 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Paper and Code
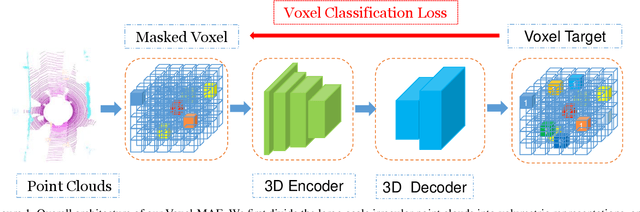
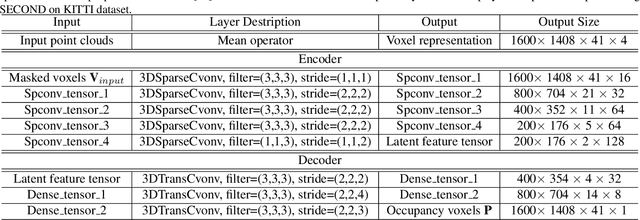
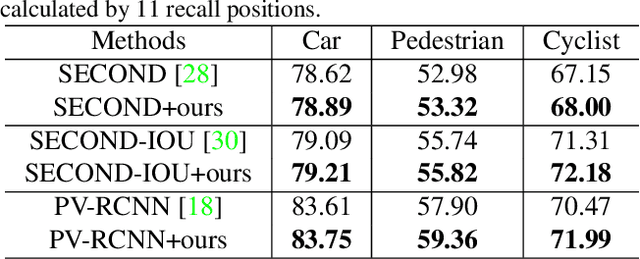
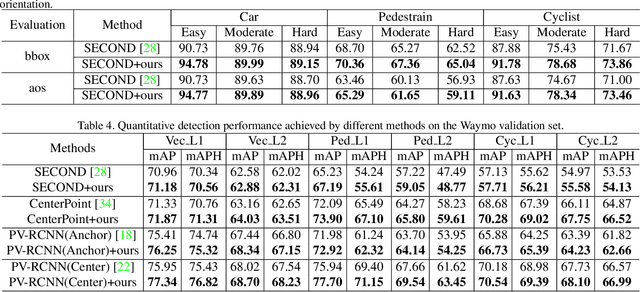
Mask-based pre-training has achieved great success for self-supervised learning in image, video, and language, without manually annotated supervision. However, it has not yet been studied about large-scale point clouds with redundant spatial information in autonomous driving. As the number of large-scale point clouds is huge, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of the downstream tasks, such as 3D object detection. Our Voxel-MAE with even a 90% masking ratio can still learn representative features for the high spatial redundancy of large-scale point clouds. We also validate the effectiveness of Voxel-MAE in unsupervised domain adaptative tasks, which proves the generalization ability of Voxel-MAE. Our Voxel-MAE proves that it is feasible to pre-train large-scale point clouds without data annotations to enhance the perception ability of the autonomous vehicle. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on two popular datasets (KITTI, Waymo). Codes are publicly available at https://github.com/chaytonmin/Voxel-MAE.