 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Forgetting and Stability of Score-based Generative models
Jan 29, 2026Understanding the stability and long-time behavior of generative models is a fundamental problem in modern machine learning. This paper provides quantitative bounds on the sampling error of score-based generative models by leveraging stability and forgetting properties of the Markov chain associated with the reverse-time dynamics. Under weak assumptions, we provide the two structural properties to ensure the propagation of initialization and discretization errors of the backward process: a Lyapunov drift condition and a Doeblin-type minorization condition. A practical consequence is quantitative stability of the sampling procedure, as the reverse diffusion dynamics induces a contraction mechanism along the sampling trajectory. Our results clarify the role of stochastic dynamics in score-based models and provide a principled framework for analyzing propagation of errors in such approaches.
Monte Carlo guided Diffusion for Bayesian linear inverse problems
Aug 15, 2023



Ill-posed linear inverse problems that combine knowledge of the forward measurement model with prior models arise frequently in various applications, from computational photography to medical imaging. Recent research has focused on solving these problems with score-based generative models (SGMs) that produce perceptually plausible images, especially in inpainting problems. In this study, we exploit the particular structure of the prior defined in the SGM to formulate recovery in a Bayesian framework as a Feynman--Kac model adapted from the forward diffusion model used to construct score-based diffusion. To solve this Feynman--Kac problem, we propose the use of Sequential Monte Carlo methods. The proposed algorithm, MCGdiff, is shown to be theoretically grounded and we provide numerical simulations showing that it outperforms competing baselines when dealing with ill-posed inverse problems.
State and parameter learning with PaRIS particle Gibbs
Jan 02, 2023Non-linear state-space models, also known as general hidden Markov models, are ubiquitous in statistical machine learning, being the most classical generative models for serial data and sequences in general. The particle-based, rapid incremental smoother PaRIS is a sequential Monte Carlo (SMC) technique allowing for efficient online approximation of expectations of additive functionals under the smoothing distribution in these models. Such expectations appear naturally in several learning contexts, such as likelihood estimation (MLE) and Markov score climbing (MSC). PARIS has linear computational complexity, limited memory requirements and comes with non-asymptotic bounds, convergence results and stability guarantees. Still, being based on self-normalised importance sampling, the PaRIS estimator is biased. Our first contribution is to design a novel additive smoothing algorithm, the Parisian particle Gibbs PPG sampler, which can be viewed as a PaRIS algorithm driven by conditional SMC moves, resulting in bias-reduced estimates of the targeted quantities. We substantiate the PPG algorithm with theoretical results, including new bounds on bias and variance as well as deviation inequalities. Our second contribution is to apply PPG in a learning framework, covering MLE and MSC as special examples. In this context, we establish, under standard assumptions, non-asymptotic bounds highlighting the value of bias reduction and the implicit Rao--Blackwellization of PPG. These are the first non-asymptotic results of this kind in this setting. We illustrate our theoretical results with numerical experiments supporting our claims.
BR-SNIS: Bias Reduced Self-Normalized Importance Sampling
Jul 13, 2022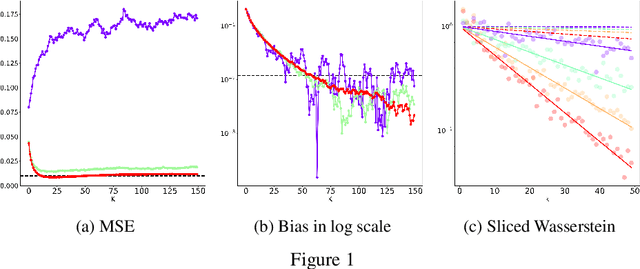



Importance Sampling (IS) is a method for approximating expectations under a target distribution using independent samples from a proposal distribution and the associated importance weights. In many applications, the target distribution is known only up to a normalization constant, in which case self-normalized IS (SNIS) can be used. While the use of self-normalization can have a positive effect on the dispersion of the estimator, it introduces bias. In this work, we propose a new method, BR-SNIS, whose complexity is essentially the same as that of SNIS and which significantly reduces bias without increasing the variance. This method is a wrapper in the sense that it uses the same proposal samples and importance weights as SNIS, but makes clever use of iterated sampling--importance resampling (ISIR) to form a bias-reduced version of the estimator. We furnish the proposed algorithm with rigorous theoretical results, including new bias, variance and high-probability bounds, and these are illustrated by numerical examples.