 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of end-to-end speech synthesis technology based on deep learning
Apr 20, 2021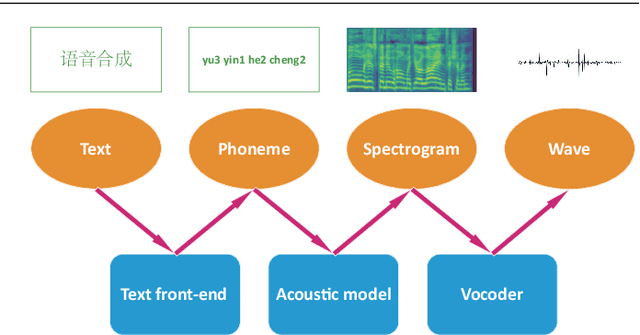
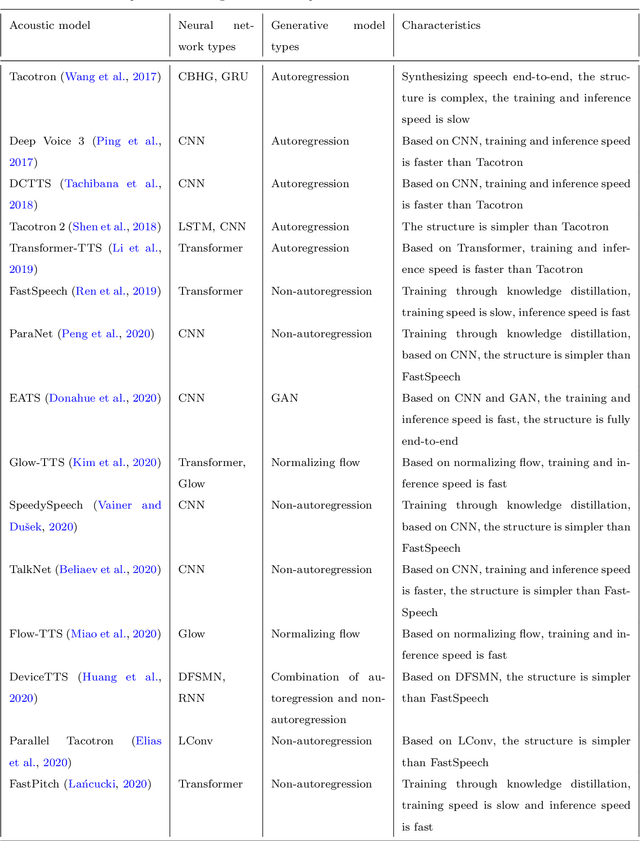
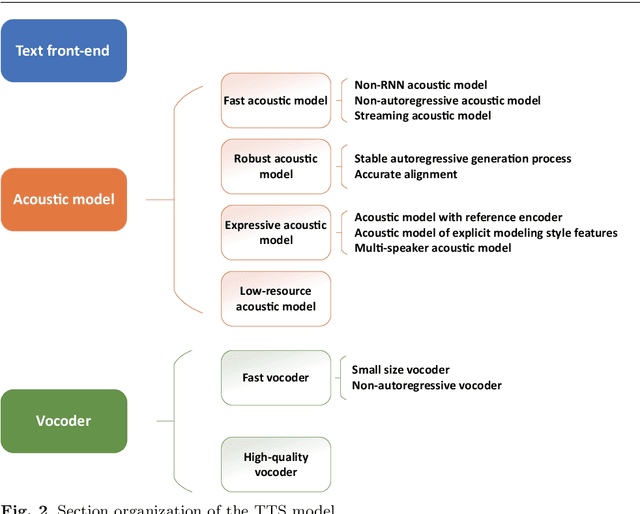

As an indispensable part of modern human-computer interaction system, speech synthesis technology helps users get the output of intelligent machine more easily and intuitively, thus has attracted more and more attention. Due to the limitations of high complexity and low efficiency of traditional speech synthesis technology, the current research focus is the deep learning-based end-to-end speech synthesis technology, which has more powerful modeling ability and a simpler pipeline. It mainly consists of three modules: text front-end, acoustic model, and vocoder. This paper reviews the research status of these three parts, and classifies and compares various methods according to their emphasis. Moreover, this paper also summarizes the open-source speech corpus of English, Chinese and other languages that can be used for speech synthesis tasks, and introduces some commonly used subjective and objective speech quality evaluation method. Finally, some attractive future research directions are pointed out.