 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Semantic-Thinking: A Robust Strategy to Distill Reasoning Capacity from Large Language Models
Paper and Code
Apr 14, 2024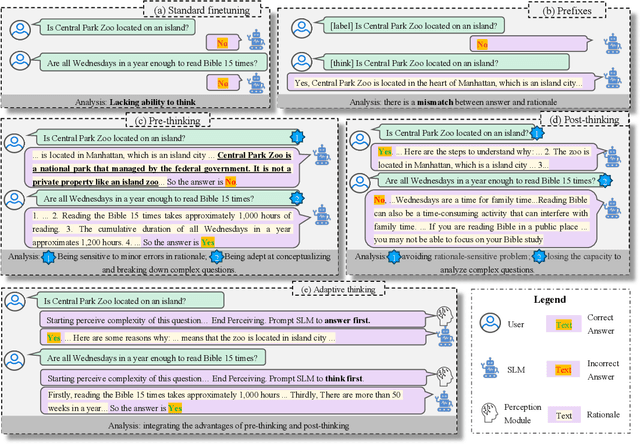
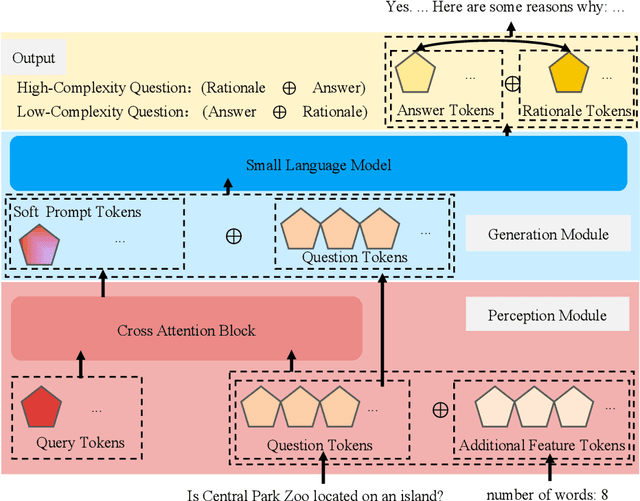
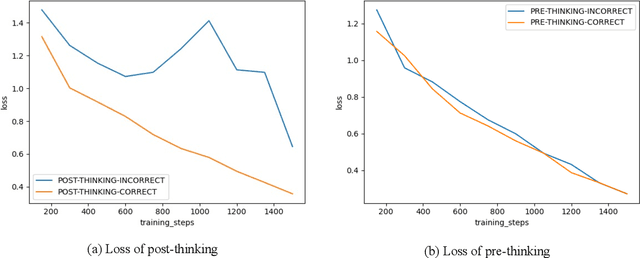
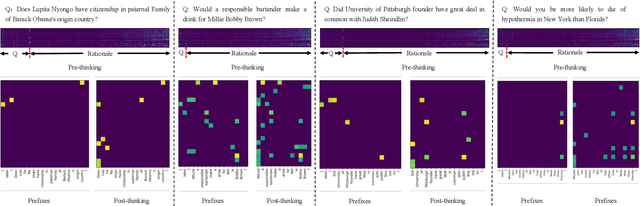
Chain of thought finetuning aims to endow small student models with reasoning capacity to improve their performance towards a specific task by allowing them to imitate the reasoning procedure of large language models (LLMs) beyond simply predicting the answer to the question. However, the existing methods 1) generate rationale before the answer, making their answer correctness sensitive to the hallucination in the rationale;2) force the student model to repeat the exact LLMs rationale expression word-after-word, which could have the model biased towards learning the expression in rationale but count against the model from understanding the core logic behind it. Therefore, we propose a robust Post-Semantic-Thinking (PST) strategy to generate answers before rationale. Thanks to this answer-first setting, 1) the answering procedure can escape from the adverse effects caused by hallucinations in the rationale; 2) the complex reasoning procedure is tightly bound with the relatively concise answer, making the reasoning for questions easier with the prior information in the answer; 3) the efficiency of the method can also benefit from the setting since users can stop the generation right after answers are outputted when inference is conducted. Furthermore, the PST strategy loose the constraint against the generated rationale to be close to the LLMs gold standard in the hidden semantic space instead of the vocabulary space, thus making the small student model better comprehend the semantic reasoning logic in rationale. Extensive experiments conducted across 12 reasoning tasks demonstrate the effectiveness of PST.