 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional and Multi-Scale Modeling for Speech Separation Optimized by Discriminative Learning
Paper and Code
Mar 07, 2023


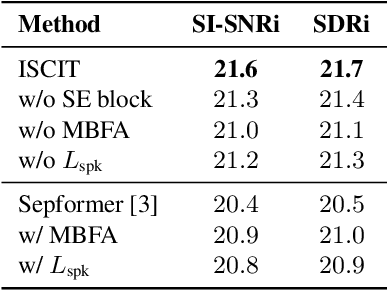
Transformer has shown advanced performance in speech separation, benefiting from its ability to capture global features. However, capturing local features and channel information of audio sequences in speech separation is equally important. In this paper, we present a novel approach named Intra-SE-Conformer and Inter-Transformer (ISCIT) for speech separation. Specifically, we design a new network SE-Conformer that can model audio sequences in multiple dimensions and scales, and apply it to the dual-path speech separation framework. Furthermore, we propose Multi-Block Feature Aggregation to improve the separation effect by selectively utilizing information from the intermediate blocks of the separation network. Meanwhile, we propose a speaker similarity discriminative loss to optimize the speech separation model to address the problem of poor performance when speakers have similar voices. Experimental results on the benchmark datasets WSJ0-2mix and WHAM! show that ISCIT can achieve state-of-the-art results.