 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACM: Correct the Output of Deep Neural Network with Middle Layers Features against Adversarial Samples
Paper and Code
Jun 02, 2022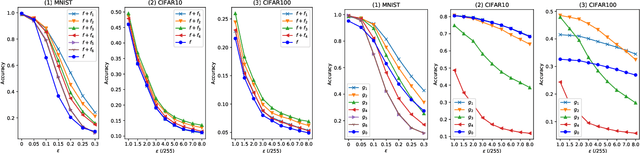
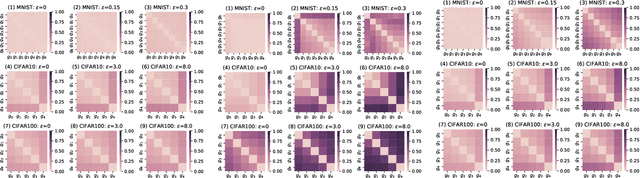


In the strong adversarial attacks against deep neural network (DNN), the output of DNN will be misclassified if and only if the last feature layer of the DNN is completely destroyed by adversarial samples, while our studies found that the middle feature layers of the DNN can still extract the effective features of the original normal category in these adversarial attacks. To this end, in this paper, a middle $\bold{F}$eature layer $\bold{A}$nalysis and $\bold{C}$onditional $\bold{M}$atching prediction distribution (FACM) model is proposed to increase the robustness of the DNN against adversarial samples through correcting the output of DNN with the features extracted by the middle layers of DNN. In particular, the middle $\bold{F}$eature layer $\bold{A}$nalysis (FA) module, the conditional matching prediction distribution (CMPD) module and the output decision module are included in our FACM model to collaboratively correct the classification of adversarial samples. The experiments results show that, our FACM model can significantly improve the robustness of the naturally trained model against various attacks, and our FA model can significantly improve the robustness of the adversarially trained model against white-box attacks with weak transferability and black box attacks where FA model includes the FA module and the output decision module, not the CMPD module.