 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Squeezing: Reparameterization for Compression and Fast Inference
Paper and Code
Oct 14, 2020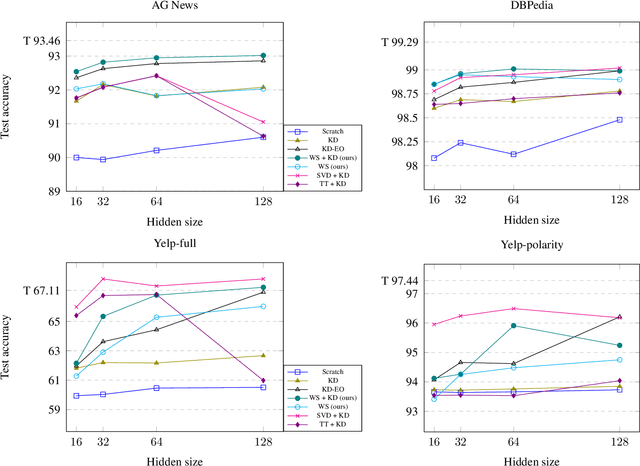
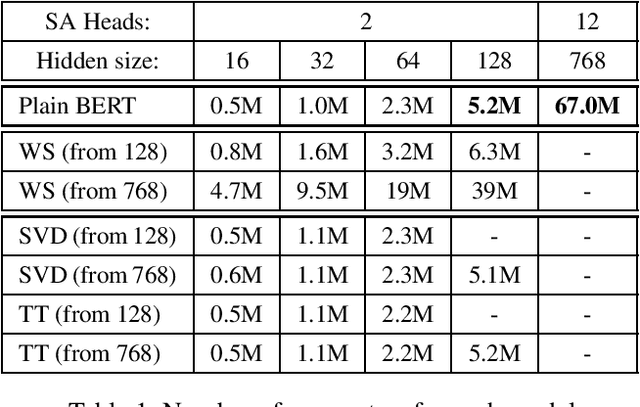
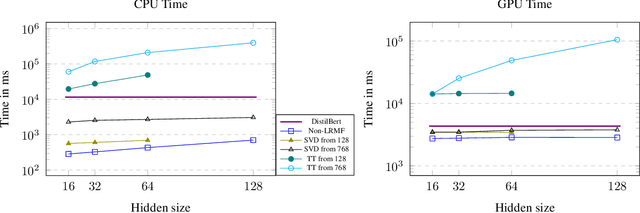
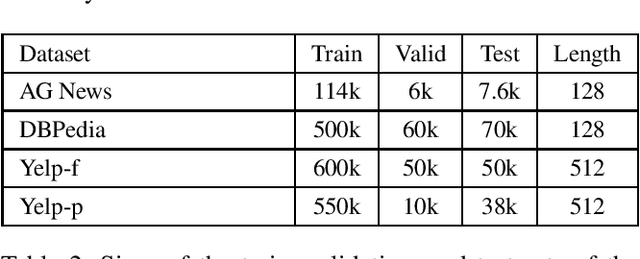
In this work, we present a novel approach for simultaneous knowledge transfer and model compression called Weight Squeezing. With this method, we perform knowledge transfer from a pre-trained teacher model by learning the mapping from its weights to smaller student model weights, without significant loss of model accuracy. We applied Weight Squeezing combined with Knowledge Distillation to a pre-trained text classification model, and compared it to various knowledge transfer and model compression methods on several downstream text classification tasks. We observed that our approach produces better results than Knowledge Distillation methods without any loss in inference speed. We also compared Weight Squeezing with Low Rank Factorization methods and observed that our method is significantly faster at inference while being competitive in terms of accuracy.