 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
Jan 11, 2021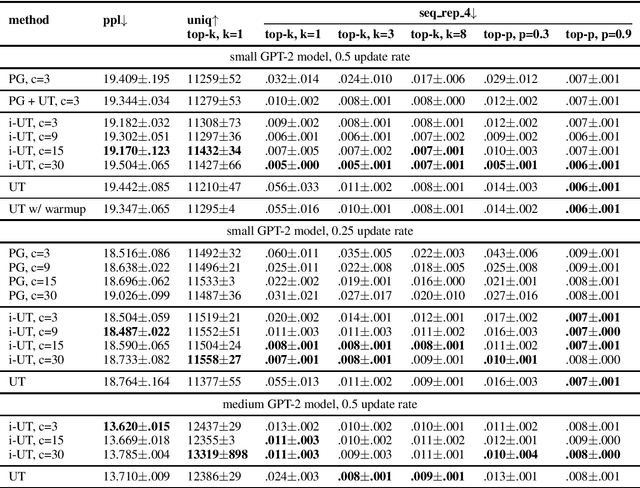
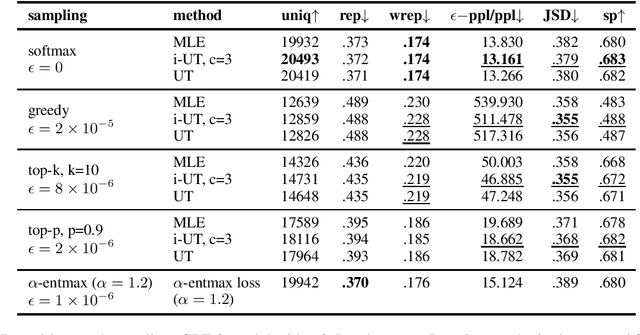

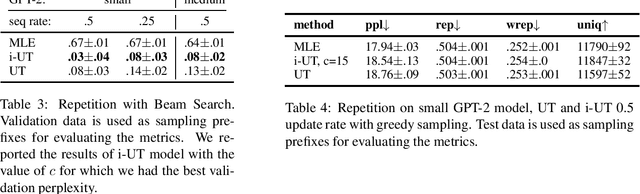
Likelihood training and maximization-based decoding result in dull and repetitive generated texts even when using powerful language models (Holtzman et al., 2019). Adding a loss function for regularization was shown to improve text generation output by helping avoid unwanted properties, such as contradiction or repetition (Li at al., 2020). In this work, we propose fine-tuning a language model by using policy gradient reinforcement learning, directly optimizing for better generation. We apply this approach to minimizing repetition in generated text, and show that, when combined with unlikelihood training (Welleck et al., 2020), our method further reduces repetition without impacting the language model quality. We also evaluate other methods for improving generation at training and decoding time, and compare them using various metrics aimed at control for better text generation output.
Reducing Unintended Identity Bias in Russian Hate Speech Detection
Oct 22, 2020

Toxicity has become a grave problem for many online communities and has been growing across many languages, including Russian. Hate speech creates an environment of intimidation, discrimination, and may even incite some real-world violence. Both researchers and social platforms have been focused on developing models to detect toxicity in online communication for a while now. A common problem of these models is the presence of bias towards some words (e.g. woman, black, jew) that are not toxic, but serve as triggers for the classifier due to model caveats. In this paper, we describe our efforts towards classifying hate speech in Russian, and propose simple techniques of reducing unintended bias, such as generating training data with language models using terms and words related to protected identities as context and applying word dropout to such words.
Weight Squeezing: Reparameterization for Compression and Fast Inference
Oct 14, 2020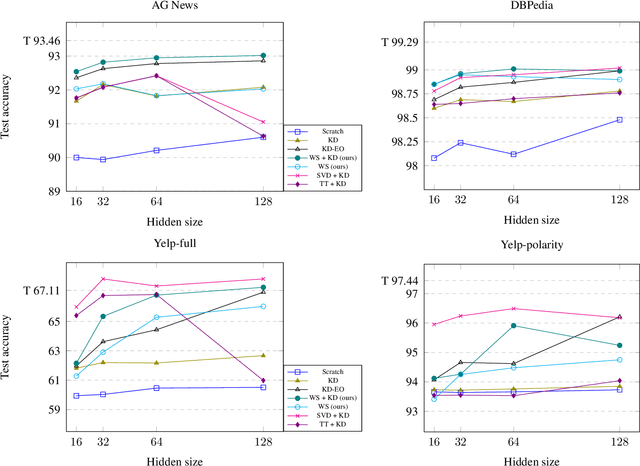
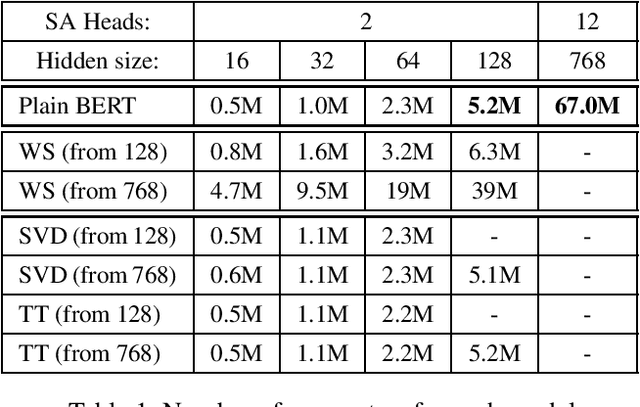
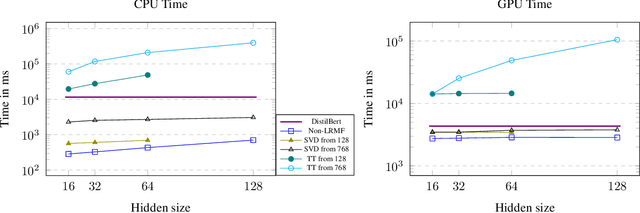
In this work, we present a novel approach for simultaneous knowledge transfer and model compression called Weight Squeezing. With this method, we perform knowledge transfer from a pre-trained teacher model by learning the mapping from its weights to smaller student model weights, without significant loss of model accuracy. We applied Weight Squeezing combined with Knowledge Distillation to a pre-trained text classification model, and compared it to various knowledge transfer and model compression methods on several downstream text classification tasks. We observed that our approach produces better results than Knowledge Distillation methods without any loss in inference speed. We also compared Weight Squeezing with Low Rank Factorization methods and observed that our method is significantly faster at inference while being competitive in terms of accuracy.
Self-Attentive Model for Headline Generation
Jan 23, 2019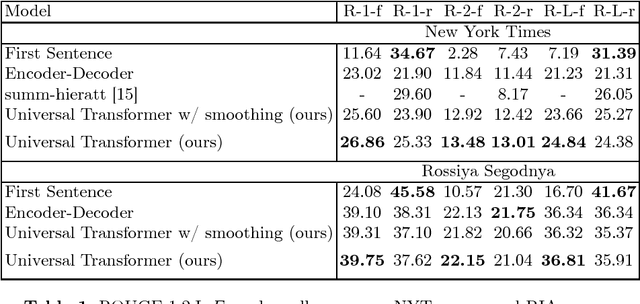


Headline generation is a special type of text summarization task. While the amount of available training data for this task is almost unlimited, it still remains challenging, as learning to generate headlines for news articles implies that the model has strong reasoning about natural language. To overcome this issue, we applied recent Universal Transformer architecture paired with byte-pair encoding technique and achieved new state-of-the-art results on the New York Times Annotated corpus with ROUGE-L F1-score 24.84 and ROUGE-2 F1-score 13.48. We also present the new RIA corpus and reach ROUGE-L F1-score 36.81 and ROUGE-2 F1-score 22.15 on it.