Vocos framework. To mitigate the inherent information bottleneck in SNNs, we design a Spiking ConvNeXt module to reduce Multiply-Accumulate (MAC) operations and incorporate an amplitude shortcut path to preserve crucial signal dynamics. Furthermore, to bridge the performance gap with its Artificial Neural Network (ANN) counterpart, we introduce a self-architectural distillation strategy to effectively transfer knowledge. A lightweight Temporal Shift Module is also integrated to enhance the model's ability to fuse information across the temporal dimension with negligible computational overhead. Experiments demonstrate that our model achieves performance comparable to its ANN counterpart, with UTMOS and PESQ scores of 3.74 and 3.45 respectively, while consuming only 14.7% of the energy. The source code is available at https://github.com/pymaster17/Spiking-Vocos.
SepALM: Audio Language Models Are Error Correctors for Robust Speech Separation
May 06, 2025While contemporary speech separation technologies adeptly process lengthy mixed audio waveforms, they are frequently challenged by the intricacies of real-world environments, including noisy and reverberant settings, which can result in artifacts or distortions in the separated speech. To overcome these limitations, we introduce SepALM, a pioneering approach that employs audio language models (ALMs) to rectify and re-synthesize speech within the text domain following preliminary separation. SepALM comprises four core components: a separator, a corrector, a synthesizer, and an aligner. By integrating an ALM-based end-to-end error correction mechanism, we mitigate the risk of error accumulation and circumvent the optimization hurdles typically encountered in conventional methods that amalgamate automatic speech recognition (ASR) with large language models (LLMs). Additionally, we have developed Chain-of-Thought (CoT) prompting and knowledge distillation techniques to facilitate the reasoning and training processes of the ALM. Our experiments substantiate that SepALM not only elevates the precision of speech separation but also markedly bolsters adaptability in novel acoustic environments.
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Apr 19, 2024
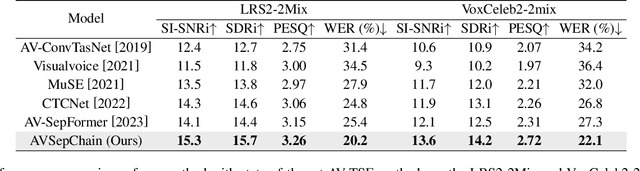

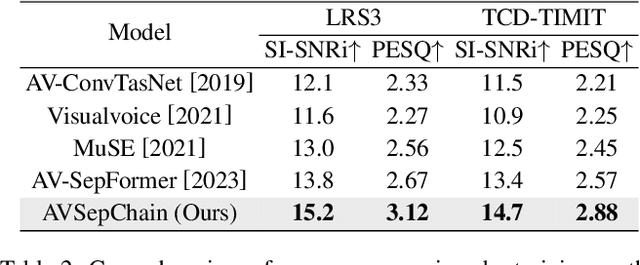
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Dec 16, 2023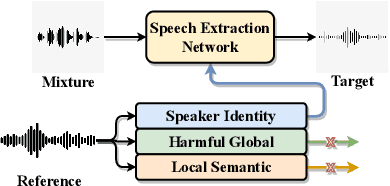
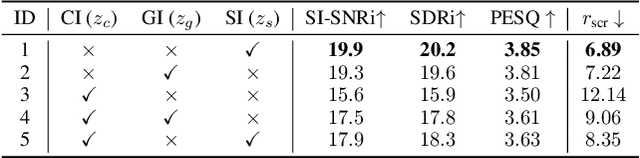
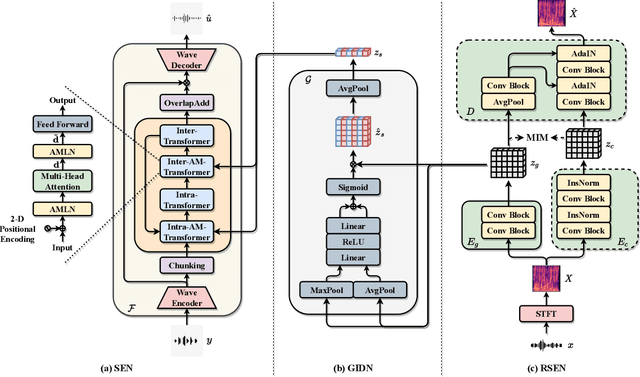
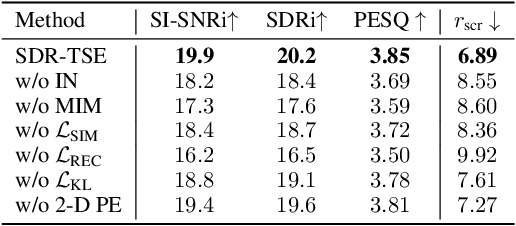
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023



In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
Multi-Dimensional and Multi-Scale Modeling for Speech Separation Optimized by Discriminative Learning
Mar 07, 2023


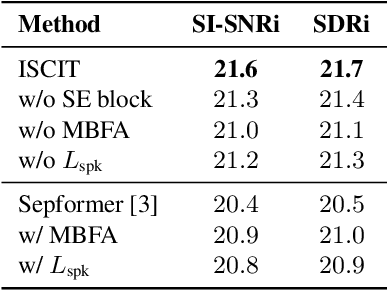
Transformer has shown advanced performance in speech separation, benefiting from its ability to capture global features. However, capturing local features and channel information of audio sequences in speech separation is equally important. In this paper, we present a novel approach named Intra-SE-Conformer and Inter-Transformer (ISCIT) for speech separation. Specifically, we design a new network SE-Conformer that can model audio sequences in multiple dimensions and scales, and apply it to the dual-path speech separation framework. Furthermore, we propose Multi-Block Feature Aggregation to improve the separation effect by selectively utilizing information from the intermediate blocks of the separation network. Meanwhile, we propose a speaker similarity discriminative loss to optimize the speech separation model to address the problem of poor performance when speakers have similar voices. Experimental results on the benchmark datasets WSJ0-2mix and WHAM! show that ISCIT can achieve state-of-the-art results.
Review of end-to-end speech synthesis technology based on deep learning
Apr 20, 2021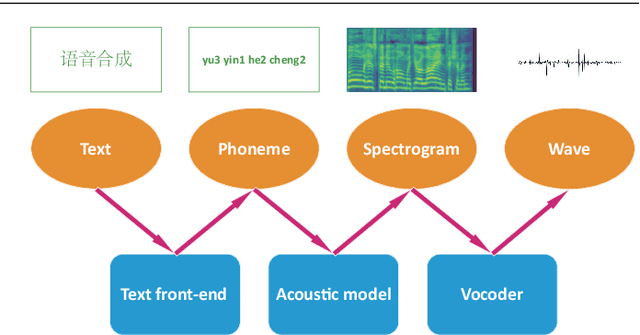
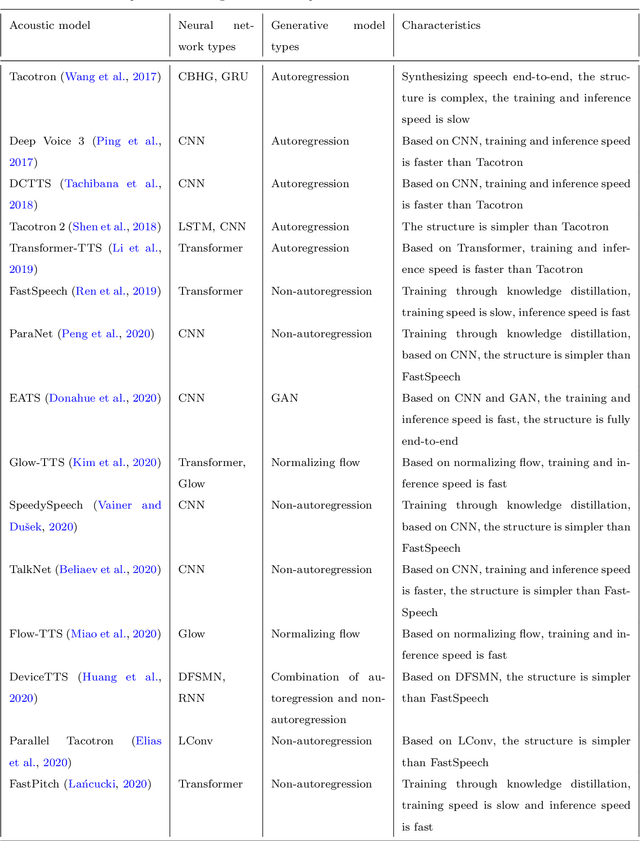
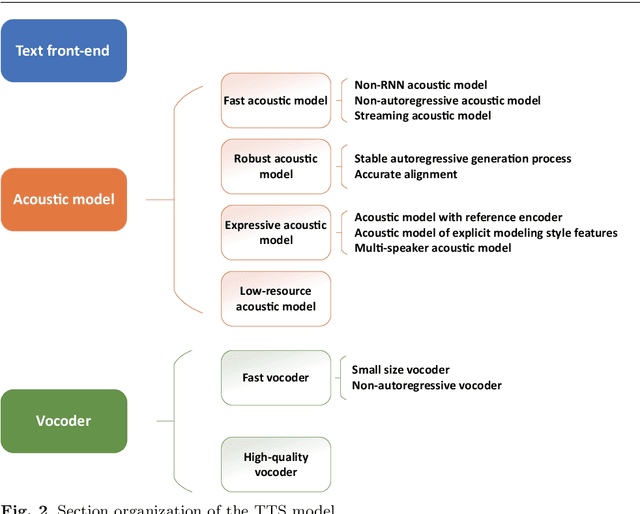

As an indispensable part of modern human-computer interaction system, speech synthesis technology helps users get the output of intelligent machine more easily and intuitively, thus has attracted more and more attention. Due to the limitations of high complexity and low efficiency of traditional speech synthesis technology, the current research focus is the deep learning-based end-to-end speech synthesis technology, which has more powerful modeling ability and a simpler pipeline. It mainly consists of three modules: text front-end, acoustic model, and vocoder. This paper reviews the research status of these three parts, and classifies and compares various methods according to their emphasis. Moreover, this paper also summarizes the open-source speech corpus of English, Chinese and other languages that can be used for speech synthesis tasks, and introduces some commonly used subjective and objective speech quality evaluation method. Finally, some attractive future research directions are pointed out.