 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Inexact Gradients to Byzantine Robustness: Acceleration and Optimization under Similarity
Feb 03, 2026Standard federated learning algorithms are vulnerable to adversarial nodes, a.k.a. Byzantine failures. To solve this issue, robust distributed learning algorithms have been developed, which typically replace parameter averaging by robust aggregations. While generic conditions on these aggregations exist to guarantee the convergence of (Stochastic) Gradient Descent (SGD), the analyses remain rather ad-hoc. This hinders the development of more complex robust algorithms, such as accelerated ones. In this work, we show that Byzantine-robust distributed optimization can, under standard generic assumptions, be cast as a general optimization with inexact gradient oracles (with both additive and multiplicative error terms), an active field of research. This allows for instance to directly show that GD on top of standard robust aggregation procedures obtains optimal asymptotic error in the Byzantine setting. Going further, we propose two optimization schemes to speed up the convergence. The first one is a Nesterov-type accelerated scheme whose proof directly derives from accelerated inexact gradient results applied to our formulation. The second one hinges on Optimization under Similarity, in which the server leverages an auxiliary loss function that approximates the global loss. Both approaches allow to drastically reduce the communication complexity compared to previous methods, as we show theoretically and empirically.
Tight Analysis of Decentralized SGD: A Markov Chain Perspective
Jan 11, 2026We propose a novel analysis of the Decentralized Stochastic Gradient Descent (DSGD) algorithm with constant step size, interpreting the iterates of the algorithm as a Markov chain. We show that DSGD converges to a stationary distribution, with its bias, to first order, decomposable into two components: one due to decentralization (growing with the graph's spectral gap and clients' heterogeneity) and one due to stochasticity. Remarkably, the variance of local parameters is, at the first-order, inversely proportional to the number of clients, regardless of the network topology and even when clients' iterates are not averaged at the end. As a consequence of our analysis, we obtain non-asymptotic convergence bounds for clients' local iterates, confirming that DSGD has linear speed-up in the number of clients, and that the network topology only impacts higher-order terms.
Federated Majorize-Minimization: Beyond Parameter Aggregation
Jul 23, 2025


This paper proposes a unified approach for designing stochastic optimization algorithms that robustly scale to the federated learning setting. Our work studies a class of Majorize-Minimization (MM) problems, which possesses a linearly parameterized family of majorizing surrogate functions. This framework encompasses (proximal) gradient-based algorithms for (regularized) smooth objectives, the Expectation Maximization algorithm, and many problems seen as variational surrogate MM. We show that our framework motivates a unifying algorithm called Stochastic Approximation Stochastic Surrogate MM (\SSMM), which includes previous stochastic MM procedures as special instances. We then extend \SSMM\ to the federated setting, while taking into consideration common bottlenecks such as data heterogeneity, partial participation, and communication constraints; this yields \QSMM. The originality of \QSMM\ is to learn locally and then aggregate information characterizing the \textit{surrogate majorizing function}, contrary to classical algorithms which learn and aggregate the \textit{original parameter}. Finally, to showcase the flexibility of this methodology beyond our theoretical setting, we use it to design an algorithm for computing optimal transport maps in the federated setting.
Tight analyses of first-order methods with error feedback
Jun 05, 2025Communication between agents often constitutes a major computational bottleneck in distributed learning. One of the most common mitigation strategies is to compress the information exchanged, thereby reducing communication overhead. To counteract the degradation in convergence associated with compressed communication, error feedback schemes -- most notably $\mathrm{EF}$ and $\mathrm{EF}^{21}$ -- were introduced. In this work, we provide a tight analysis of both of these methods. Specifically, we find the Lyapunov function that yields the best possible convergence rate for each method -- with matching lower bounds. This principled approach yields sharp performance guarantees and enables a rigorous, apples-to-apples comparison between $\mathrm{EF}$, $\mathrm{EF}^{21}$, and compressed gradient descent. Our analysis is carried out in a simplified yet representative setting, which allows for clean theoretical insights and fair comparison of the underlying mechanisms.
Scaffold with Stochastic Gradients: New Analysis with Linear Speed-Up
Mar 10, 2025

This paper proposes a novel analysis for the Scaffold algorithm, a popular method for dealing with data heterogeneity in federated learning. While its convergence in deterministic settings--where local control variates mitigate client drift--is well established, the impact of stochastic gradient updates on its performance is less understood. To address this problem, we first show that its global parameters and control variates define a Markov chain that converges to a stationary distribution in the Wasserstein distance. Leveraging this result, we prove that Scaffold achieves linear speed-up in the number of clients up to higher-order terms in the step size. Nevertheless, our analysis reveals that Scaffold retains a higher-order bias, similar to FedAvg, that does not decrease as the number of clients increases. This highlights opportunities for developing improved stochastic federated learning algorithms
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Refined Analysis of Federated Averaging's Bias and Federated Richardson-Romberg Extrapolation
Dec 02, 2024

In this paper, we present a novel analysis of FedAvg with constant step size, relying on the Markov property of the underlying process. We demonstrate that the global iterates of the algorithm converge to a stationary distribution and analyze its resulting bias and variance relative to the problem's solution. We provide a first-order expansion of the bias in both homogeneous and heterogeneous settings. Interestingly, this bias decomposes into two distinct components: one that depends solely on stochastic gradient noise and another on client heterogeneity. Finally, we introduce a new algorithm based on the Richardson-Romberg extrapolation technique to mitigate this bias.
Achieving Optimal Breakdown for Byzantine Robust Gossip
Oct 14, 2024



Distributed approaches have many computational benefits, but they are vulnerable to attacks from a subset of devices transmitting incorrect information. This paper investigates Byzantine-resilient algorithms in a decentralized setting, where devices communicate directly with one another. We investigate the notion of breakdown point, and show an upper bound on the number of adversaries that decentralized algorithms can tolerate. We introduce $\mathrm{CG}^+$, an algorithm at the intersection of $\mathrm{ClippedGossip}$ and $\mathrm{NNA}$, two popular approaches for robust decentralized learning. $\mathrm{CG}^+$ meets our upper bound, and thus obtains optimal robustness guarantees, whereas neither of the existing two does. We provide experimental evidence for this gap by presenting an attack tailored to sparse graphs which breaks $\mathrm{NNA}$ but against which $\mathrm{CG}^+$ is robust.
Byzantine-Robust Gossip: Insights from a Dual Approach
May 06, 2024



Distributed approaches have many computational benefits, but they are vulnerable to attacks from a subset of devices transmitting incorrect information. This paper investigates Byzantine-resilient algorithms in a decentralized setting, where devices communicate directly with one another. We leverage the so-called dual approach to design a general robust decentralized optimization method. We provide both global and local clipping rules in the special case of average consensus, with tight convergence guarantees. These clipping rules are practical, and yield results that finely characterize the impact of Byzantine nodes, highlighting for instance a qualitative difference in convergence between global and local clipping thresholds. Lastly, we demonstrate that they can serve as a basis for designing efficient attacks.
Random features models: a way to study the success of naive imputation
Feb 06, 2024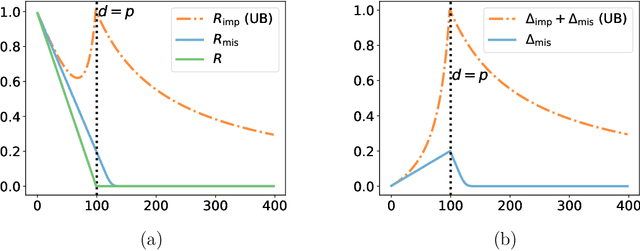

Constant (naive) imputation is still widely used in practice as this is a first easy-to-use technique to deal with missing data. Yet, this simple method could be expected to induce a large bias for prediction purposes, as the imputed input may strongly differ from the true underlying data. However, recent works suggest that this bias is low in the context of high-dimensional linear predictors when data is supposed to be missing completely at random (MCAR). This paper completes the picture for linear predictors by confirming the intuition that the bias is negligible and that surprisingly naive imputation also remains relevant in very low dimension.To this aim, we consider a unique underlying random features model, which offers a rigorous framework for studying predictive performances, whilst the dimension of the observed features varies.Building on these theoretical results, we establish finite-sample bounds on stochastic gradient (SGD) predictors applied to zero-imputed data, a strategy particularly well suited for large-scale learning.If the MCAR assumption appears to be strong, we show that similar favorable behaviors occur for more complex missing data scenarios.