 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational excess risk bound for general state space models
Dec 15, 2023In this paper, we consider variational autoencoders (VAE) for general state space models. We consider a backward factorization of the variational distributions to analyze the excess risk associated with VAE. Such backward factorizations were recently proposed to perform online variational learning and to obtain upper bounds on the variational estimation error. When independent trajectories of sequences are observed and under strong mixing assumptions on the state space model and on the variational distribution, we provide an oracle inequality explicit in the number of samples and in the length of the observation sequences. We then derive consequences of this theoretical result. In particular, when the data distribution is given by a state space model, we provide an upper bound for the Kullback-Leibler divergence between the data distribution and its estimator and between the variational posterior and the estimated state space posterior distributions.Under classical assumptions, we prove that our results can be applied to Gaussian backward kernels built with dense and recurrent neural networks.
Amortized backward variational inference in nonlinear state-space models
Jun 01, 2022

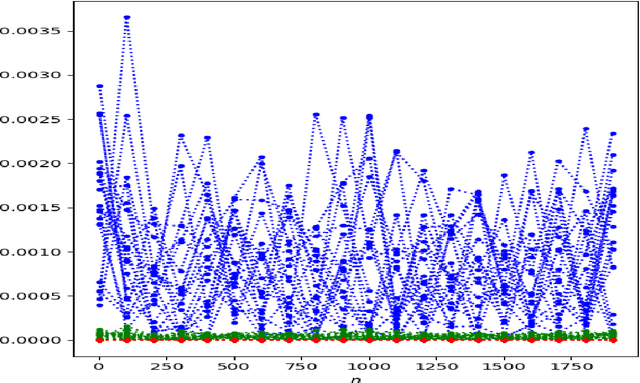
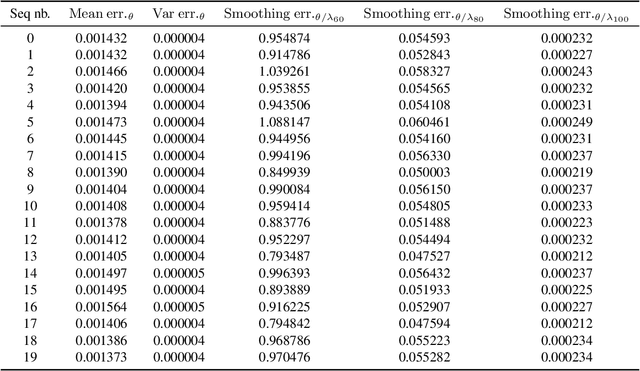
We consider the problem of state estimation in general state-space models using variational inference. For a generic variational family defined using the same backward decomposition as the actual joint smoothing distribution, we establish for the first time that, under mixing assumptions, the variational approximation of expectations of additive state functionals induces an error which grows at most linearly in the number of observations. This guarantee is consistent with the known upper bounds for the approximation of smoothing distributions using standard Monte Carlo methods. Moreover, we propose an amortized inference framework where a neural network shared over all times steps outputs the parameters of the variational kernels. We also study empirically parametrizations which allow analytical marginalization of the variational distributions, and therefore lead to efficient smoothing algorithms. Significant improvements are made over state-of-the art variational solutions, especially when the generative model depends on a strongly nonlinear and noninjective mixing function.