 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Mar 26, 2025
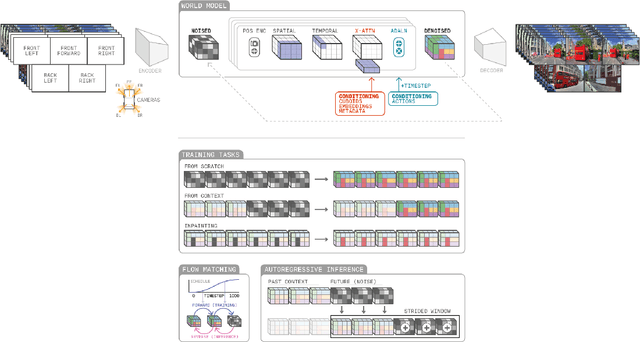


Generative models offer a scalable and flexible paradigm for simulating complex environments, yet current approaches fall short in addressing the domain-specific requirements of autonomous driving - such as multi-agent interactions, fine-grained control, and multi-camera consistency. We introduce GAIA-2, Generative AI for Autonomy, a latent diffusion world model that unifies these capabilities within a single generative framework. GAIA-2 supports controllable video generation conditioned on a rich set of structured inputs: ego-vehicle dynamics, agent configurations, environmental factors, and road semantics. It generates high-resolution, spatiotemporally consistent multi-camera videos across geographically diverse driving environments (UK, US, Germany). The model integrates both structured conditioning and external latent embeddings (e.g., from a proprietary driving model) to facilitate flexible and semantically grounded scene synthesis. Through this integration, GAIA-2 enables scalable simulation of both common and rare driving scenarios, advancing the use of generative world models as a core tool in the development of autonomous systems. Videos are available at https://wayve.ai/thinking/gaia-2.
Do Pedestrians Pay Attention? Eye Contact Detection in the Wild
Dec 08, 2021
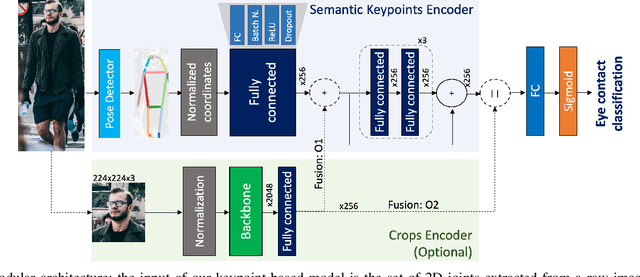
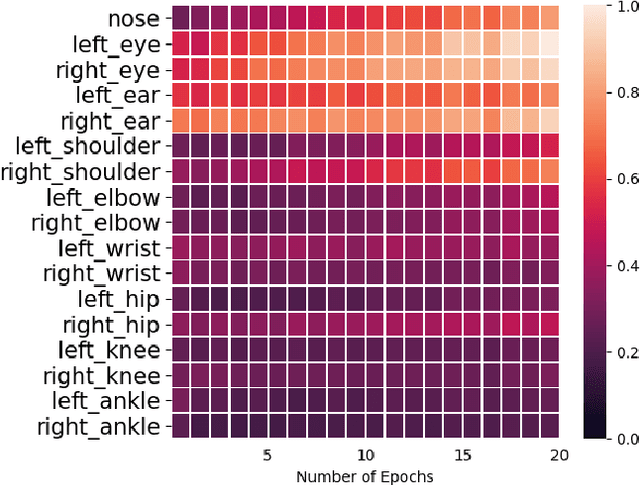

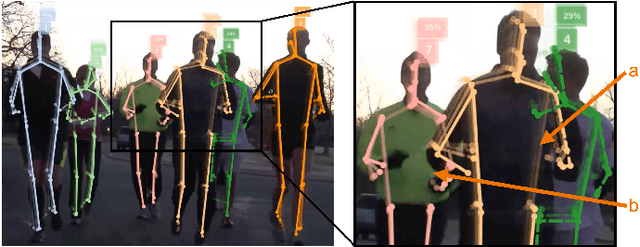
In urban or crowded environments, humans rely on eye contact for fast and efficient communication with nearby people. Autonomous agents also need to detect eye contact to interact with pedestrians and safely navigate around them. In this paper, we focus on eye contact detection in the wild, i.e., real-world scenarios for autonomous vehicles with no control over the environment or the distance of pedestrians. We introduce a model that leverages semantic keypoints to detect eye contact and show that this high-level representation (i) achieves state-of-the-art results on the publicly-available dataset JAAD, and (ii) conveys better generalization properties than leveraging raw images in an end-to-end network. To study domain adaptation, we create LOOK: a large-scale dataset for eye contact detection in the wild, which focuses on diverse and unconstrained scenarios for real-world generalization. The source code and the LOOK dataset are publicly shared towards an open science mission.
OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association
Mar 03, 2021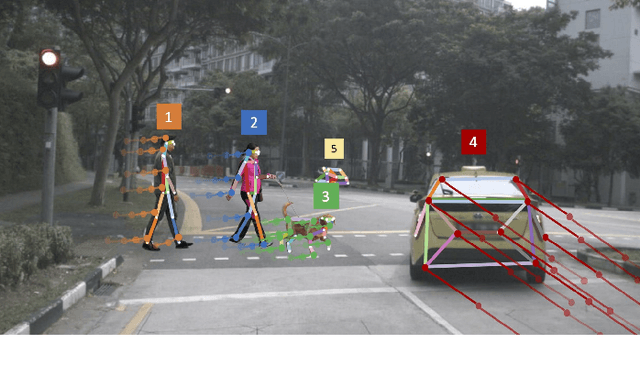


Many image-based perception tasks can be formulated as detecting, associating and tracking semantic keypoints, e.g., human body pose estimation and tracking. In this work, we present a general framework that jointly detects and forms spatio-temporal keypoint associations in a single stage, making this the first real-time pose detection and tracking algorithm. We present a generic neural network architecture that uses Composite Fields to detect and construct a spatio-temporal pose which is a single, connected graph whose nodes are the semantic keypoints (e.g., a person's body joints) in multiple frames. For the temporal associations, we introduce the Temporal Composite Association Field (TCAF) which requires an extended network architecture and training method beyond previous Composite Fields. Our experiments show competitive accuracy while being an order of magnitude faster on multiple publicly available datasets such as COCO, CrowdPose and the PoseTrack 2017 and 2018 datasets. We also show that our method generalizes to any class of semantic keypoints such as car and animal parts to provide a holistic perception framework that is well suited for urban mobility such as self-driving cars and delivery robots.
Perceiving Humans: from Monocular 3D Localization to Social Distancing
Sep 01, 2020
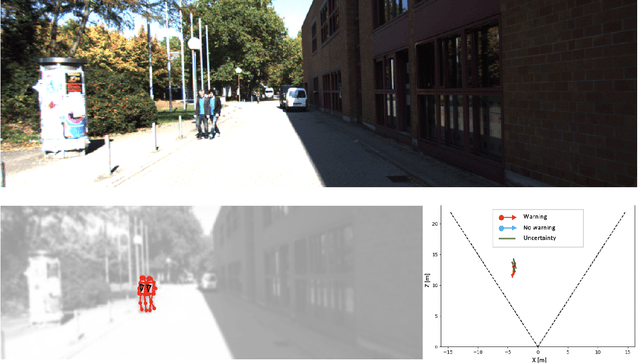
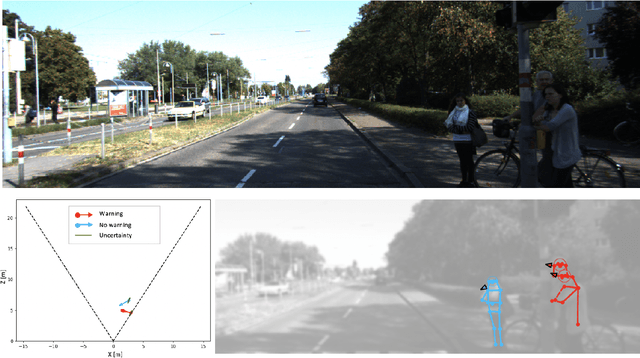
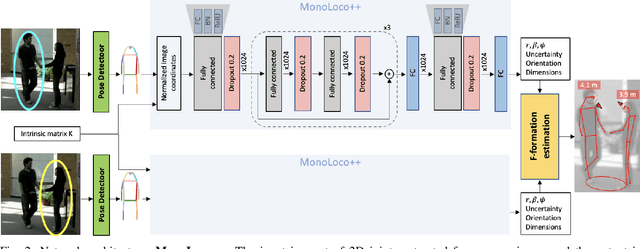
Perceiving humans in the context of Intelligent Transportation Systems (ITS) often relies on multiple cameras or expensive LiDAR sensors. In this work, we present a new cost-effective vision-based method that perceives humans' locations in 3D and their body orientation from a single image. We address the challenges related to the ill-posed monocular 3D tasks by proposing a deep learning method that predicts confidence intervals in contrast to point estimates. Our neural network architecture estimates humans 3D body locations and their orientation with a measure of uncertainty. Our vision-based system (i) is privacy-safe, (ii) works with any fixed or moving cameras, and (iii) does not rely on ground plane estimation. We demonstrate the performance of our method with respect to three applications: locating humans in 3D, detecting social interactions, and verifying the compliance of recent safety measures due to the COVID-19 outbreak. Indeed, we show that we can rethink the concept of "social distancing" as a form of social interaction in contrast to a simple location-based rule. We publicly share the source code towards an open science mission.
MonStereo: When Monocular and Stereo Meet at the Tail of 3D Human Localization
Aug 25, 2020


Monocular and stereo vision are cost-effective solutions for 3D human localization in the context of self-driving cars or social robots. However, they are usually developed independently and have their respective strengths and limitations. We propose a novel unified learning framework that leverages the strengths of both monocular and stereo cues for 3D human localization. Our method jointly (i) associates humans in left-right images, (ii) deals with occluded and distant cases in stereo settings by relying on the robustness of monocular cues, and (iii) tackles the intrinsic ambiguity of monocular perspective projection by exploiting prior knowledge of human height distribution. We achieve state-of-the-art quantitative results for the 3D localization task on KITTI dataset and estimate confidence intervals that account for challenging instances. We show qualitative examples for the long tail challenges such as occluded, far-away, and children instances.
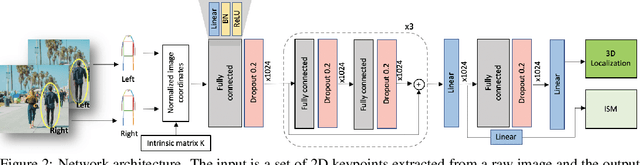
MonoLoco: Monocular 3D Pedestrian Localization and Uncertainty Estimation
Jun 14, 2019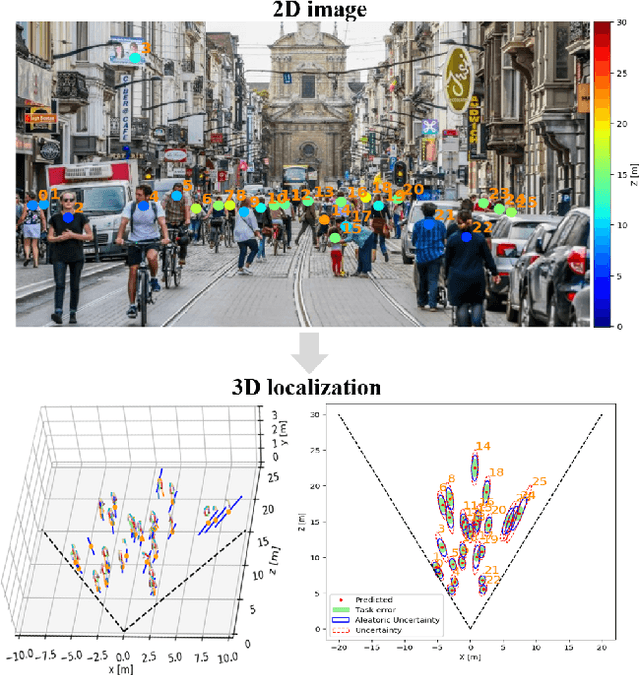
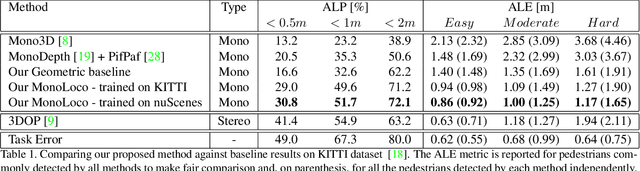
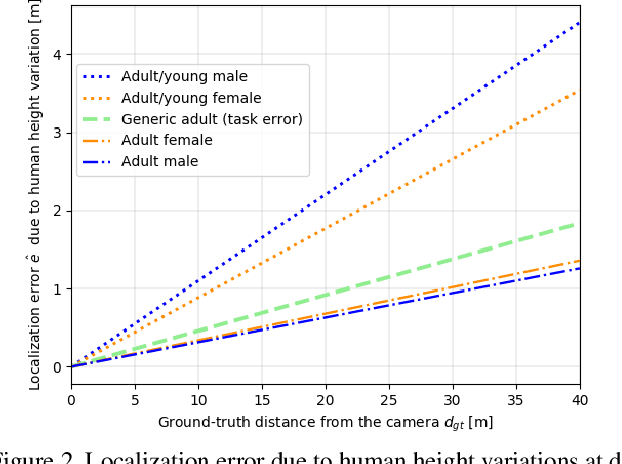

We tackle the fundamentally ill-posed problem of 3D human localization from monocular RGB images. Driven by the limitation of neural networks outputting point estimates, we address the ambiguity in the task with a new neural network predicting confidence intervals through a loss function based on the Laplace distribution. Our architecture is a light-weight feed-forward neural network which predicts the 3D coordinates given 2D human pose. The design is particularly well suited for small training data and cross-dataset generalization. Our experiments show that (i) we outperform state-of-the art results on KITTI and nuScenes datasets, (ii) even outperform stereo for far-away pedestrians, and (iii) estimate meaningful confidence intervals. We further share insights on our model of uncertainty in case of limited observation and out-of-distribution samples.
PifPaf: Composite Fields for Human Pose Estimation
Apr 05, 2019

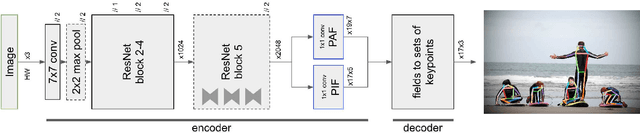
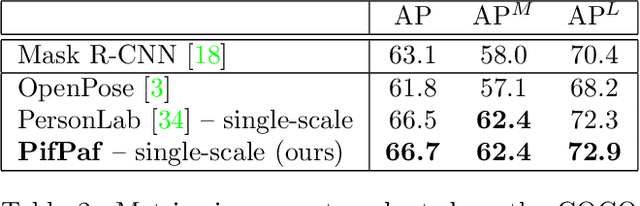
We propose a new bottom-up method for multi-person 2D human pose estimation that is particularly well suited for urban mobility such as self-driving cars and delivery robots. The new method, PifPaf, uses a Part Intensity Field (PIF) to localize body parts and a Part Association Field (PAF) to associate body parts with each other to form full human poses. Our method outperforms previous methods at low resolution and in crowded, cluttered and occluded scenes thanks to (i) our new composite field PAF encoding fine-grained information and (ii) the choice of Laplace loss for regressions which incorporates a notion of uncertainty. Our architecture is based on a fully convolutional, single-shot, box-free design. We perform on par with the existing state-of-the-art bottom-up method on the standard COCO keypoint task and produce state-of-the-art results on a modified COCO keypoint task for the transportation domain.