 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEx$^2$MCMC: Sampling through Exploration Exploitation
Nov 04, 2021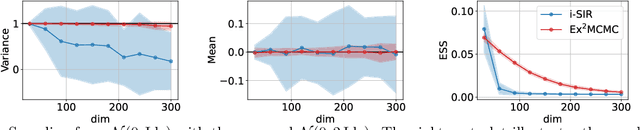
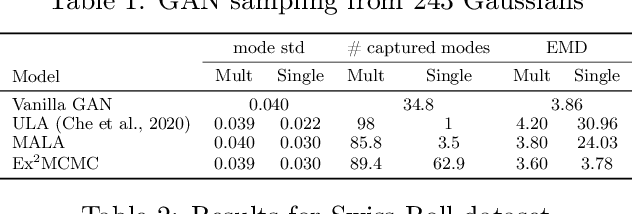
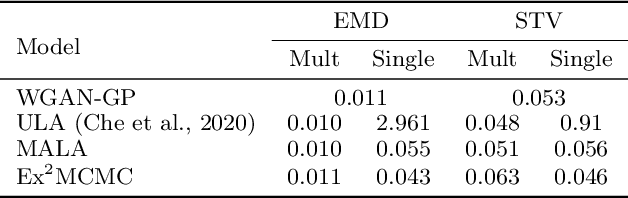
We develop an Explore-Exploit Markov chain Monte Carlo algorithm ($\operatorname{Ex^2MCMC}$) that combines multiple global proposals and local moves. The proposed method is massively parallelizable and extremely computationally efficient. We prove $V$-uniform geometric ergodicity of $\operatorname{Ex^2MCMC}$ under realistic conditions and compute explicit bounds on the mixing rate showing the improvement brought by the multiple global moves. We show that $\operatorname{Ex^2MCMC}$ allows fine-tuning of exploitation (local moves) and exploration (global moves) via a novel approach to proposing dependent global moves. Finally, we develop an adaptive scheme, $\operatorname{FlEx^2MCMC}$, that learns the distribution of global moves using normalizing flows. We illustrate the efficiency of $\operatorname{Ex^2MCMC}$ and its adaptive versions on many classical sampling benchmarks. We also show that these algorithms improve the quality of sampling GANs as energy-based models.
Implicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
Jan 11, 2021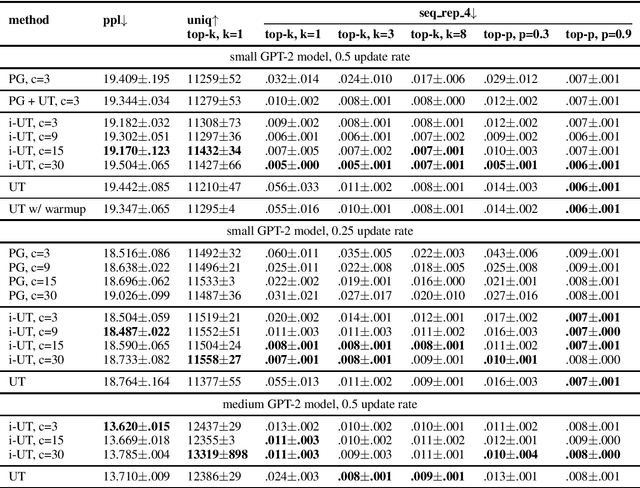
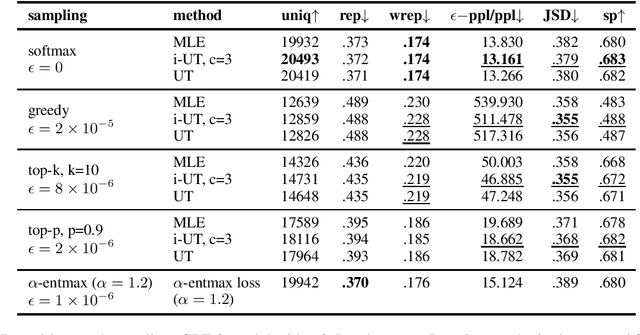

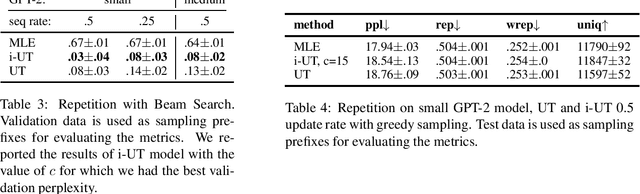
Likelihood training and maximization-based decoding result in dull and repetitive generated texts even when using powerful language models (Holtzman et al., 2019). Adding a loss function for regularization was shown to improve text generation output by helping avoid unwanted properties, such as contradiction or repetition (Li at al., 2020). In this work, we propose fine-tuning a language model by using policy gradient reinforcement learning, directly optimizing for better generation. We apply this approach to minimizing repetition in generated text, and show that, when combined with unlikelihood training (Welleck et al., 2020), our method further reduces repetition without impacting the language model quality. We also evaluate other methods for improving generation at training and decoding time, and compare them using various metrics aimed at control for better text generation output.