 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecreasing Entropic Regularization Averaged Gradient for Semi-Discrete Optimal Transport
Oct 31, 2025Adding entropic regularization to Optimal Transport (OT) problems has become a standard approach for designing efficient and scalable solvers. However, regularization introduces a bias from the true solution. To mitigate this bias while still benefiting from the acceleration provided by regularization, a natural solver would adaptively decrease the regularization as it approaches the solution. Although some algorithms heuristically implement this idea, their theoretical guarantees and the extent of their acceleration compared to using a fixed regularization remain largely open. In the setting of semi-discrete OT, where the source measure is continuous and the target is discrete, we prove that decreasing the regularization can indeed accelerate convergence. To this end, we introduce DRAG: Decreasing (entropic) Regularization Averaged Gradient, a stochastic gradient descent algorithm where the regularization decreases with the number of optimization steps. We provide a theoretical analysis showing that DRAG benefits from decreasing regularization compared to a fixed scheme, achieving an unbiased $\mathcal{O}(1/t)$ sample and iteration complexity for both the OT cost and the potential estimation, and a $\mathcal{O}(1/\sqrt{t})$ rate for the OT map. Our theoretical findings are supported by numerical experiments that validate the effectiveness of DRAG and highlight its practical advantages.
Theoretical Convergence Guarantees for Variational Autoencoders
Oct 22, 2024



Variational Autoencoders (VAE) are popular generative models used to sample from complex data distributions. Despite their empirical success in various machine learning tasks, significant gaps remain in understanding their theoretical properties, particularly regarding convergence guarantees. This paper aims to bridge that gap by providing non-asymptotic convergence guarantees for VAE trained using both Stochastic Gradient Descent and Adam algorithms.We derive a convergence rate of $\mathcal{O}(\log n / \sqrt{n})$, where $n$ is the number of iterations of the optimization algorithm, with explicit dependencies on the batch size, the number of variational samples, and other key hyperparameters. Our theoretical analysis applies to both Linear VAE and Deep Gaussian VAE, as well as several VAE variants, including $\beta$-VAE and IWAE. Additionally, we empirically illustrate the impact of hyperparameters on convergence, offering new insights into the theoretical understanding of VAE training.
Semi-Discrete Optimal Transport: Nearly Minimax Estimation With Stochastic Gradient Descent and Adaptive Entropic Regularization
May 23, 2024



Optimal Transport (OT) based distances are powerful tools for machine learning to compare probability measures and manipulate them using OT maps. In this field, a setting of interest is semi-discrete OT, where the source measure $\mu$ is continuous, while the target $\nu$ is discrete. Recent works have shown that the minimax rate for the OT map is $\mathcal{O}(t^{-1/2})$ when using $t$ i.i.d. subsamples from each measure (two-sample setting). An open question is whether a better convergence rate can be achieved when the full information of the discrete measure $\nu$ is known (one-sample setting). In this work, we answer positively to this question by (i) proving an $\mathcal{O}(t^{-1})$ lower bound rate for the OT map, using the similarity between Laguerre cells estimation and density support estimation, and (ii) proposing a Stochastic Gradient Descent (SGD) algorithm with adaptive entropic regularization and averaging acceleration. To nearly achieve the desired fast rate, characteristic of non-regular parametric problems, we design an entropic regularization scheme decreasing with the number of samples. Another key step in our algorithm consists of using a projection step that permits to leverage the local strong convexity of the regularized OT problem. Our convergence analysis integrates online convex optimization and stochastic gradient techniques, complemented by the specificities of the OT semi-dual. Moreover, while being as computationally and memory efficient as vanilla SGD, our algorithm achieves the unusual fast rates of our theory in numerical experiments.
A Full Adagrad algorithm with O operations
May 03, 2024A novel approach is given to overcome the computational challenges of the full-matrix Adaptive Gradient algorithm (Full AdaGrad) in stochastic optimization. By developing a recursive method that estimates the inverse of the square root of the covariance of the gradient, alongside a streaming variant for parameter updates, the study offers efficient and practical algorithms for large-scale applications. This innovative strategy significantly reduces the complexity and resource demands typically associated with full-matrix methods, enabling more effective optimization processes. Moreover, the convergence rates of the proposed estimators and their asymptotic efficiency are given. Their effectiveness is demonstrated through numerical studies.
Online and Offline Robust Multivariate Linear Regression
Apr 30, 2024



We consider the robust estimation of the parameters of multivariate Gaussian linear regression models. To this aim we consider robust version of the usual (Mahalanobis) least-square criterion, with or without Ridge regularization. We introduce two methods each considered contrast: (i) online stochastic gradient descent algorithms and their averaged versions and (ii) offline fix-point algorithms. Under weak assumptions, we prove the asymptotic normality of the resulting estimates. Because the variance matrix of the noise is usually unknown, we propose to plug a robust estimate of it in the Mahalanobis-based stochastic gradient descent algorithms. We show, on synthetic data, the dramatic gain in terms of robustness of the proposed estimates as compared to the classical least-square ones. Well also show the computational efficiency of the online versions of the proposed algorithms. All the proposed algorithms are implemented in the R package RobRegression available on CRAN.
Non-asymptotic Analysis of Biased Adaptive Stochastic Approximation
Feb 05, 2024



Stochastic Gradient Descent (SGD) with adaptive steps is now widely used for training deep neural networks. Most theoretical results assume access to unbiased gradient estimators, which is not the case in several recent deep learning and reinforcement learning applications that use Monte Carlo methods. This paper provides a comprehensive non-asymptotic analysis of SGD with biased gradients and adaptive steps for convex and non-convex smooth functions. Our study incorporates time-dependent bias and emphasizes the importance of controlling the bias and Mean Squared Error (MSE) of the gradient estimator. In particular, we establish that Adagrad and RMSProp with biased gradients converge to critical points for smooth non-convex functions at a rate similar to existing results in the literature for the unbiased case. Finally, we provide experimental results using Variational Autoenconders (VAE) that illustrate our convergence results and show how the effect of bias can be reduced by appropriate hyperparameter tuning.
Online estimation of the inverse of the Hessian for stochastic optimization with application to universal stochastic Newton algorithms
Jan 15, 2024This paper addresses second-order stochastic optimization for estimating the minimizer of a convex function written as an expectation. A direct recursive estimation technique for the inverse Hessian matrix using a Robbins-Monro procedure is introduced. This approach enables to drastically reduces computational complexity. Above all, it allows to develop universal stochastic Newton methods and investigate the asymptotic efficiency of the proposed approach. This work so expands the application scope of secondorder algorithms in stochastic optimization.
Online stochastic Newton methods for estimating the geometric median and applications
Apr 03, 2023



In the context of large samples, a small number of individuals might spoil basic statistical indicators like the mean. It is difficult to detect automatically these atypical individuals, and an alternative strategy is using robust approaches. This paper focuses on estimating the geometric median of a random variable, which is a robust indicator of central tendency. In order to deal with large samples of data arriving sequentially, online stochastic Newton algorithms for estimating the geometric median are introduced and we give their rates of convergence. Since estimates of the median and those of the Hessian matrix can be recursively updated, we also determine confidences intervals of the median in any designated direction and perform online statistical tests.
Non asymptotic analysis of Adaptive stochastic gradient algorithms and applications
Mar 01, 2023In stochastic optimization, a common tool to deal sequentially with large sample is to consider the well-known stochastic gradient algorithm. Nevertheless, since the stepsequence is the same for each direction, this can lead to bad results in practice in case of ill-conditionned problem. To overcome this, adaptive gradient algorithms such that Adagrad or Stochastic Newton algorithms should be prefered. This paper is devoted to the non asymptotic analyis of these adaptive gradient algorithms for strongly convex objective. All the theoretical results will be adapted to linear regression and regularized generalized linear model for both Adagrad and Stochastic Newton algorithms.
Learning from time-dependent streaming data with online stochastic algorithms
May 25, 2022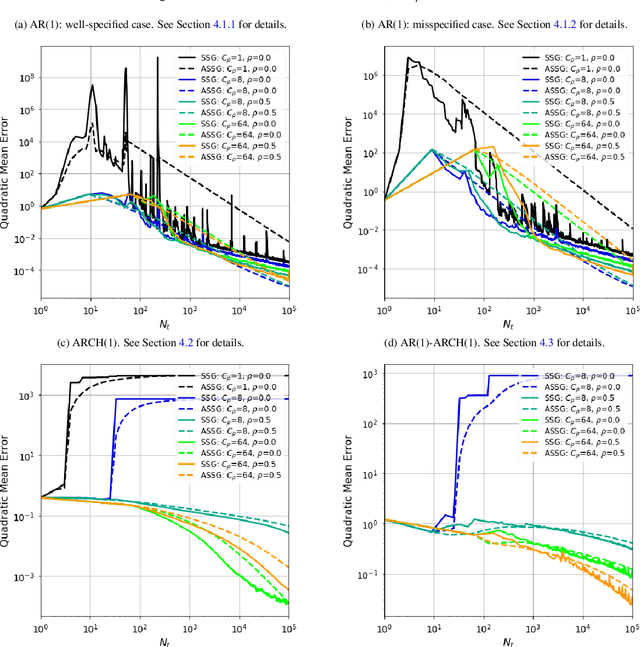
We study stochastic algorithms in a streaming framework, trained on samples coming from a dependent data source. In this streaming framework, we analyze the convergence of Stochastic Gradient (SG) methods in a non-asymptotic manner; this includes various SG methods such as the well-known stochastic gradient descent (i.e., Robbins-Monro algorithm), mini-batch SG methods, together with their averaged estimates (i.e., Polyak-Ruppert averaged). Our results form a heuristic by linking the level of dependency and convexity to the rest of the model parameters. This heuristic provides new insights into choosing the optimal learning rate, which can help increase the stability of SGbased methods; these investigations suggest large streaming batches with slow decaying learning rates for highly dependent data sources.