 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Multipliers: Freeing the Scale of Language Model Matrix Layers
Jan 08, 2026Applying weight decay (WD) to matrix layers is standard practice in large-language-model pretraining. Prior work suggests that stochastic gradient noise induces a Brownian-like expansion of the weight matrices W, whose growth is counteracted by WD, leading to a WD-noise equilibrium with a certain weight norm ||W||. In this work, we view the equilibrium norm as a harmful artifact of the training procedure, and address it by introducing learnable multipliers to learn the optimal scale. First, we attach a learnable scalar multiplier to W and confirm that the WD-noise equilibrium norm is suboptimal: the learned scale adapts to data and improves performance. We then argue that individual row and column norms are similarly constrained, and free their scale by introducing learnable per-row and per-column multipliers. Our method can be viewed as a learnable, more expressive generalization of muP multipliers. It outperforms a well-tuned muP baseline, reduces the computational overhead of multiplier tuning, and surfaces practical questions such as forward-pass symmetries and the width-scaling of the learned multipliers. Finally, we validate learnable multipliers with both Adam and Muon optimizers, where it shows improvement in downstream evaluations matching the improvement of the switching from Adam to Muon.
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Jul 30, 2025In this report, we introduce Falcon-H1, a new series of large language models (LLMs) featuring hybrid architecture designs optimized for both high performance and efficiency across diverse use cases. Unlike earlier Falcon models built solely on Transformer or Mamba architectures, Falcon-H1 adopts a parallel hybrid approach that combines Transformer-based attention with State Space Models (SSMs), known for superior long-context memory and computational efficiency. We systematically revisited model design, data strategy, and training dynamics, challenging conventional practices in the field. Falcon-H1 is released in multiple configurations, including base and instruction-tuned variants at 0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B parameters. Quantized instruction-tuned models are also available, totaling over 30 checkpoints on Hugging Face Hub. Falcon-H1 models demonstrate state-of-the-art performance and exceptional parameter and training efficiency. The flagship Falcon-H1-34B matches or outperforms models up to 70B scale, such as Qwen3-32B, Qwen2.5-72B, and Llama3.3-70B, while using fewer parameters and less data. Smaller models show similar trends: the Falcon-H1-1.5B-Deep rivals current leading 7B-10B models, and Falcon-H1-0.5B performs comparably to typical 7B models from 2024. These models excel across reasoning, mathematics, multilingual tasks, instruction following, and scientific knowledge. With support for up to 256K context tokens and 18 languages, Falcon-H1 is suitable for a wide range of applications. All models are released under a permissive open-source license, underscoring our commitment to accessible and impactful AI research.
NeurIPS 2025 E2LM Competition : Early Training Evaluation of Language Models
Jun 09, 2025Existing benchmarks have proven effective for assessing the performance of fully trained large language models. However, we find striking differences in the early training stages of small models, where benchmarks often fail to provide meaningful or discriminative signals. To explore how these differences arise, this competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with limited computational resources. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their relevance to the scientific knowledge domain. By promoting the design of tailored evaluation strategies for early training, this competition aims to attract a broad range of participants from various disciplines, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Falcon Mamba: The First Competitive Attention-free 7B Language Model
Oct 07, 2024



In this technical report, we present Falcon Mamba 7B, a new base large language model based on the novel Mamba architecture. Falcon Mamba 7B is trained on 5.8 trillion tokens with carefully selected data mixtures. As a pure Mamba-based model, Falcon Mamba 7B surpasses leading open-weight models based on Transformers, such as Mistral 7B, Llama3.1 8B, and Falcon2 11B. It is on par with Gemma 7B and outperforms models with different architecture designs, such as RecurrentGemma 9B and RWKV-v6 Finch 7B/14B. Currently, Falcon Mamba 7B is the best-performing Mamba model in the literature at this scale, surpassing both existing Mamba and hybrid Mamba-Transformer models, according to the Open LLM Leaderboard. Due to its architecture, Falcon Mamba 7B is significantly faster at inference and requires substantially less memory for long sequence generation. Despite recent studies suggesting that hybrid Mamba-Transformer models outperform pure architecture designs, we demonstrate that even the pure Mamba design can achieve similar, or even superior results compared to the Transformer and hybrid designs. We make the weights of our implementation of Falcon Mamba 7B publicly available on https://huggingface.co/tiiuae/falcon-mamba-7b, under a permissive license.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Distributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
Zephyr: Direct Distillation of LM Alignment
Oct 25, 2023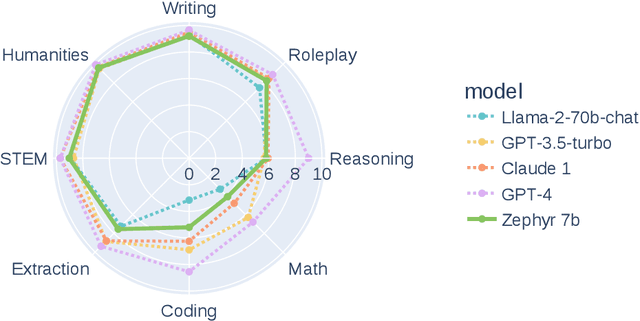
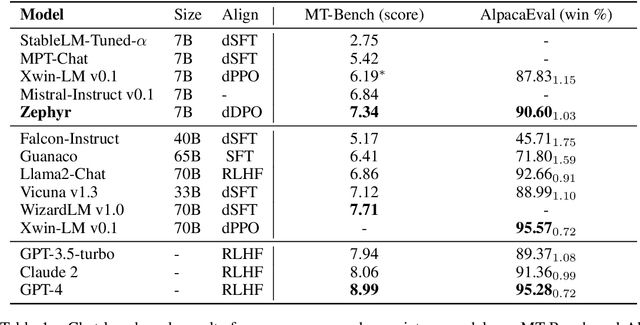
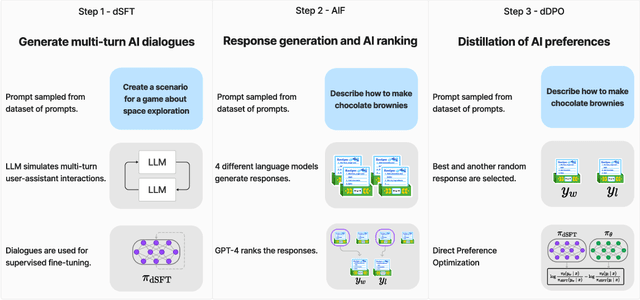
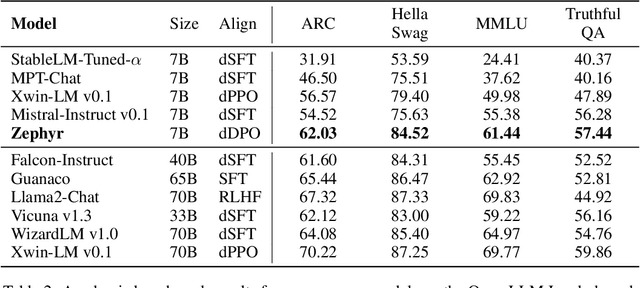
We aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural prompts. To distill this property, we experiment with the use of preference data from AI Feedback (AIF). Starting from a dataset of outputs ranked by a teacher model, we apply distilled direct preference optimization (dDPO) to learn a chat model with significantly improved intent alignment. The approach requires only a few hours of training without any additional sampling during fine-tuning. The final result, Zephyr-7B, sets the state-of-the-art on chat benchmarks for 7B parameter models, and requires no human annotation. In particular, results on MT-Bench show that Zephyr-7B surpasses Llama2-Chat-70B, the best open-access RLHF-based model. Code, models, data, and tutorials for the system are available at https://github.com/huggingface/alignment-handbook.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Petals: Collaborative Inference and Fine-tuning of Large Models
Sep 02, 2022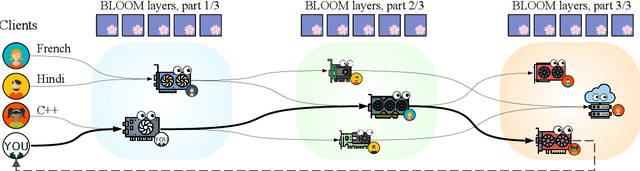


Many NLP tasks benefit from using large language models (LLMs) that often have more than 100 billion parameters. With the release of BLOOM-176B and OPT-175B, everyone can download pretrained models of this scale. Still, using these models requires high-end hardware unavailable to many researchers. In some cases, LLMs can be used more affordably via RAM offloading or hosted APIs. However, these techniques have innate limitations: offloading is too slow for interactive inference, while APIs are not flexible enough for research. In this work, we propose Petals $-$ a system for inference and fine-tuning of large models collaboratively by joining the resources of multiple parties trusted to process client's data. We demonstrate that this strategy significantly outperforms offloading for very large models, running inference of BLOOM-176B on consumer GPUs with $\approx$ 1 step per second. Unlike most inference APIs, Petals also natively exposes the hidden states of served models, allowing its users to train and share custom model extensions based on efficient fine-tuning methods.
LLM.int8: 8-bit Matrix Multiplication for Transformers at Scale
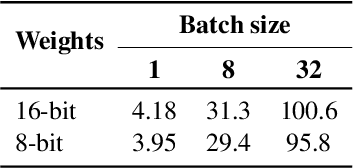
Aug 15, 2022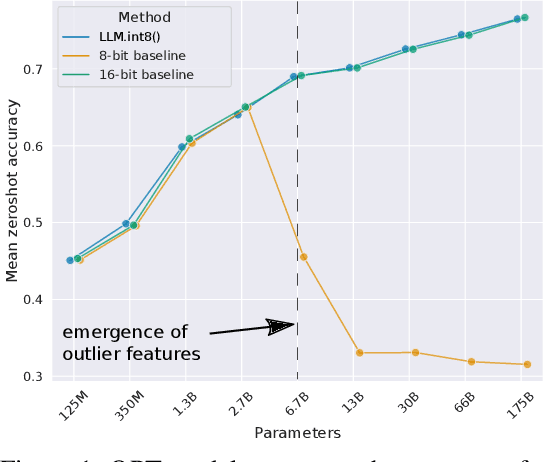



Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers in transformers, which cut the memory needed for inference by half while retaining full precision performance. With our method, a 175B parameter 16/32-bit checkpoint can be loaded, converted to Int8, and used immediately without performance degradation. This is made possible by understanding and working around properties of highly systematic emergent features in transformer language models that dominate attention and transformer predictive performance. To cope with these features, we develop a two-part quantization procedure, LLM.int8(). We first use vector-wise quantization with separate normalization constants for each inner product in the matrix multiplication, to quantize most of the features. However, for the emergent outliers, we also include a new mixed-precision decomposition scheme, which isolates the outlier feature dimensions into a 16-bit matrix multiplication while still more than 99.9% of values are multiplied in 8-bit. Using LLM.int8(), we show empirically it is possible to perform inference in LLMs with up to 175B parameters without any performance degradation. This result makes such models much more accessible, for example making it possible to use OPT-175B/BLOOM on a single server with consumer GPUs.