 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Person Re-Identification with Confidence
Paper and Code

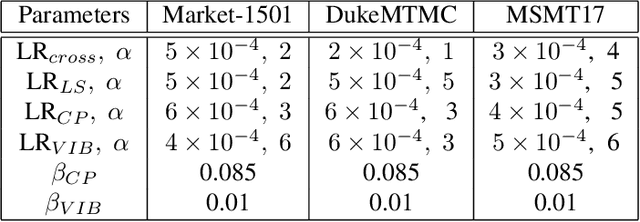

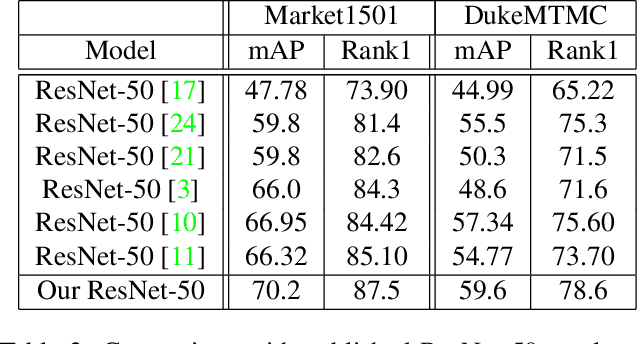
A common challenge in person re-identification systems is to differentiate people with very similar appearances. The current learning frameworks based on cross-entropy minimization are not suited for this challenge. To tackle this issue, we propose to modify the cross-entropy loss and model confidence in the representation learning framework using three methods: label smoothing, confidence penalty, and deep variational information bottleneck. A key property of our approach is the fact that we do not make use of any hand-crafted human characteristics but rather focus our attention on the learning supervision. Although methods modeling confidence did not show significant improvements on other computer vision tasks such as object classification, we are able to show their notable effect on the task of re-identifying people outperforming state-of-the-art methods on 3 publicly available datasets. Our analysis and experiments not only offer insights into the problems that person re-id suffers from, but also provide a simple and straightforward recipe to tackle this issue.