 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Ensemble for Variance Dependent Regret in Stochastic Bandits
Sep 13, 2024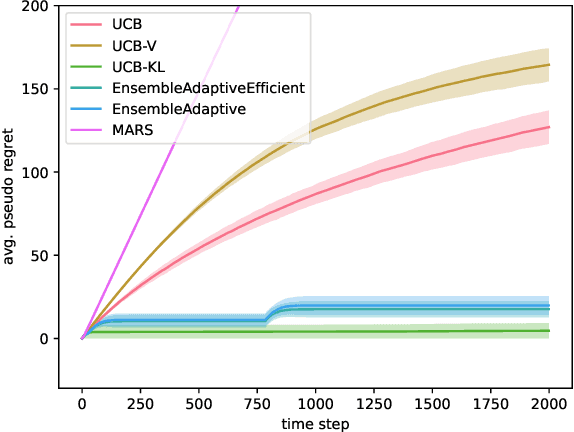
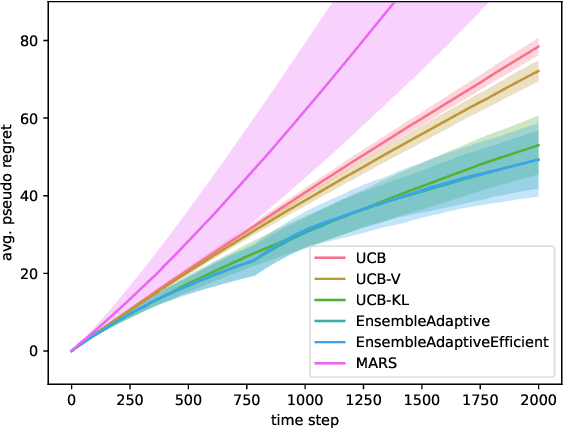
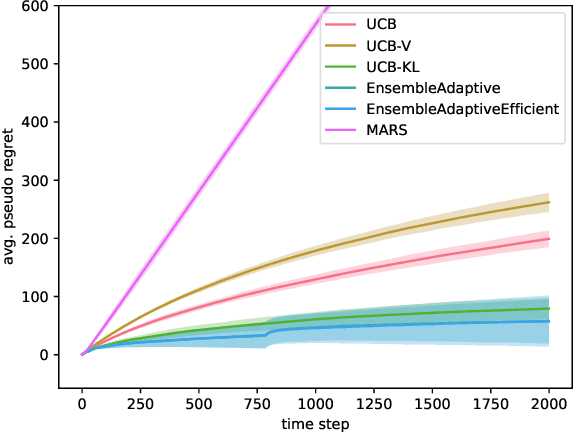
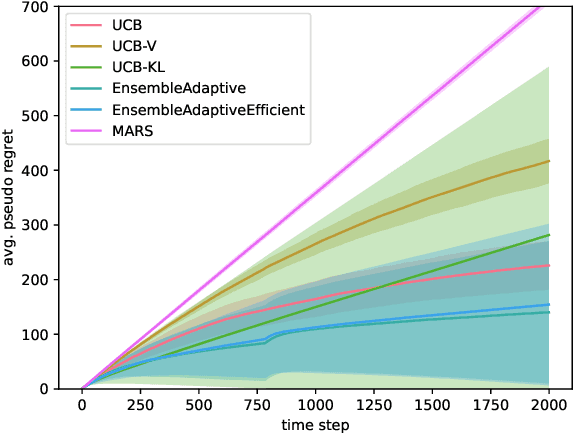
Efficiently trading off exploration and exploitation is one of the key challenges in online Reinforcement Learning (RL). Most works achieve this by carefully estimating the model uncertainty and following the so-called optimistic model. Inspired by practical ensemble methods, in this work we propose a simple and novel batch ensemble scheme that provably achieves near-optimal regret for stochastic Multi-Armed Bandits (MAB). Crucially, our algorithm has just a single parameter, namely the number of batches, and its value does not depend on distributional properties such as the scale and variance of the losses. We complement our theoretical results by demonstrating the effectiveness of our algorithm on synthetic benchmarks.
Warm-up Free Policy Optimization: Improved Regret in Linear Markov Decision Processes
Jul 03, 2024Policy Optimization (PO) methods are among the most popular Reinforcement Learning (RL) algorithms in practice. Recently, Sherman et al. [2023a] proposed a PO-based algorithm with rate-optimal regret guarantees under the linear Markov Decision Process (MDP) model. However, their algorithm relies on a costly pure exploration warm-up phase that is hard to implement in practice. This paper eliminates this undesired warm-up phase, replacing it with a simple and efficient contraction mechanism. Our PO algorithm achieves rate-optimal regret with improved dependence on the other parameters of the problem (horizon and function approximation dimension) in two fundamental settings: adversarial losses with full-information feedback and stochastic losses with bandit feedback.
Multi-turn Reinforcement Learning from Preference Human Feedback
May 23, 2024



Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Near-Optimal Regret in Linear MDPs with Aggregate Bandit Feedback
May 14, 2024In many real-world applications, it is hard to provide a reward signal in each step of a Reinforcement Learning (RL) process and more natural to give feedback when an episode ends. To this end, we study the recently proposed model of RL with Aggregate Bandit Feedback (RL-ABF), where the agent only observes the sum of rewards at the end of an episode instead of each reward individually. Prior work studied RL-ABF only in tabular settings, where the number of states is assumed to be small. In this paper, we extend ABF to linear function approximation and develop two efficient algorithms with near-optimal regret guarantees: a value-based optimistic algorithm built on a new randomization technique with a Q-functions ensemble, and a policy optimization algorithm that uses a novel hedging scheme over the ensemble.
Efficient Rate Optimal Regret for Adversarial Contextual MDPs Using Online Function Approximation
Mar 02, 2023We present the OMG-CMDP! algorithm for regret minimization in adversarial Contextual MDPs. The algorithm operates under the minimal assumptions of realizable function class and access to online least squares and log loss regression oracles. Our algorithm is efficient (assuming efficient online regression oracles), simple and robust to approximation errors. It enjoys an $\widetilde{O}(H^{2.5} \sqrt{ T|S||A| ( \mathcal{R}(\mathcal{O}) + H \log(\delta^{-1}) )})$ regret guarantee, with $T$ being the number of episodes, $S$ the state space, $A$ the action space, $H$ the horizon and $\mathcal{R}(\mathcal{O}) = \mathcal{R}(\mathcal{O}_{\mathrm{sq}}^\mathcal{F}) + \mathcal{R}(\mathcal{O}_{\mathrm{log}}^\mathcal{P})$ is the sum of the regression oracles' regret, used to approximate the context-dependent rewards and dynamics, respectively. To the best of our knowledge, our algorithm is the first efficient rate optimal regret minimization algorithm for adversarial CMDPs that operates under the minimal standard assumption of online function approximation.
Counterfactual Optimism: Rate Optimal Regret for Stochastic Contextual MDPs
Nov 27, 2022We present the UC$^3$RL algorithm for regret minimization in Stochastic Contextual MDPs (CMDPs). The algorithm operates under the minimal assumptions of realizable function class, and access to offline least squares and log loss regression oracles. Our algorithm is efficient (assuming efficient offline regression oracles) and enjoys an $\widetilde{O}(H^3 \sqrt{T |S| |A|(\log (|\mathcal{F}|/\delta) + \log (|\mathcal{P}|/ \delta) )})$ regret guarantee, with $T$ being the number of episodes, $S$ the state space, $A$ the action space, $H$ the horizon, and $\mathcal{P}$ and $\mathcal{F}$ are finite function classes, used to approximate the context-dependent dynamics and rewards, respectively. To the best of our knowledge, our algorithm is the first efficient and rate-optimal regret minimization algorithm for CMDPs, which operates under the general offline function approximation setting.
Rate-Optimal Online Convex Optimization in Adaptive Linear Control
Jun 03, 2022We consider the problem of controlling an unknown linear dynamical system under adversarially changing convex costs and full feedback of both the state and cost function. We present the first computationally-efficient algorithm that attains an optimal $\smash{\sqrt{T}}$-regret rate compared to the best stabilizing linear controller in hindsight, while avoiding stringent assumptions on the costs such as strong convexity. Our approach is based on a careful design of non-convex lower confidence bounds for the online costs, and uses a novel technique for computationally-efficient regret minimization of these bounds that leverages their particular non-convex structure.
Efficient Online Linear Control with Stochastic Convex Costs and Unknown Dynamics
Mar 02, 2022We consider the problem of controlling an unknown linear dynamical system under a stochastic convex cost and full feedback of both the state and cost function. We present a computationally efficient algorithm that attains an optimal $\sqrt{T}$ regret-rate against the best stabilizing linear controller. In contrast to previous work, our algorithm is based on the Optimism in the Face of Uncertainty paradigm. This results in a substantially improved computational complexity and a simpler analysis.
Online Policy Gradient for Model Free Learning of Linear Quadratic Regulators with $\sqrt{T}$ Regret
Feb 25, 2021We consider the task of learning to control a linear dynamical system under fixed quadratic costs, known as the Linear Quadratic Regulator (LQR) problem. While model-free approaches are often favorable in practice, thus far only model-based methods, which rely on costly system identification, have been shown to achieve regret that scales with the optimal dependence on the time horizon T. We present the first model-free algorithm that achieves similar regret guarantees. Our method relies on an efficient policy gradient scheme, and a novel and tighter analysis of the cost of exploration in policy space in this setting.
Bandit Linear Control
Jul 01, 2020We consider the problem of controlling a known linear dynamical system under stochastic noise, adversarially chosen costs, and bandit feedback. Unlike the full feedback setting where the entire cost function is revealed after each decision, here only the cost incurred by the learner is observed. We present a new and efficient algorithm that, for strongly convex and smooth costs, obtains regret that grows with the square root of the time horizon $T$. We also give extensions of this result to general convex, possibly non-smooth costs, and to non-stochastic system noise. A key component of our algorithm is a new technique for addressing bandit optimization of loss functions with memory.