 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Pedestrians Pay Attention? Eye Contact Detection in the Wild
Paper and Code

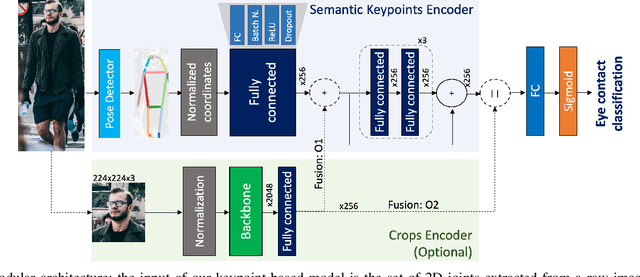

In urban or crowded environments, humans rely on eye contact for fast and efficient communication with nearby people. Autonomous agents also need to detect eye contact to interact with pedestrians and safely navigate around them. In this paper, we focus on eye contact detection in the wild, i.e., real-world scenarios for autonomous vehicles with no control over the environment or the distance of pedestrians. We introduce a model that leverages semantic keypoints to detect eye contact and show that this high-level representation (i) achieves state-of-the-art results on the publicly-available dataset JAAD, and (ii) conveys better generalization properties than leveraging raw images in an end-to-end network. To study domain adaptation, we create LOOK: a large-scale dataset for eye contact detection in the wild, which focuses on diverse and unconstrained scenarios for real-world generalization. The source code and the LOOK dataset are publicly shared towards an open science mission.