 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAF: Judge Agent Forest
Jan 29, 2026Judge agents are fundamental to agentic AI frameworks: they provide automated evaluation, and enable iterative self-refinement of reasoning processes. We introduce JAF: Judge Agent Forest, a framework in which the judge agent conducts joint inference across a cohort of query--response pairs generated by a primary agent, rather than evaluating each in isolation. This paradigm elevates the judge from a local evaluator to a holistic learner: by simultaneously assessing related responses, the judge discerns cross-instance patterns and inconsistencies, whose aggregate feedback enables the primary agent to improve by viewing its own outputs through the judge's collective perspective. Conceptually, JAF bridges belief propagation and ensemble-learning principles: overlapping in-context neighborhoods induce a knowledge-graph structure that facilitates propagation of critique, and repeated, randomized evaluations yield a robust ensemble of context-sensitive judgments. JAF can be instantiated entirely via ICL, with the judge prompted for each query using its associated primary-agent response plus a small, possibly noisy set of peer exemplars. While kNN in embedding space is a natural starting point for exemplars, this approach overlooks categorical structure, domain metadata, or nuanced distinctions accessible to modern LLMs. To overcome these limitations, we develop a flexible locality-sensitive hashing (LSH) algorithm that learns informative binary codes by integrating semantic embeddings, LLM-driven hash predicates, supervision from categorical labels, and relevant side information. These hash codes support efficient, interpretable, and relation-aware selection of diverse exemplars, and further optimize exploration of CoT reasoning paths. We validate JAF with an empirical study on the demanding task of cloud misconfigs triage in large-scale cloud environments.
Machine learning empowered Modulation detection for OFDM-based signals
Aug 15, 2024We propose a blind ML-based modulation detection for OFDM-based technologies. Unlike previous works that assume an ideal environment with precise knowledge of subcarrier count and cyclic prefix location, we consider blind modulation detection while accounting for realistic environmental parameters and imperfections. Our approach employs a ResNet network to simultaneously detect the modulation type and accurately locate the cyclic prefix. Specifically, after eliminating the environmental impact from the signal and accurately extracting the OFDM symbols, we convert these symbols into scatter plots. Due to their unique shapes, these scatter plots are then classified using ResNet. As a result, our proposed modulation classification method can be applied to any OFDM-based technology without prior knowledge of the transmitted signal. We evaluate its performance across various modulation schemes and subcarrier numbers. Simulation results show that our method achieves a modulation detection accuracy exceeding $80\%$ at an SNR of $10$ dB and $95\%$ at an SNR of $25$ dB.
Deep Generative Sampling in the Dual Divergence Space: A Data-efficient & Interpretative Approach for Generative AI
Apr 10, 2024



Building on the remarkable achievements in generative sampling of natural images, we propose an innovative challenge, potentially overly ambitious, which involves generating samples of entire multivariate time series that resemble images. However, the statistical challenge lies in the small sample size, sometimes consisting of a few hundred subjects. This issue is especially problematic for deep generative models that follow the conventional approach of generating samples from a canonical distribution and then decoding or denoising them to match the true data distribution. In contrast, our method is grounded in information theory and aims to implicitly characterize the distribution of images, particularly the (global and local) dependency structure between pixels. We achieve this by empirically estimating its KL-divergence in the dual form with respect to the respective marginal distribution. This enables us to perform generative sampling directly in the optimized 1-D dual divergence space. Specifically, in the dual space, training samples representing the data distribution are embedded in the form of various clusters between two end points. In theory, any sample embedded between those two end points is in-distribution w.r.t. the data distribution. Our key idea for generating novel samples of images is to interpolate between the clusters via a walk as per gradients of the dual function w.r.t. the data dimensions. In addition to the data efficiency gained from direct sampling, we propose an algorithm that offers a significant reduction in sample complexity for estimating the divergence of the data distribution with respect to the marginal distribution. We provide strong theoretical guarantees along with an extensive empirical evaluation using many real-world datasets from diverse domains, establishing the superiority of our approach w.r.t. state-of-the-art deep learning methods.
$\textbf{S}^2$IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
Mar 09, 2024



Recently, there has been a growing interest in leveraging pre-trained large language models (LLMs) for various time series applications. However, the semantic space of LLMs, established through the pre-training, is still underexplored and may help yield more distinctive and informative representations to facilitate time series forecasting. To this end, we propose Semantic Space Informed Prompt learning with LLM ($S^2$IP-LLM) to align the pre-trained semantic space with time series embeddings space and perform time series forecasting based on learned prompts from the joint space. We first design a tokenization module tailored for cross-modality alignment, which explicitly concatenates patches of decomposed time series components to create embeddings that effectively encode the temporal dynamics. Next, we leverage the pre-trained word token embeddings to derive semantic anchors and align selected anchors with time series embeddings by maximizing the cosine similarity in the joint space. This way, $S^2$IP-LLM can retrieve relevant semantic anchors as prompts to provide strong indicators (context) for time series that exhibit different temporal dynamics. With thorough empirical studies on multiple benchmark datasets, we demonstrate that the proposed $S^2$IP-LLM can achieve superior forecasting performance over state-of-the-art baselines. Furthermore, our ablation studies and visualizations verify the necessity of prompt learning informed by semantic space.
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024



Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.
Empowering Time Series Analysis with Large Language Models: A Survey
Feb 05, 2024Recently, remarkable progress has been made over large language models (LLMs), demonstrating their unprecedented capability in varieties of natural language tasks. However, completely training a large general-purpose model from the scratch is challenging for time series analysis, due to the large volumes and varieties of time series data, as well as the non-stationarity that leads to concept drift impeding continuous model adaptation and re-training. Recent advances have shown that pre-trained LLMs can be exploited to capture complex dependencies in time series data and facilitate various applications. In this survey, we provide a systematic overview of existing methods that leverage LLMs for time series analysis. Specifically, we first state the challenges and motivations of applying language models in the context of time series as well as brief preliminaries of LLMs. Next, we summarize the general pipeline for LLM-based time series analysis, categorize existing methods into different groups (i.e., direct query, tokenization, prompt design, fine-tune, and model integration), and highlight the key ideas within each group. We also discuss the applications of LLMs for both general and spatial-temporal time series data, tailored to specific domains. Finally, we thoroughly discuss future research opportunities to empower time series analysis with LLMs.
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023
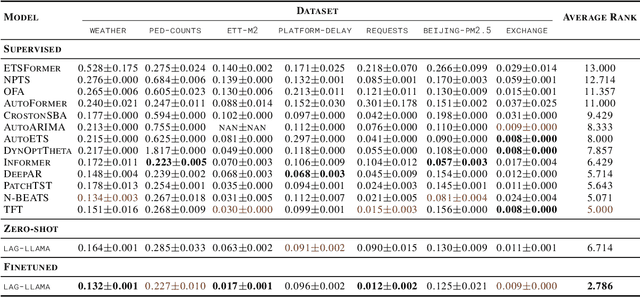

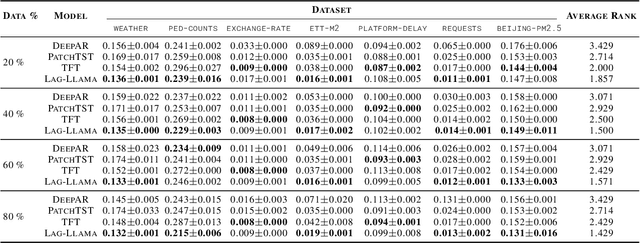
Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.
Structural block driven - enhanced convolutional neural representation for relation extraction
Mar 21, 2021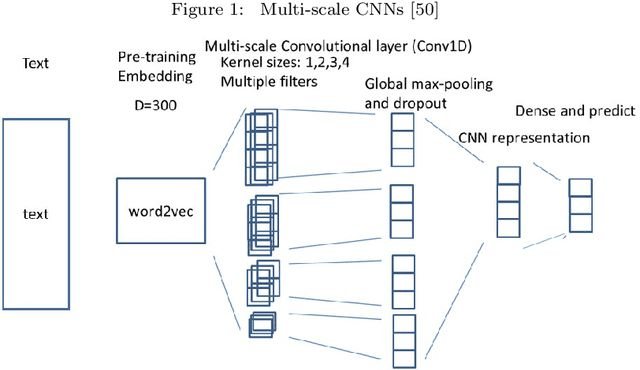
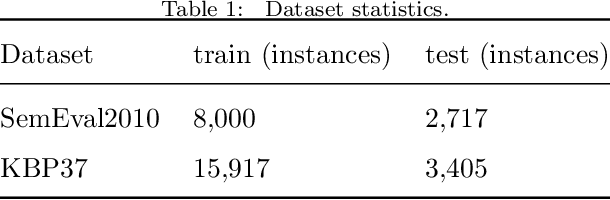
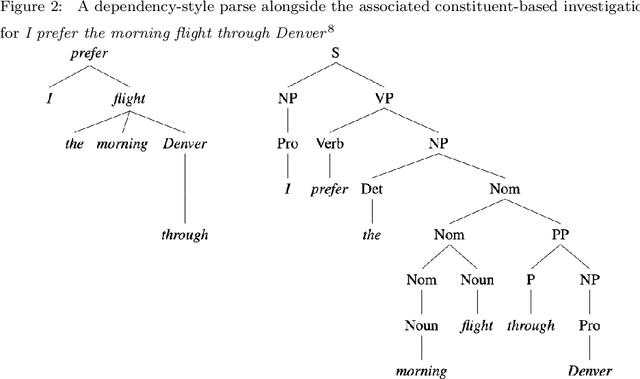
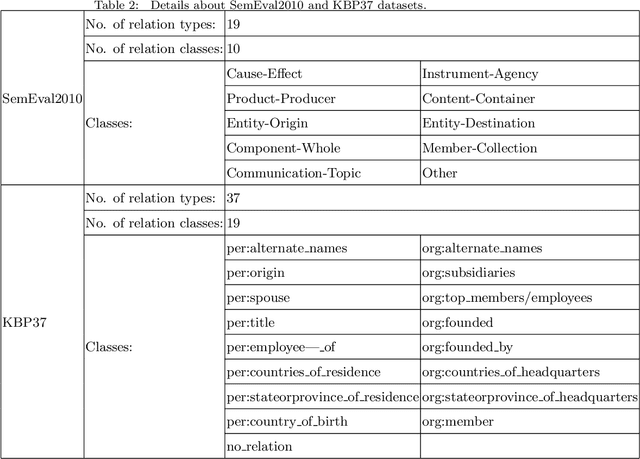
In this paper, we propose a novel lightweight relation extraction approach of structural block driven - convolutional neural learning. Specifically, we detect the essential sequential tokens associated with entities through dependency analysis, named as a structural block, and only encode the block on a block-wise and an inter-block-wise representation, utilizing multi-scale CNNs. This is to 1) eliminate the noisy from irrelevant part of a sentence; meanwhile 2) enhance the relevant block representation with both block-wise and inter-block-wise semantically enriched representation. Our method has the advantage of being independent of long sentence context since we only encode the sequential tokens within a block boundary. Experiments on two datasets i.e., SemEval2010 and KBP37, demonstrate the significant advantages of our method. In particular, we achieve the new state-of-the-art performance on the KBP37 dataset; and comparable performance with the state-of-the-art on the SemEval2010 dataset.
Deep Anomaly Detection for Time-series Data in Industrial IoT: A Communication-Efficient On-device Federated Learning Approach
Jul 19, 2020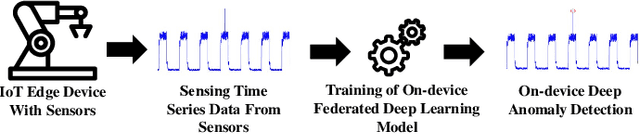

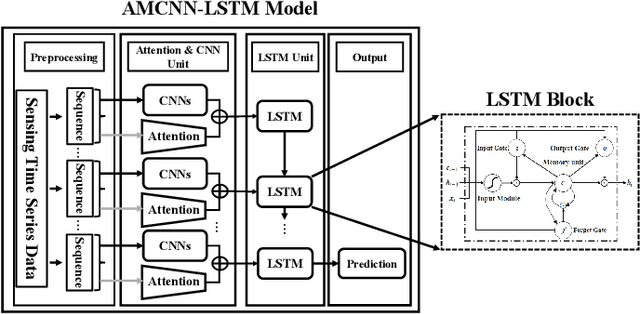
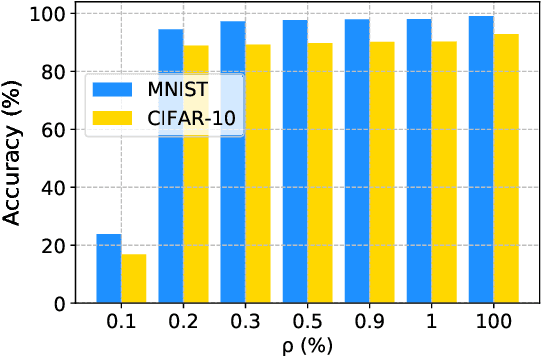
Since edge device failures (i.e., anomalies) seriously affect the production of industrial products in Industrial IoT (IIoT), accurately and timely detecting anomalies is becoming increasingly important. Furthermore, data collected by the edge device may contain the user's private data, which is challenging the current detection approaches as user privacy is calling for the public concern in recent years. With this focus, this paper proposes a new communication-efficient on-device federated learning (FL)-based deep anomaly detection framework for sensing time-series data in IIoT. Specifically, we first introduce a FL framework to enable decentralized edge devices to collaboratively train an anomaly detection model, which can improve its generalization ability. Second, we propose an Attention Mechanism-based Convolutional Neural Network-Long Short Term Memory (AMCNN-LSTM) model to accurately detect anomalies. The AMCNN-LSTM model uses attention mechanism-based CNN units to capture important fine-grained features, thereby preventing memory loss and gradient dispersion problems. Furthermore, this model retains the advantages of LSTM unit in predicting time series data. Third, to adapt the proposed framework to the timeliness of industrial anomaly detection, we propose a gradient compression mechanism based on Top-\textit{k} selection to improve communication efficiency. Extensive experiment studies on four real-world datasets demonstrate that the proposed framework can accurately and timely detect anomalies and also reduce the communication overhead by 50\% compared to the federated learning framework that does not use a gradient compression scheme.
An RNN-Survival Model to Decide Email Send Times
Apr 21, 2020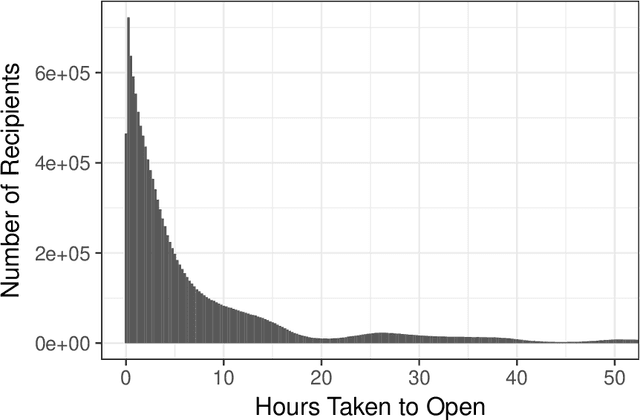

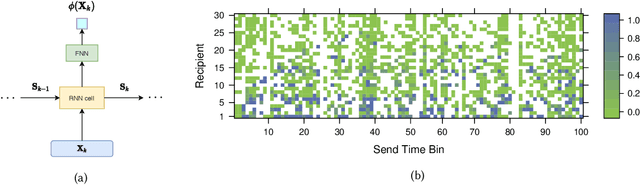
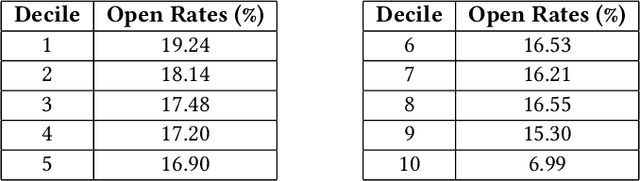
Email communications are ubiquitous. Firms control send times of emails and thereby the instants at which emails reach recipients (it is assumed email is received instantaneously from the send time). However, they do not control the duration it takes for recipients to open emails, labeled as time-to-open. Importantly, among emails that are opened, most occur within a short window from their send times. We posit that emails are likely to be opened sooner when send times are convenient for recipients, while for other send times, emails can get ignored. Thus, to compute appropriate send times it is important to predict times-to-open accurately. We propose a recurrent neural network (RNN) in a survival model framework to predict times-to-open, for each recipient. Using that we compute appropriate send times. We experiment on a data set of emails sent to a million customers over five months. The sequence of emails received by a person from a sender is a result of interactions with past emails from the sender, and hence contain useful signal that inform our model. This sequential dependence affords our proposed RNN-Survival (RNN-S) approach to outperform survival analysis approaches in predicting times-to-open. We show that best times to send emails can be computed accurately from predicted times-to-open. This approach allows a firm to tune send times of emails, which is in its control, to favorably influence open rates and engagement.