 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Paper and Code
Apr 19, 2024
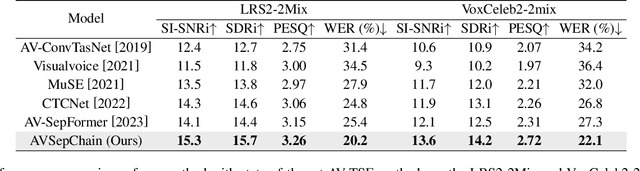

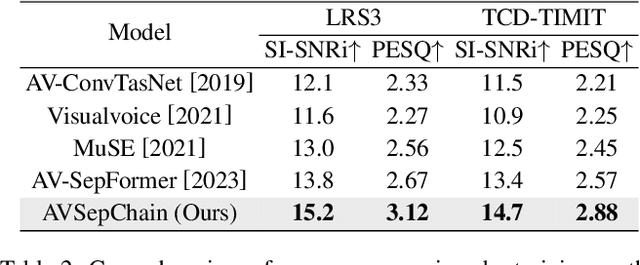
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.