 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic-time Schedules for Scaling Language Models with Momentum
Feb 05, 2026In practice, the hyperparameters $(β_1, β_2)$ and weight-decay $λ$ in AdamW are typically kept at fixed values. Is there any reason to do otherwise? We show that for large-scale language model training, the answer is yes: by exploiting the power-law structure of language data, one can design time-varying schedules for $(β_1, β_2, λ)$ that deliver substantial performance gains. We study logarithmic-time scheduling, in which the optimizer's gradient memory horizon grows with training time. Although naive variants of this are unstable, we show that suitable damping mechanisms restore stability while preserving the benefits of longer memory. Based on this, we present ADANA, an AdamW-like optimizer that couples log-time schedules with explicit damping to balance stability and performance. We empirically evaluate ADANA across transformer scalings (45M to 2.6B parameters), comparing against AdamW, Muon, and AdEMAMix. When properly tuned, ADANA achieves up to 40% compute efficiency relative to a tuned AdamW, with gains that persist--and even improve--as model scale increases. We further show that similar benefits arise when applying logarithmic-time scheduling to AdEMAMix, and that logarithmic-time weight-decay alone can yield significant improvements. Finally, we present variants of ADANA that mitigate potential failure modes and improve robustness.
Dimension-adapted Momentum Outscales SGD
May 22, 2025We investigate scaling laws for stochastic momentum algorithms with small batch on the power law random features model, parameterized by data complexity, target complexity, and model size. When trained with a stochastic momentum algorithm, our analysis reveals four distinct loss curve shapes determined by varying data-target complexities. While traditional stochastic gradient descent with momentum (SGD-M) yields identical scaling law exponents to SGD, dimension-adapted Nesterov acceleration (DANA) improves these exponents by scaling momentum hyperparameters based on model size and data complexity. This outscaling phenomenon, which also improves compute-optimal scaling behavior, is achieved by DANA across a broad range of data and target complexities, while traditional methods fall short. Extensive experiments on high-dimensional synthetic quadratics validate our theoretical predictions and large-scale text experiments with LSTMs show DANA's improved loss exponents over SGD hold in a practical setting.
Proving Linear Mode Connectivity of Neural Networks via Optimal Transport
Oct 29, 2023

The energy landscape of high-dimensional non-convex optimization problems is crucial to understanding the effectiveness of modern deep neural network architectures. Recent works have experimentally shown that two different solutions found after two runs of a stochastic training are often connected by very simple continuous paths (e.g., linear) modulo a permutation of the weights. In this paper, we provide a framework theoretically explaining this empirical observation. Based on convergence rates in Wasserstein distance of empirical measures, we show that, with high probability, two wide enough two-layer neural networks trained with stochastic gradient descent are linearly connected. Additionally, we express upper and lower bounds on the width of each layer of two deep neural networks with independent neuron weights to be linearly connected. Finally, we empirically demonstrate the validity of our approach by showing how the dimension of the support of the weight distribution of neurons, which dictates Wasserstein convergence rates is correlated with linear mode connectivity.
A General Framework For Proving The Equivariant Strong Lottery Ticket Hypothesis
Jun 09, 2022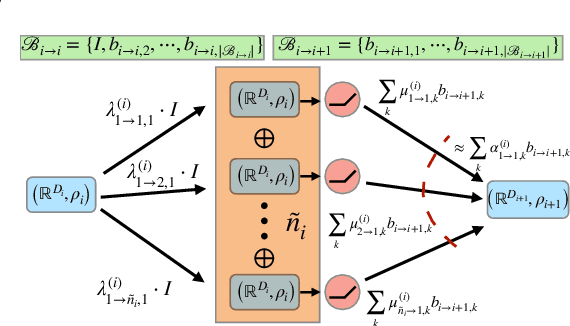


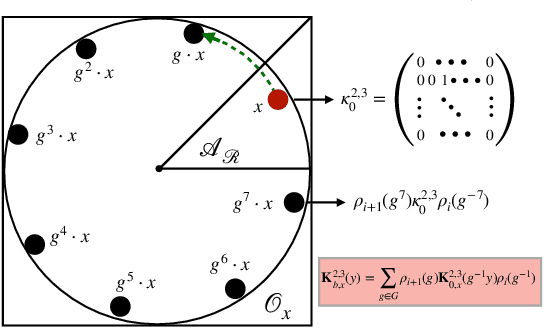
The Strong Lottery Ticket Hypothesis (SLTH) stipulates the existence of a subnetwork within a sufficiently overparameterized (dense) neural network that -- when initialized randomly and without any training -- achieves the accuracy of a fully trained target network. Recent work by \citet{da2022proving} demonstrates that the SLTH can also be extended to translation equivariant networks -- i.e. CNNs -- with the same level of overparametrization as needed for SLTs in dense networks. However, modern neural networks are capable of incorporating more than just translation symmetry, and developing general equivariant architectures such as rotation and permutation has been a powerful design principle. In this paper, we generalize the SLTH to functions that preserve the action of the group $G$ -- i.e. $G$-equivariant network -- and prove, with high probability, that one can prune a randomly initialized overparametrized $G$-equivariant network to a $G$-equivariant subnetwork that approximates another fully trained $G$-equivariant network of fixed width and depth. We further prove that our prescribed overparametrization scheme is also optimal as a function of the error tolerance. We develop our theory for a large range of groups, including important ones such as subgroups of the Euclidean group $\text{E}(n)$ and subgroups of the symmetric group $G \leq \mathcal{S}_n$ -- allowing us to find SLTs for MLPs, CNNs, $\text{E}(2)$-steerable CNNs, and permutation equivariant networks as specific instantiations of our unified framework which completely extends prior work. Empirically, we verify our theory by pruning overparametrized $\text{E}(2)$-steerable CNNs and message passing GNNs to match the performance of trained target networks within a given error tolerance.