 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeypoint Communities
Oct 03, 2021
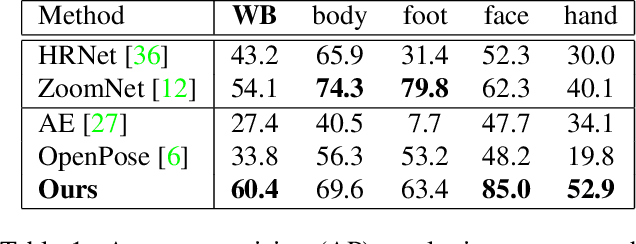
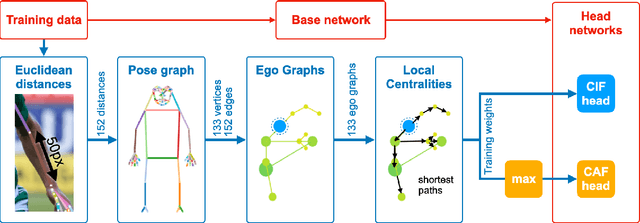
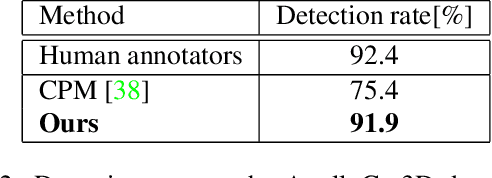
We present a fast bottom-up method that jointly detects over 100 keypoints on humans or objects, also referred to as human/object pose estimation. We model all keypoints belonging to a human or an object -- the pose -- as a graph and leverage insights from community detection to quantify the independence of keypoints. We use a graph centrality measure to assign training weights to different parts of a pose. Our proposed measure quantifies how tightly a keypoint is connected to its neighborhood. Our experiments show that our method outperforms all previous methods for human pose estimation with fine-grained keypoint annotations on the face, the hands and the feet with a total of 133 keypoints. We also show that our method generalizes to car poses.
Deep Social Force
Sep 24, 2021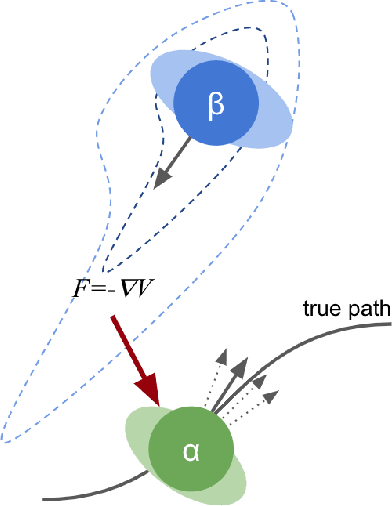
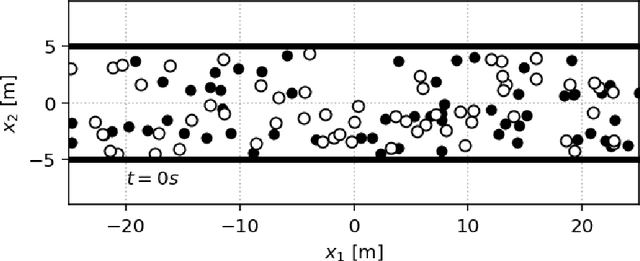
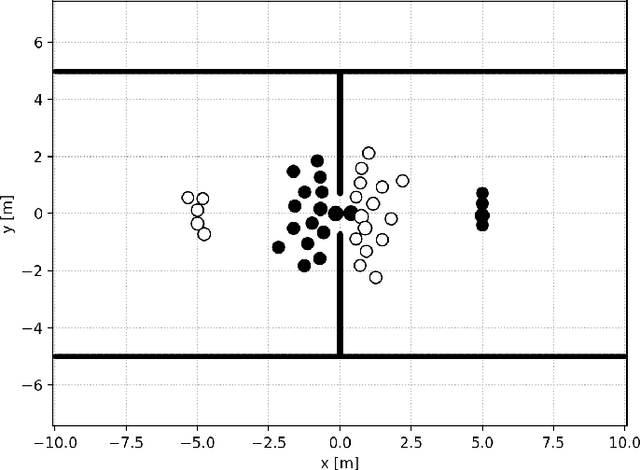
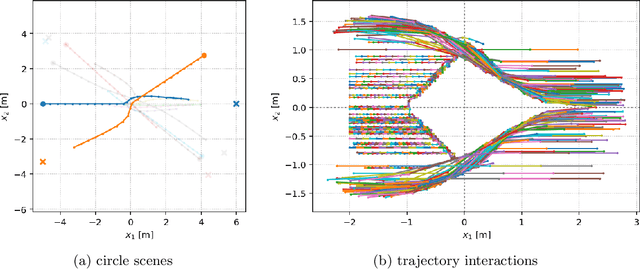
The Social Force model introduced by Helbing and Molnar in 1995 is a cornerstone of pedestrian simulation. This paper introduces a differentiable simulation of the Social Force model where the assumptions on the shapes of interaction potentials are relaxed with the use of universal function approximators in the form of neural networks. Classical force-based pedestrian simulations suffer from unnatural locking behavior on head-on collision paths. In addition, they cannot model the bias of pedestrians to avoid each other on the right or left depending on the geographic region. My experiments with more general interaction potentials show that potentials with a sharp tip in the front avoid locking. In addition, asymmetric interaction potentials lead to a left or right bias when pedestrians avoid each other.
OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association
Mar 03, 2021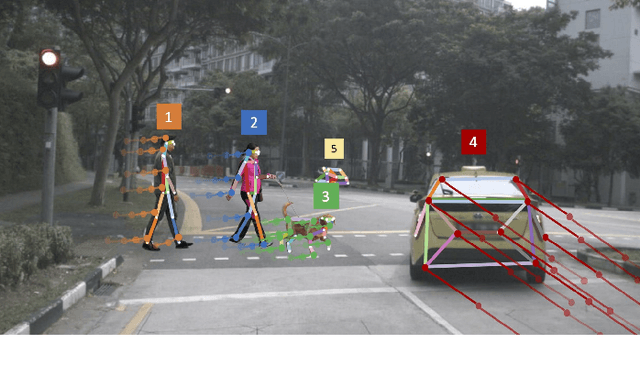


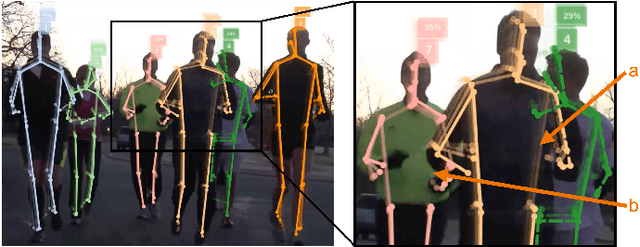
Many image-based perception tasks can be formulated as detecting, associating and tracking semantic keypoints, e.g., human body pose estimation and tracking. In this work, we present a general framework that jointly detects and forms spatio-temporal keypoint associations in a single stage, making this the first real-time pose detection and tracking algorithm. We present a generic neural network architecture that uses Composite Fields to detect and construct a spatio-temporal pose which is a single, connected graph whose nodes are the semantic keypoints (e.g., a person's body joints) in multiple frames. For the temporal associations, we introduce the Temporal Composite Association Field (TCAF) which requires an extended network architecture and training method beyond previous Composite Fields. Our experiments show competitive accuracy while being an order of magnitude faster on multiple publicly available datasets such as COCO, CrowdPose and the PoseTrack 2017 and 2018 datasets. We also show that our method generalizes to any class of semantic keypoints such as car and animal parts to provide a holistic perception framework that is well suited for urban mobility such as self-driving cars and delivery robots.
Perceiving Traffic from Aerial Images
Sep 16, 2020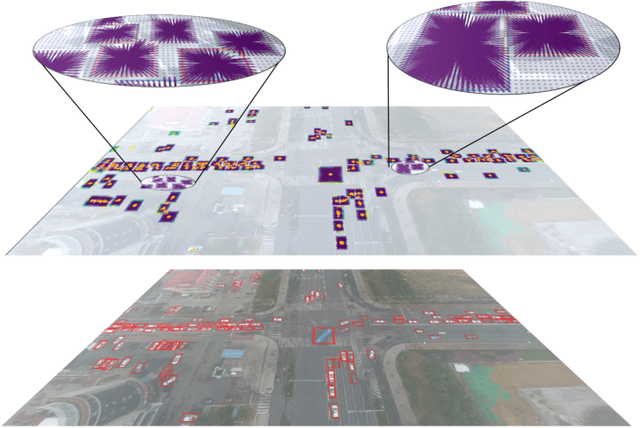
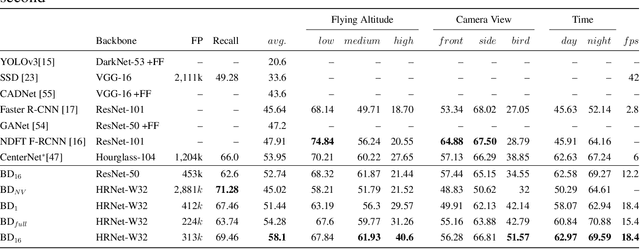

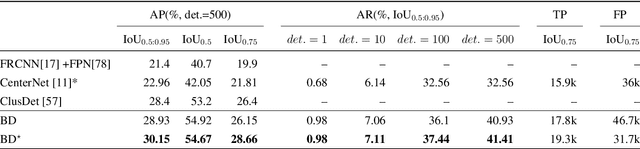
Drones or UAVs, equipped with different sensors, have been deployed in many places especially for urban traffic monitoring or last-mile delivery. It provides the ability to control the different aspects of traffic given real-time obeservations, an important pillar for the future of transportation and smart cities. With the increasing use of such machines, many previous state-of-the-art object detectors, who have achieved high performance on front facing cameras, are being used on UAV datasets. When applied to high-resolution aerial images captured from such datasets, they fail to generalize to the wide range of objects' scales. In order to address this limitation, we propose an object detection method called Butterfly Detector that is tailored to detect objects in aerial images. We extend the concept of fields and introduce butterfly fields, a type of composite field that describes the spatial information of output features as well as the scale of the detected object. To overcome occlusion and viewing angle variations that can hinder the localization process, we employ a voting mechanism between related butterfly vectors pointing to the object center. We evaluate our Butterfly Detector on two publicly available UAV datasets (UAVDT and VisDrone2019) and show that it outperforms previous state-of-the-art methods while remaining real-time.
Perceiving Humans: from Monocular 3D Localization to Social Distancing
Sep 01, 2020
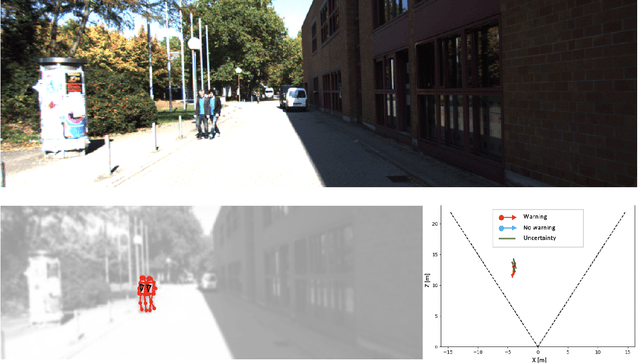
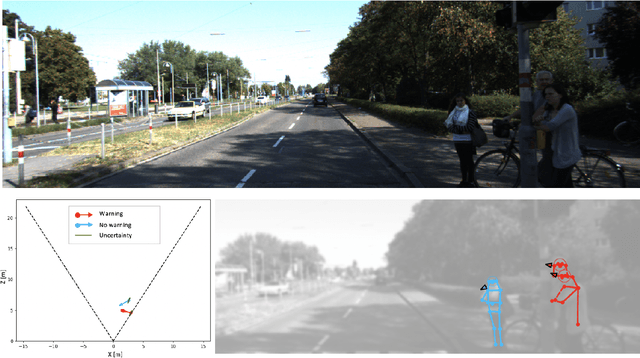
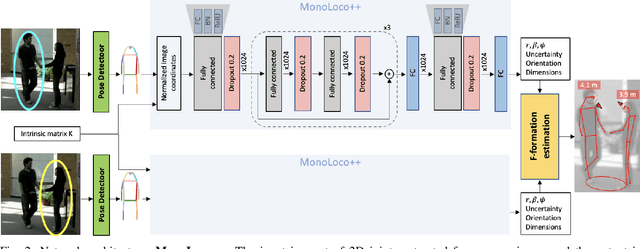
Perceiving humans in the context of Intelligent Transportation Systems (ITS) often relies on multiple cameras or expensive LiDAR sensors. In this work, we present a new cost-effective vision-based method that perceives humans' locations in 3D and their body orientation from a single image. We address the challenges related to the ill-posed monocular 3D tasks by proposing a deep learning method that predicts confidence intervals in contrast to point estimates. Our neural network architecture estimates humans 3D body locations and their orientation with a measure of uncertainty. Our vision-based system (i) is privacy-safe, (ii) works with any fixed or moving cameras, and (iii) does not rely on ground plane estimation. We demonstrate the performance of our method with respect to three applications: locating humans in 3D, detecting social interactions, and verifying the compliance of recent safety measures due to the COVID-19 outbreak. Indeed, we show that we can rethink the concept of "social distancing" as a form of social interaction in contrast to a simple location-based rule. We publicly share the source code towards an open science mission.
MonStereo: When Monocular and Stereo Meet at the Tail of 3D Human Localization
Aug 25, 2020

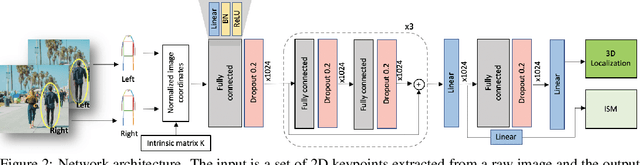

Monocular and stereo vision are cost-effective solutions for 3D human localization in the context of self-driving cars or social robots. However, they are usually developed independently and have their respective strengths and limitations. We propose a novel unified learning framework that leverages the strengths of both monocular and stereo cues for 3D human localization. Our method jointly (i) associates humans in left-right images, (ii) deals with occluded and distant cases in stereo settings by relying on the robustness of monocular cues, and (iii) tackles the intrinsic ambiguity of monocular perspective projection by exploiting prior knowledge of human height distribution. We achieve state-of-the-art quantitative results for the 3D localization task on KITTI dataset and estimate confidence intervals that account for challenging instances. We show qualitative examples for the long tail challenges such as occluded, far-away, and children instances.
Human Trajectory Forecasting in Crowds: A Deep Learning Perspective
Jul 07, 2020
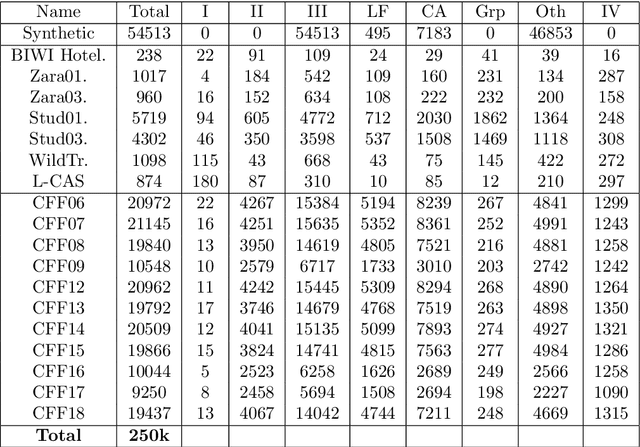
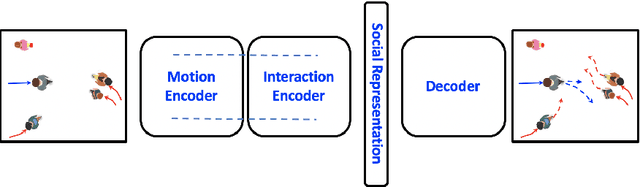
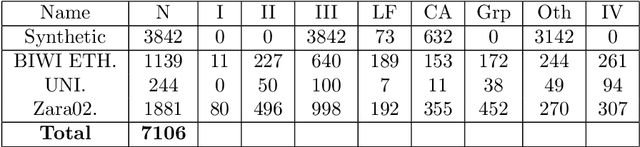
Since the past few decades, human trajectory forecasting has been a field of active research owing to its numerous real-world applications: evacuation situation analysis, traffic operations, deployment of social robots in crowded environments, to name a few. In this work, we cast the problem of human trajectory forecasting as learning a representation of human social interactions. Early works handcrafted this representation based on domain knowledge. However, social interactions in crowded environments are not only diverse but often subtle. Recently, deep learning methods have outperformed their handcrafted counterparts, as they learned about human-human interactions in a more generic data-driven fashion. In this work, we present an in-depth analysis of existing deep learning based methods for modelling social interactions. Based on our analysis, we propose a simple yet powerful method for effectively capturing these social interactions. To objectively compare the performance of these interaction-based forecasting models, we develop a large scale interaction-centric benchmark TrajNet++, a significant yet missing component in the field of human trajectory forecasting. We propose novel performance metrics that evaluate the ability of a model to output socially acceptable trajectories. Experiments on TrajNet++ validate the need for our proposed metrics, and our method outperforms competitive baselines on both real-world and synthetic datasets.
MonoLoco: Monocular 3D Pedestrian Localization and Uncertainty Estimation
Jun 14, 2019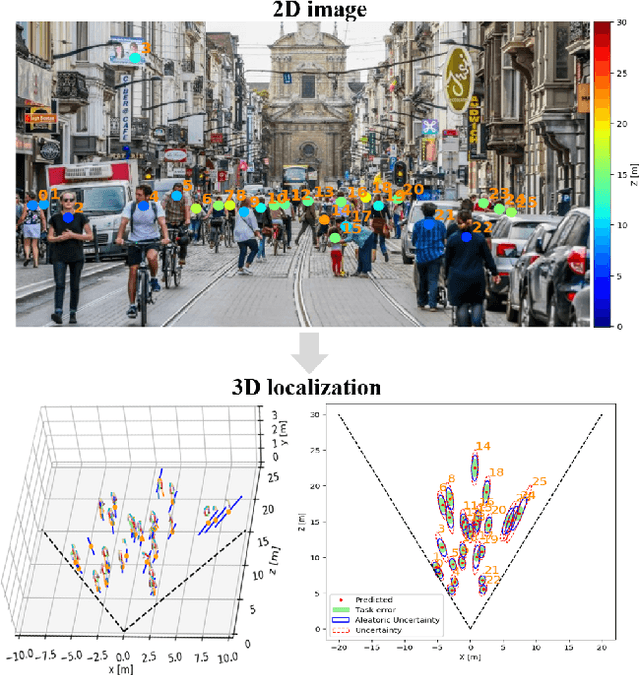
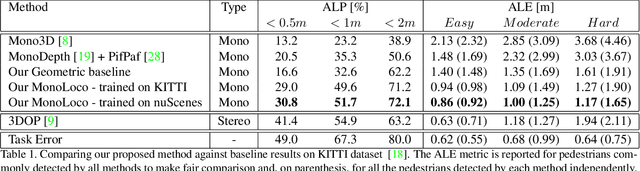
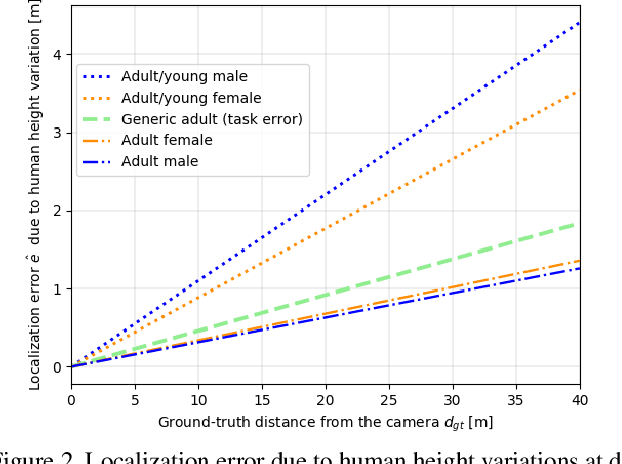

We tackle the fundamentally ill-posed problem of 3D human localization from monocular RGB images. Driven by the limitation of neural networks outputting point estimates, we address the ambiguity in the task with a new neural network predicting confidence intervals through a loss function based on the Laplace distribution. Our architecture is a light-weight feed-forward neural network which predicts the 3D coordinates given 2D human pose. The design is particularly well suited for small training data and cross-dataset generalization. Our experiments show that (i) we outperform state-of-the art results on KITTI and nuScenes datasets, (ii) even outperform stereo for far-away pedestrians, and (iii) estimate meaningful confidence intervals. We further share insights on our model of uncertainty in case of limited observation and out-of-distribution samples.
Rethinking Person Re-Identification with Confidence
Jun 11, 2019
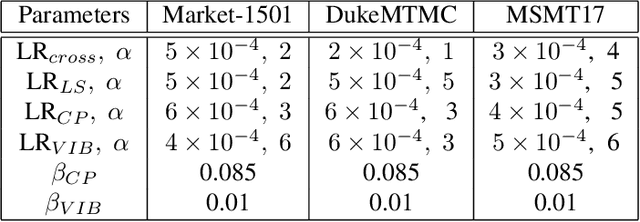

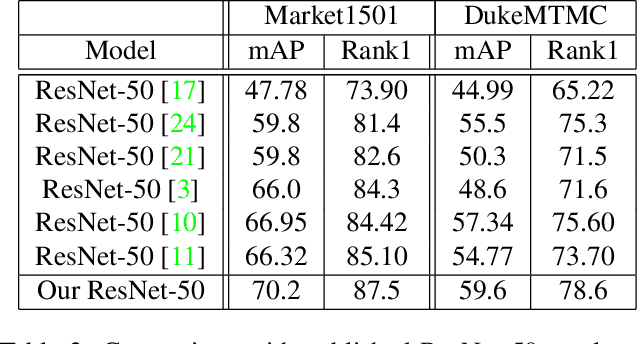
A common challenge in person re-identification systems is to differentiate people with very similar appearances. The current learning frameworks based on cross-entropy minimization are not suited for this challenge. To tackle this issue, we propose to modify the cross-entropy loss and model confidence in the representation learning framework using three methods: label smoothing, confidence penalty, and deep variational information bottleneck. A key property of our approach is the fact that we do not make use of any hand-crafted human characteristics but rather focus our attention on the learning supervision. Although methods modeling confidence did not show significant improvements on other computer vision tasks such as object classification, we are able to show their notable effect on the task of re-identifying people outperforming state-of-the-art methods on 3 publicly available datasets. Our analysis and experiments not only offer insights into the problems that person re-id suffers from, but also provide a simple and straightforward recipe to tackle this issue.
PifPaf: Composite Fields for Human Pose Estimation
Apr 05, 2019

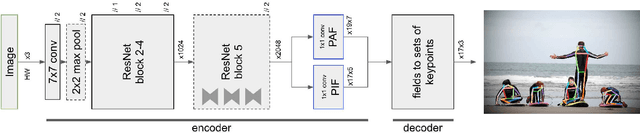
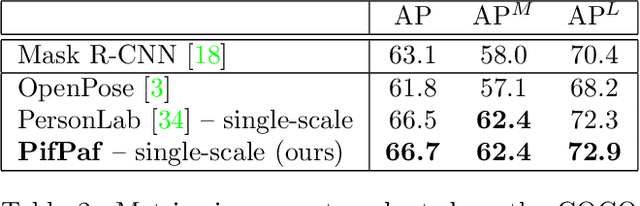
We propose a new bottom-up method for multi-person 2D human pose estimation that is particularly well suited for urban mobility such as self-driving cars and delivery robots. The new method, PifPaf, uses a Part Intensity Field (PIF) to localize body parts and a Part Association Field (PAF) to associate body parts with each other to form full human poses. Our method outperforms previous methods at low resolution and in crowded, cluttered and occluded scenes thanks to (i) our new composite field PAF encoding fine-grained information and (ii) the choice of Laplace loss for regressions which incorporates a notion of uncertainty. Our architecture is based on a fully convolutional, single-shot, box-free design. We perform on par with the existing state-of-the-art bottom-up method on the standard COCO keypoint task and produce state-of-the-art results on a modified COCO keypoint task for the transportation domain.