 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMashup Learning: Faster Finetuning by Remixing Past Checkpoints
Mar 10, 2026Finetuning on domain-specific data is a well-established method for enhancing LLM performance on downstream tasks. Training on each dataset produces a new set of model weights, resulting in a multitude of checkpoints saved in-house or on open-source platforms. However, these training artifacts are rarely reused for subsequent experiments despite containing improved model abilities for potentially similar tasks. In this paper, we propose Mashup Learning, a simple method to leverage the outputs of prior training runs to enhance model adaptation to new tasks. Our procedure identifies the most relevant historical checkpoints for a target dataset, aggregates them with model merging, and uses the result as an improved initialization for training. Across 8 standard LLM benchmarks, four models, and two collections of source checkpoints, Mashup Learning consistently improves average downstream accuracy by 0.5-5 percentage points over training from scratch. It also accelerates convergence, requiring 41-46% fewer training steps and up to 37% less total wall-clock time to match from-scratch accuracy, including all selection and merging overhead.
Distributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
Petals: Collaborative Inference and Fine-tuning of Large Models
Sep 02, 2022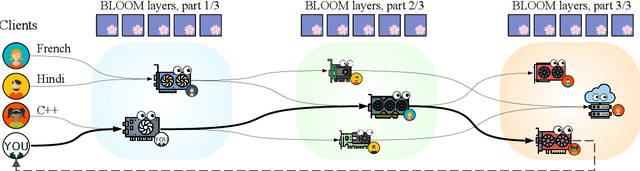


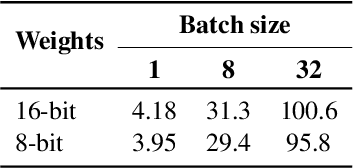
Many NLP tasks benefit from using large language models (LLMs) that often have more than 100 billion parameters. With the release of BLOOM-176B and OPT-175B, everyone can download pretrained models of this scale. Still, using these models requires high-end hardware unavailable to many researchers. In some cases, LLMs can be used more affordably via RAM offloading or hosted APIs. However, these techniques have innate limitations: offloading is too slow for interactive inference, while APIs are not flexible enough for research. In this work, we propose Petals $-$ a system for inference and fine-tuning of large models collaboratively by joining the resources of multiple parties trusted to process client's data. We demonstrate that this strategy significantly outperforms offloading for very large models, running inference of BLOOM-176B on consumer GPUs with $\approx$ 1 step per second. Unlike most inference APIs, Petals also natively exposes the hidden states of served models, allowing its users to train and share custom model extensions based on efficient fine-tuning methods.
Weight Squeezing: Reparameterization for Compression and Fast Inference
Oct 14, 2020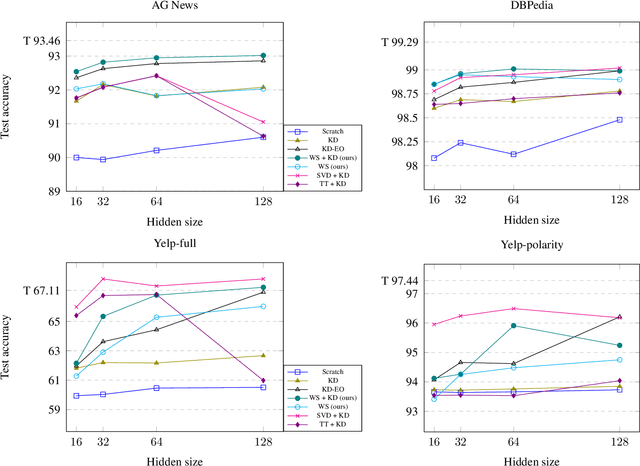
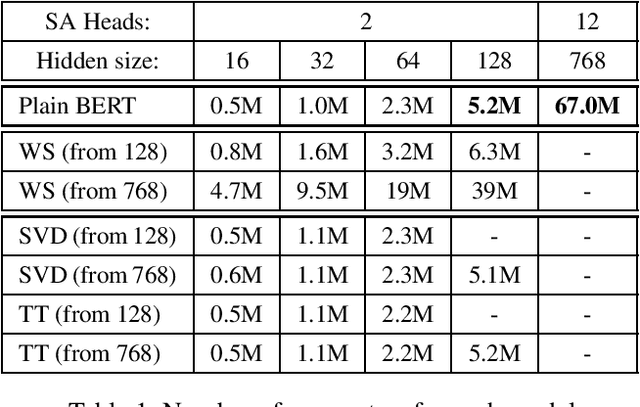
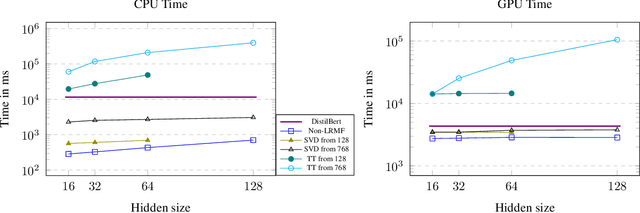
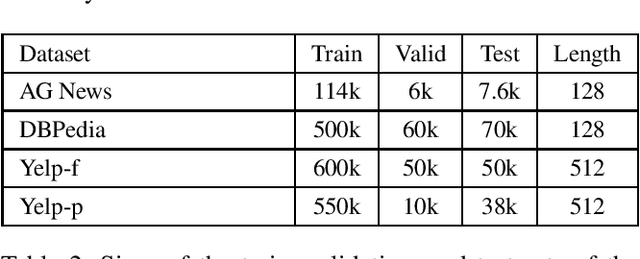
In this work, we present a novel approach for simultaneous knowledge transfer and model compression called Weight Squeezing. With this method, we perform knowledge transfer from a pre-trained teacher model by learning the mapping from its weights to smaller student model weights, without significant loss of model accuracy. We applied Weight Squeezing combined with Knowledge Distillation to a pre-trained text classification model, and compared it to various knowledge transfer and model compression methods on several downstream text classification tasks. We observed that our approach produces better results than Knowledge Distillation methods without any loss in inference speed. We also compared Weight Squeezing with Low Rank Factorization methods and observed that our method is significantly faster at inference while being competitive in terms of accuracy.