 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLDetector: Defending Federated Learning Against Model Poisoning Attacks via Detecting Malicious Clients
Jul 20, 2022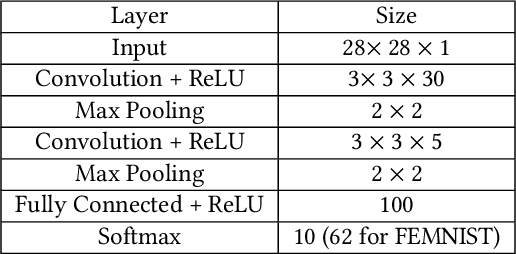



Federated learning (FL) is vulnerable to model poisoning attacks, in which malicious clients corrupt the global model via sending manipulated model updates to the server. Existing defenses mainly rely on Byzantine-robust FL methods, which aim to learn an accurate global model even if some clients are malicious. However, they can only resist a small number of malicious clients in practice. It is still an open challenge how to defend against model poisoning attacks with a large number of malicious clients. Our FLDetector addresses this challenge via detecting malicious clients. FLDetector aims to detect and remove the majority of the malicious clients such that a Byzantine-robust FL method can learn an accurate global model using the remaining clients. Our key observation is that, in model poisoning attacks, the model updates from a client in multiple iterations are inconsistent. Therefore, FLDetector detects malicious clients via checking their model-updates consistency. Roughly speaking, the server predicts a client's model update in each iteration based on its historical model updates using the Cauchy mean value theorem and L-BFGS, and flags a client as malicious if the received model update from the client and the predicted model update are inconsistent in multiple iterations. Our extensive experiments on three benchmark datasets show that FLDetector can accurately detect malicious clients in multiple state-of-the-art model poisoning attacks. After removing the detected malicious clients, existing Byzantine-robust FL methods can learn accurate global models.Our code is available at https://github.com/zaixizhang/FLDetector.