 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Anomaly Detection and Diagnosis in Multivariate Time Series
Sep 23, 2021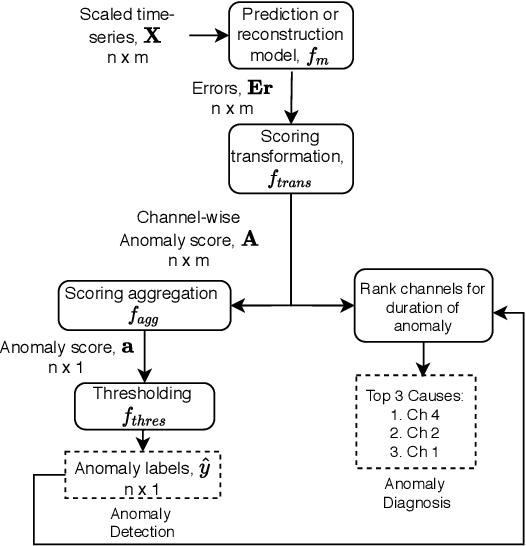
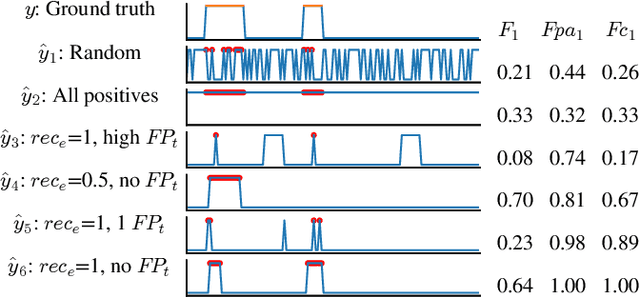
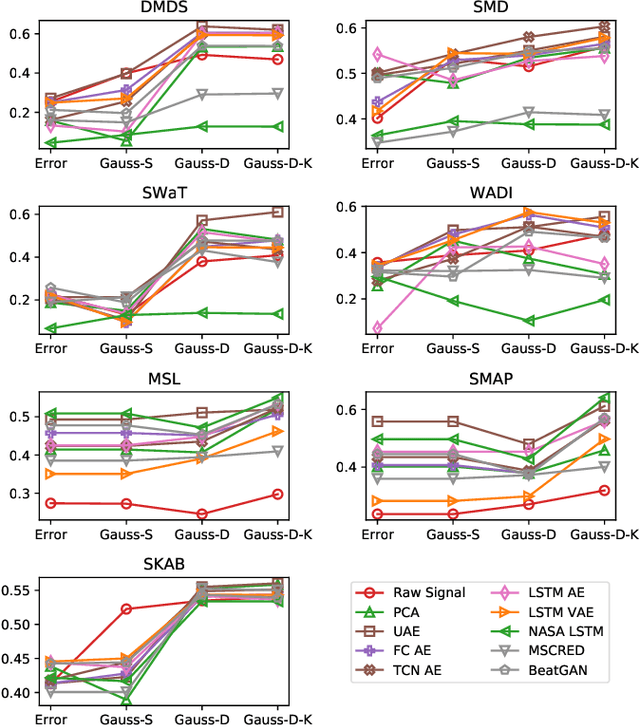
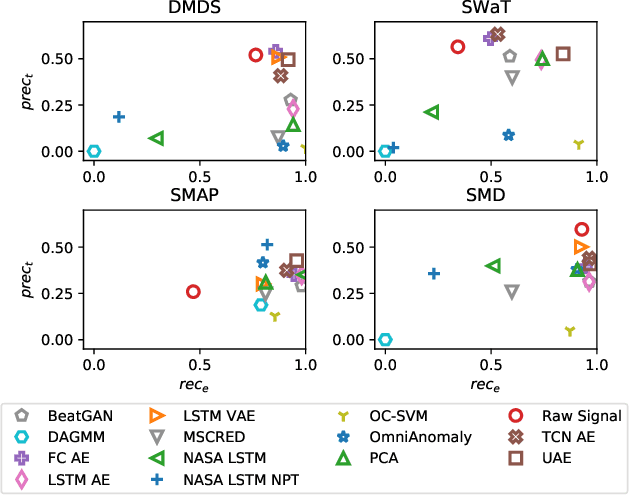
Several techniques for multivariate time series anomaly detection have been proposed recently, but a systematic comparison on a common set of datasets and metrics is lacking. This paper presents a systematic and comprehensive evaluation of unsupervised and semi-supervised deep-learning based methods for anomaly detection and diagnosis on multivariate time series data from cyberphysical systems. Unlike previous works, we vary the model and post-processing of model errors, i.e. the scoring functions independently of each other, through a grid of 10 models and 4 scoring functions, comparing these variants to state of the art methods. In time-series anomaly detection, detecting anomalous events is more important than detecting individual anomalous time-points. Through experiments, we find that the existing evaluation metrics either do not take events into account, or cannot distinguish between a good detector and trivial detectors, such as a random or an all-positive detector. We propose a new metric to overcome these drawbacks, namely, the composite F-score ($Fc_1$), for evaluating time-series anomaly detection. Our study highlights that dynamic scoring functions work much better than static ones for multivariate time series anomaly detection, and the choice of scoring functions often matters more than the choice of the underlying model. We also find that a simple, channel-wise model - the Univariate Fully-Connected Auto-Encoder, with the dynamic Gaussian scoring function emerges as a winning candidate for both anomaly detection and diagnosis, beating state of the art algorithms.
What Users Want? WARHOL: A Generative Model for Recommendation
Sep 02, 2021


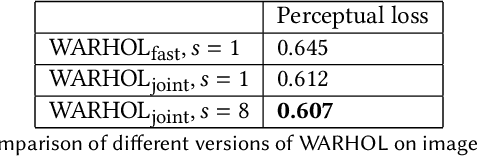
Current recommendation approaches help online merchants predict, for each visiting user, which subset of their existing products is the most relevant. However, besides being interested in matching users with existing products, merchants are also interested in understanding their users' underlying preferences. This could indeed help them produce or acquire better matching products in the future. We argue that existing recommendation models cannot directly be used to predict the optimal combination of features that will make new products serve better the needs of the target audience. To tackle this, we turn to generative models, which allow us to learn explicitly distributions over product feature combinations both in text and visual space. We develop WARHOL, a product generation and recommendation architecture that takes as input past user shopping activity and generates relevant textual and visual descriptions of novel products. We show that WARHOL can approach the performance of state-of-the-art recommendation models, while being able to generate entirely new products that are relevant to the given user profiles.
A joint model of unpaired data from scRNA-seq and spatial transcriptomics for imputing missing gene expression measurements
May 06, 2019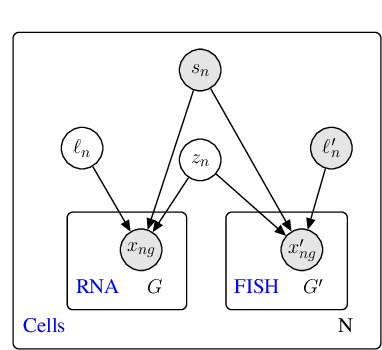
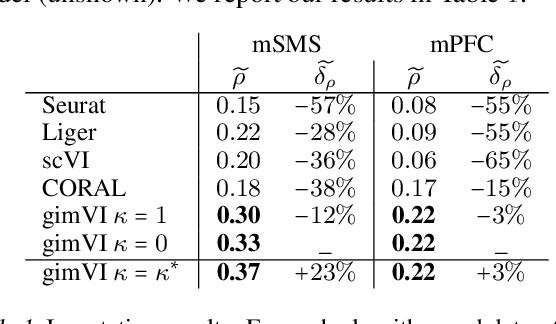
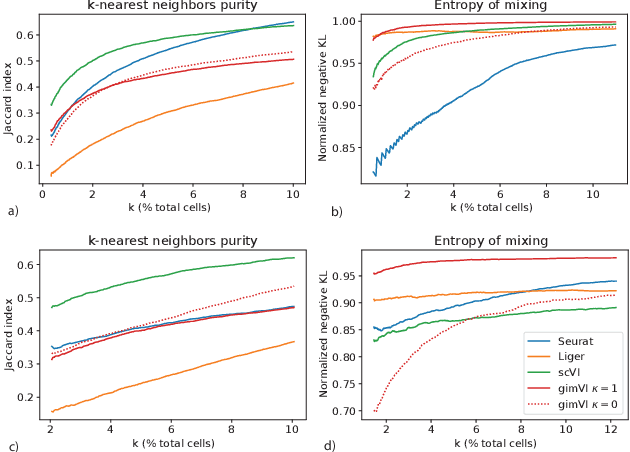
Spatial studies of transcriptome provide biologists with gene expression maps of heterogeneous and complex tissues. However, most experimental protocols for spatial transcriptomics suffer from the need to select beforehand a small fraction of genes to be quantified over the entire transcriptome. Standard single-cell RNA sequencing (scRNA-seq) is more prevalent, easier to implement and can in principle capture any gene but cannot recover the spatial location of the cells. In this manuscript, we focus on the problem of imputation of missing genes in spatial transcriptomic data based on (unpaired) standard scRNA-seq data from the same biological tissue. Building upon domain adaptation work, we propose gimVI, a deep generative model for the integration of spatial transcriptomic data and scRNA-seq data that can be used to impute missing genes. After describing our generative model and an inference procedure for it, we compare gimVI to alternative methods from computational biology or domain adaptation on real datasets and outperform Seurat Anchors, Liger and CORAL to impute held-out genes.