Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive Model for Headline Generation
Paper and Code
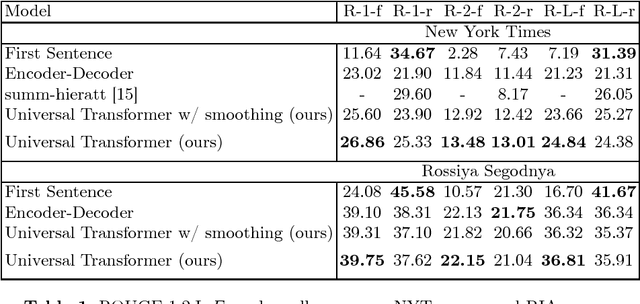


Headline generation is a special type of text summarization task. While the amount of available training data for this task is almost unlimited, it still remains challenging, as learning to generate headlines for news articles implies that the model has strong reasoning about natural language. To overcome this issue, we applied recent Universal Transformer architecture paired with byte-pair encoding technique and achieved new state-of-the-art results on the New York Times Annotated corpus with ROUGE-L F1-score 24.84 and ROUGE-2 F1-score 13.48. We also present the new RIA corpus and reach ROUGE-L F1-score 36.81 and ROUGE-2 F1-score 22.15 on it.
* accepted for ECIR 2019
View paper on