 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Probabilistic Trajectory Forecasting with Admissibility Constraints
Feb 07, 2023Predicting multiple trajectories for road users is important for automated driving systems: ego-vehicle motion planning indeed requires a clear view of the possible motions of the surrounding agents. However, the generative models used for multiple-trajectory forecasting suffer from a lack of diversity in their proposals. To avoid this form of collapse, we propose a novel method for structured prediction of diverse trajectories. To this end, we complement an underlying pretrained generative model with a diversity component, based on a determinantal point process (DPP). We balance and structure this diversity with the inclusion of knowledge-based quality constraints, independent from the underlying generative model. We combine these two novel components with a gating operation, ensuring that the predictions are both diverse and within the drivable area. We demonstrate on the nuScenes driving dataset the relevance of our compound approach, which yields significant improvements in the diversity and the quality of the generated trajectories.
OMNIA Faster R-CNN: Detection in the wild through dataset merging and soft distillation
Dec 06, 2018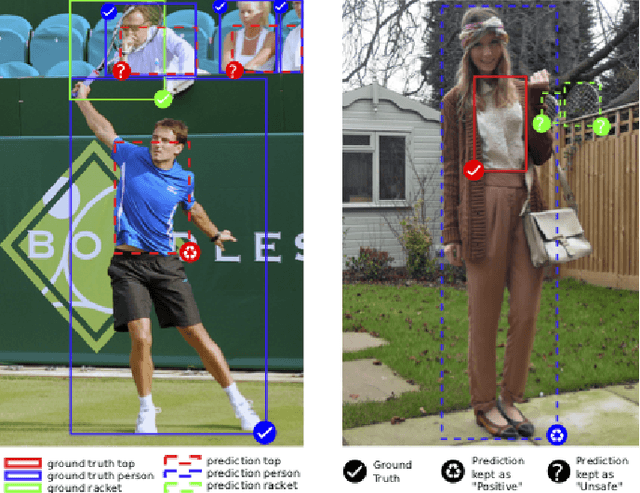

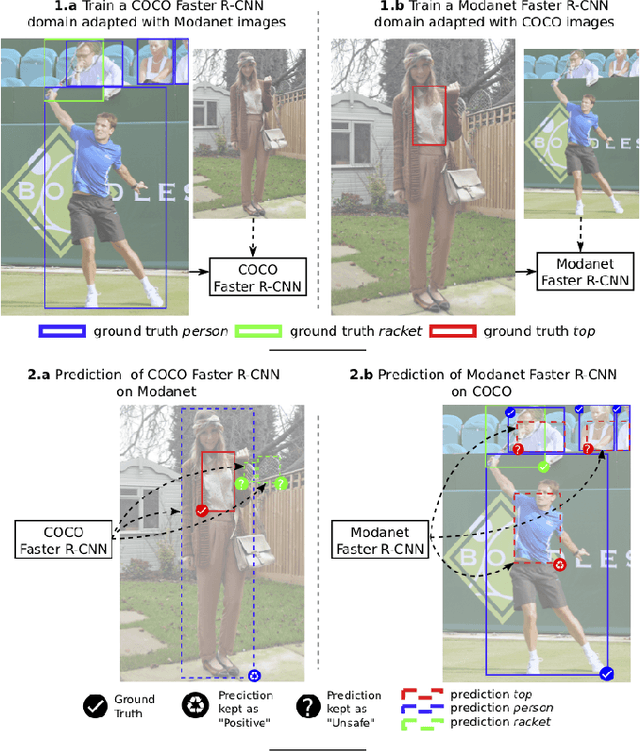

Object detectors tend to perform poorly in new or open domains, and require exhaustive yet costly annotations from fully labeled datasets. We aim at benefiting from several datasets with different categories but without additional labelling, not only to increase the number of categories detected, but also to take advantage from transfer learning and to enhance domain independence. Our dataset merging procedure starts with training several initial Faster R-CNN on the different datasets while considering the complementary datasets' images for domain adaptation. Similarly to self-training methods, the predictions of these initial detectors mitigate the missing annotations on the complementary datasets. The final OMNIA Faster R-CNN is trained with all categories on the union of the datasets enriched by predictions. The joint training handles unsafe targets with a new classification loss called SoftSig in a softly supervised way. Experimental results show that in the case of fashion detection for images in the wild, merging Modanet with COCO increases the final performance from 45.5% to 57.4%. Applying our soft distillation to the task of detection with domain shift on Cityscapes enables to beat the state-of-the-art by 5.3 points. We hope that our methodology could unlock object detection for real-world applications without immense datasets.
Leveraging Weakly Annotated Data for Fashion Image Retrieval and Label Prediction
Sep 27, 2017

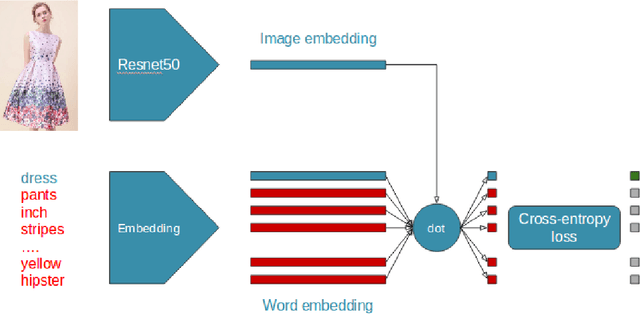

In this paper, we present a method to learn a visual representation adapted for e-commerce products. Based on weakly supervised learning, our model learns from noisy datasets crawled on e-commerce website catalogs and does not require any manual labeling. We show that our representation can be used for downward classification tasks over clothing categories with different levels of granularity. We also demonstrate that the learnt representation is suitable for image retrieval. We achieve nearly state-of-art results on the DeepFashion In-Shop Clothes Retrieval and Categories Attributes Prediction tasks, without using the provided training set.