 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Clustering with Missing Not At Random Data
Paper and Code
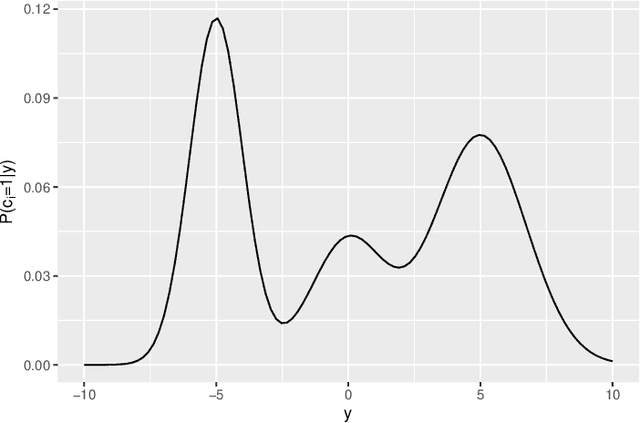

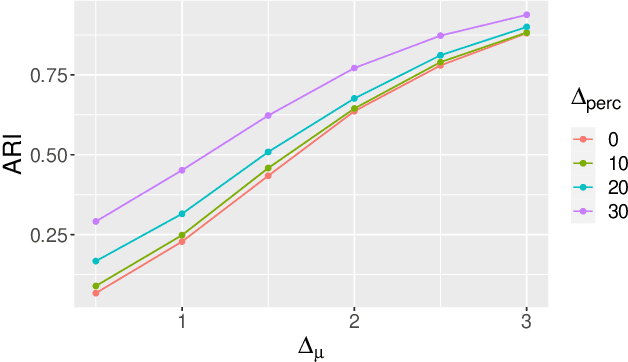
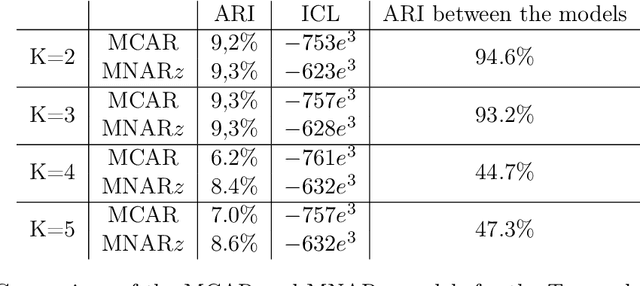
In recent decades, technological advances have made it possible to collect large data sets. In this context, the model-based clustering is a very popular, flexible and interpretable methodology for data exploration in a well-defined statistical framework. One of the ironies of the increase of large datasets is that missing values are more frequent. However, traditional ways (as discarding observations with missing values or imputation methods) are not designed for the clustering purpose. In addition, they rarely apply to the general case, though frequent in practice, of Missing Not At Random (MNAR) values, i.e. when the missingness depends on the unobserved data values and possibly on the observed data values. The goal of this paper is to propose a novel approach by embedding MNAR data directly within model-based clustering algorithms. We introduce a selection model for the joint distribution of data and missing-data indicator. It corresponds to a mixture model for the data distribution and a general MNAR model for the missing-data mechanism, which may depend on the underlying classes (unknown) and/or the values of the missing variables themselves. A large set of meaningful MNAR sub-models is derived and the identifiability of the parameters is studied for each of the sub-models, which is usually a key issue for any MNAR proposals. The EM and Stochastic EM algorithms are considered for estimation. Finally, we perform empirical evaluations for the proposed submodels on synthetic data and we illustrate the relevance of our method on a medical register, the TraumaBase (R) dataset.